

Duplicate data is frequently found in relational databases and they are usually a hurdle that needs to be fixed. This article will discuss several methods for removing duplicates in SQL. We will learn about situations such as eliminating duplicates, managing the deletion of duplicate rows while preserving one instance, and addressing scenarios where the goal is to retain only the most recent duplicates.
What are the Duplicates in SQL?
Before diving into the details, let us clarify what we mean by duplicate rows in a database. Duplicate rows are entries that share identical values in one or more columns. When we say rows are duplicates, it simply means that some or all of the information in certain columns of one row is the same as another row.
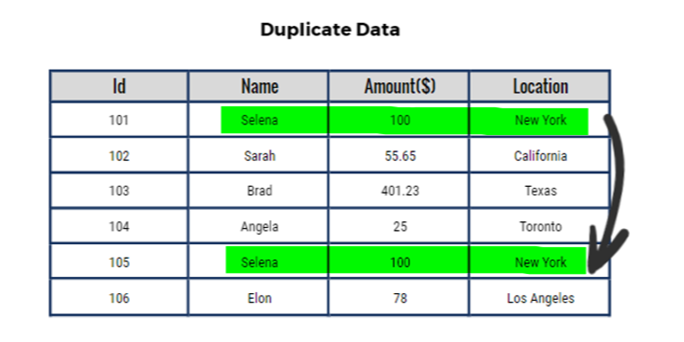
Imagine we have a table where each row represents something, like a transaction or a person. Duplicate rows occur when the information in one or more columns of one row is identical to another row in the same table. So, if two rows have the same values in specific columns, we consider them duplicates.
Let us see another example of a transactions table with duplicate data in SQL:
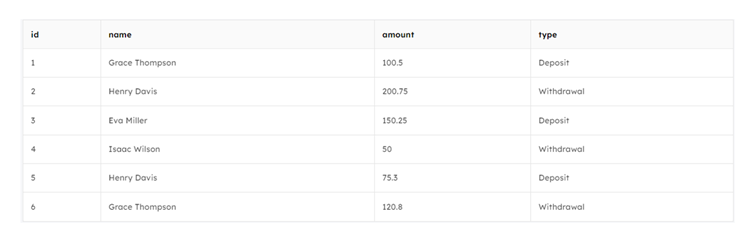
In this transactions table, we can observe duplicate values with the names "Grace Thompson" and “Henry Davis” occurring at multiple IDs. Such redundancy can have implications for optimizing the data.
Why should Duplicate Values be Avoided in SQL?
Avoiding duplicate values in SQL database tables is crucial for several reasons:
- Duplicate values can make it difficult to determine the correct or most recent information, leading to inaccuracies in our data.
- Retrieving information becomes slower and less efficient when duplicates are present, affecting the speed of SQL queries.
- Duplicates consume extra storage space, impacting overall system performance and efficiency, especially in large databases.
- Duplicates often result from data entry errors. By avoiding duplicates, we reduce the risk of introducing errors during data input.
3 Ways to Remove Duplicates in SQL
Now, let us explore various methods to get rid of duplicate records from your dataset. We will discuss dealing with repeated values in a SELECT query, deleting duplicate rows while keeping one instance intact, and managing situations where only the most duplicates should be retained.
Let us dive into effective techniques to remove duplicates in SQL and make our database a clean one. We will take the same above example.
1) Using DISTINCT Statement in SELECT
The DISTINCT statement in SQL allows us to retrieve unique values from a specified column or set of columns. We will now explore how to apply this in a SELECT statement to eliminate duplicate values. Here is the code to do it:
SELECT DISTINCT column1, column2, ... FROM table_name; SQL Query: SELECT DISTINCT name FROM transactions;
Output:
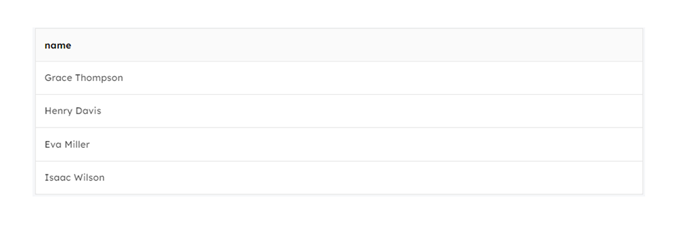
Here the output table represents all the unique values of the name column.
2) Using GROUP BY AND COUNT
Using GROUP BY and COUNT() in SQL helps us to identify and count duplicate values in a table. When we group rows by a specific column (e.g., name), the COUNT(*) function calculates the number of occurrences for each unique value in that column. The HAVING clause is then employed to filter the results and retain only those groups where the count is greater than 1, indicating the presence of duplicate entries.
Below is the syntax to do it:
SELECT column_name, COUNT(*) AS count_name FROM table_name GROUP BY column_name HAVING COUNT(*) > n(number of repetitions); SQL Query: SELECT name, COUNT(*) AS occurrence FROM transactions GROUP BY name HAVING COUNT(*) > 1;
Output:

In the above table, it is evident that the names "Grace Thompson" and "Henry Davis" appear more than once.
3) Using JOINS
Using joins in SQL to detect duplicates involves combining information from multiple tables based on a common column. By linking tables through a join, we can compare and match data between them. Let's see an example:
SELECT table_name.column_name FROM table t1 INNER JOIN table t2 ON t1.name = t2.name AND t1.id <> t2.id ORDER by t1.name asc;
Here, we are using a self-inner join, which means we are comparing the table with itself. This helps us pinpoint and separate out any duplicate values present in the table. This approach is like putting a spotlight on repeated information, making it easier to identify and manage in our dataset.
SQL Query: SELECT t1.name FROM transactions t1 JOIN transactions t2 ON t1.name = t2.name AND t1.id <> t2.id ORDER by t1.name asc;
Output:
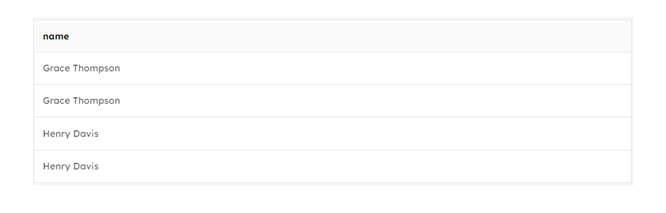
The above output represents all the names of the duplicate IDs present in the table.
Delete Duplicate Rows in SQL While Keeping One Row
To delete duplicate rows while retaining one instance in SQL, we can use a combination of the DELETE statement and a subquery to identify the duplicates. Here's an example:
SQL Query: DELETE FROM transactions WHERE id NOT IN ( SELECT MIN(id) FROM transactions GROUP BY name ); SELECT * FROM transactions;
Output:
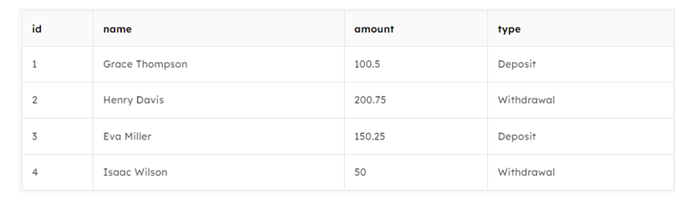
This SQL query removes duplicate rows from the TransactionTable, ensuring that only one instance remains for each unique name. The query identifies the minimum transaction ID (id) for each name using a subquery and then deletes rows from the main table where the ID is not the minimum within each group.
This process optimizes the data by retaining the earliest transaction for names with multiple entries and organizing the dataset.
In the above case, we have used min(id) to choose the row with the lowest or least recent id.
Remove Duplicate Rows While Keeping the most recent Row
Removing duplicate rows while keeping the most recent ones is essential for keeping data accurate. In simple terms, it involves using SQL tricks to find and filter out duplicates based on a timestamp or unique ID.
SQL Query: DELETE FROM transactions WHERE id NOT IN ( SELECT MAX(id) FROM transactions GROUP BY name ); SELECT * FROM transactions;
Output:
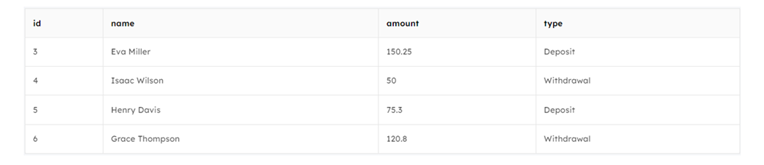
Similarly in this scenario, employing MAX(id) means choosing the row with the highest or most recent id. It helps us to identify and keep the entry that corresponds to the latest transaction or activity in the dataset.
Conclusion
In conclusion, we have checked out some SQL techniques to find and remove duplicates in our data. From the straightforward DISTINCT to GROUP BY and JOINS, SQL offers a complete manipulation toolkit. It is all about choosing the right method that fits our data and keeping things smooth and accurate. Did you get a similar question in your homework? Then, check out SQL assignment help now.





