
In this article, we will study what is hashing and why working with hashing data structure is easy compared to other data structures. We will start with what is a hash function and what is a collision in hashing including the negative indexing of hash keys. And at last, we will learn some of the frequently asked problem statement which can be solved using hashing technique to find an optimal solution along with its python code and output. So, let's get started!
Introduction to Hashing
Before starting to understand what is hashing, let us go through one example. Suppose we want to design a system to store the student records with some of their information like roll number, name, class name, section, and parents’ names. And we want the following queries to be performed on the system:
- Insert the roll number and corresponding information
- Search the roll number and corresponding information
- Delete the roll number and corresponding information
Now the above system can be successfully developed using
- An array of roll number and corresponding information
- Linked-List of roll number and corresponding information
- Hash Table of roll number and corresponding information
Now, if we create the above system using an array or linked-list, we need to search in the linear manner, which is high maintenance practically. For example, using array data structure the insertion time complexity is constant i.e O(1), but the search time complexity and deletion time complexity is O(N) which is big for N number of entries. Similarly, using Linked-List data structure, the insertion, searching and deletion time complexity is O(N) for N number of entries which is not quite feasible. Therefore, hashing is used as a solution that can be utilized in almost all such situations and perform well compared to other data structures. Using hashing we get the time complexity for insertion, searching and deletion as O(1) in average and O(N) in worst time complexity.
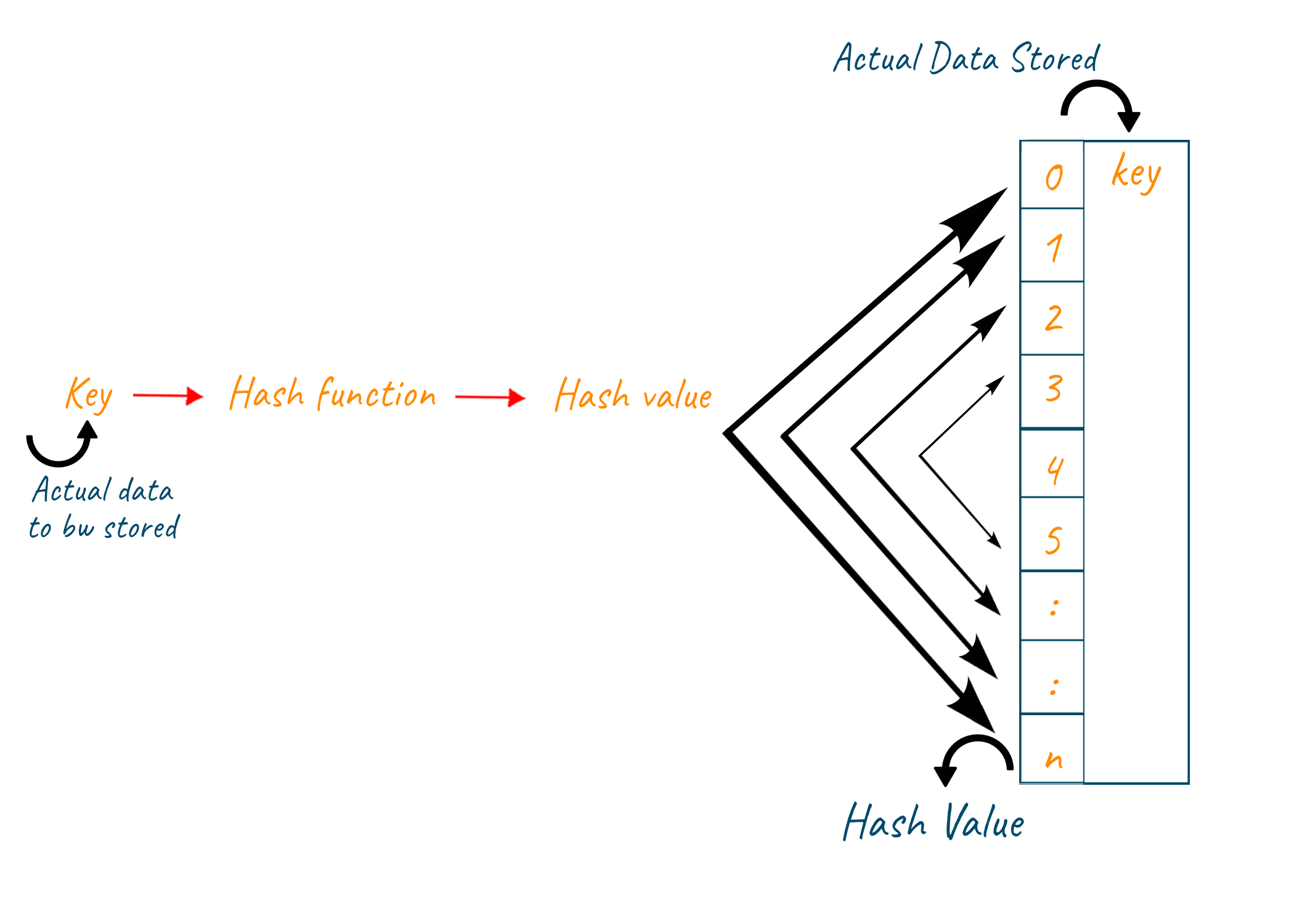
So, using the hash function we can convert the roll number into a key and use this key as an index in the table called a hash table. Hash Table is a data structure that stores the key-value pair. Each value is assigned to a key which is created using the hash function. This hash table stores values as student information for corresponding roll numbers as keys. The entry in the hash table is “null” if the key does not have its corresponding information.
Now let us understand how we can convert the entire system into code:
s1 = [1, 'A', 11, 'c', 'f1', 'm1'] s2 = [2, 'B', 12, 'c', 'f2', 'm2'] s3 = [3, 'C', 10, 'b', 'f3', 'm3'] hashTable = [None for _ in range(101)] def insert(s): rollNo = s[0] hashTable[rollNo] = s[1:] return def search(s): rollNo = s[0] if hashTable[rollNo] is None: return False return hashTable[rollNo] def delete(s): rollNo = s[0] hashTable[rollNo] = None return insert(s1) insert(s2) insert(s3) print(search(s2)) print(search(s3)) delete(s1) print(search(s1))
Hash Function and Collision
Now, above we assumed that the roll numbers of the student were already small in size so we can directly consider them as the key value. But what if they are not of small size? In such scenarios, we can use the hash function to covert the big number or a string into a small integer that can be used as a key in the hash table. These values which are returned by the hash function are called hash values. Many hash functions can be generated for any given circumstances but for creating an effective hash function following qualities should be fulfilled:
- The hash function should be easy to compute and it should not be an algorithm in itself.
- Every hash function should be able to generate unique hash values
- The hash function should create the minimum number of collisions.
- There should be a uniform distribution of the hash values among the entire hash table.
Index mapping with negative allowed
Consider the limited range array contains both positive and negative integer numbers i.e from the range [-Max, Max]. Our job is to search if such a number is present in an array using O(1) time. Here we have limited the range therefore we can use index mapping. We use these values in the index as a big array. Hence, we can insert and search the elements in O(1) time.
Now, for the negative indexing, we will shift all the negative keys to the positive keys by calculating the difference between the maximum and the minimum range. Therefore, the formula for the shift will be:
Limit = Max – [-Max] + 1
This, limit is added to all the negative keys to shift them towards the positive keys and similarly is done with the positive keys to shift them further to maintain the difference between the keys.
Collision Handling
As we know that hash function generates small hash values which can be used as keys in the hash table. But many times, same hash values are generated for different inputs in the hash function. This condition leads to a collision. The process handling key generated by hash function pointing to already occupied key in table is called collision handling technique. We can handle collision using the following collision handling technique:
- Open Addressing: When all the elements are stored in the hash table itself it is an open addressing process. Here we create the records in the form of the array itself. While using this method, if we find that the slot for storing the value is already occupied, then we simply move on further in the table and find the empty slot to store the value.
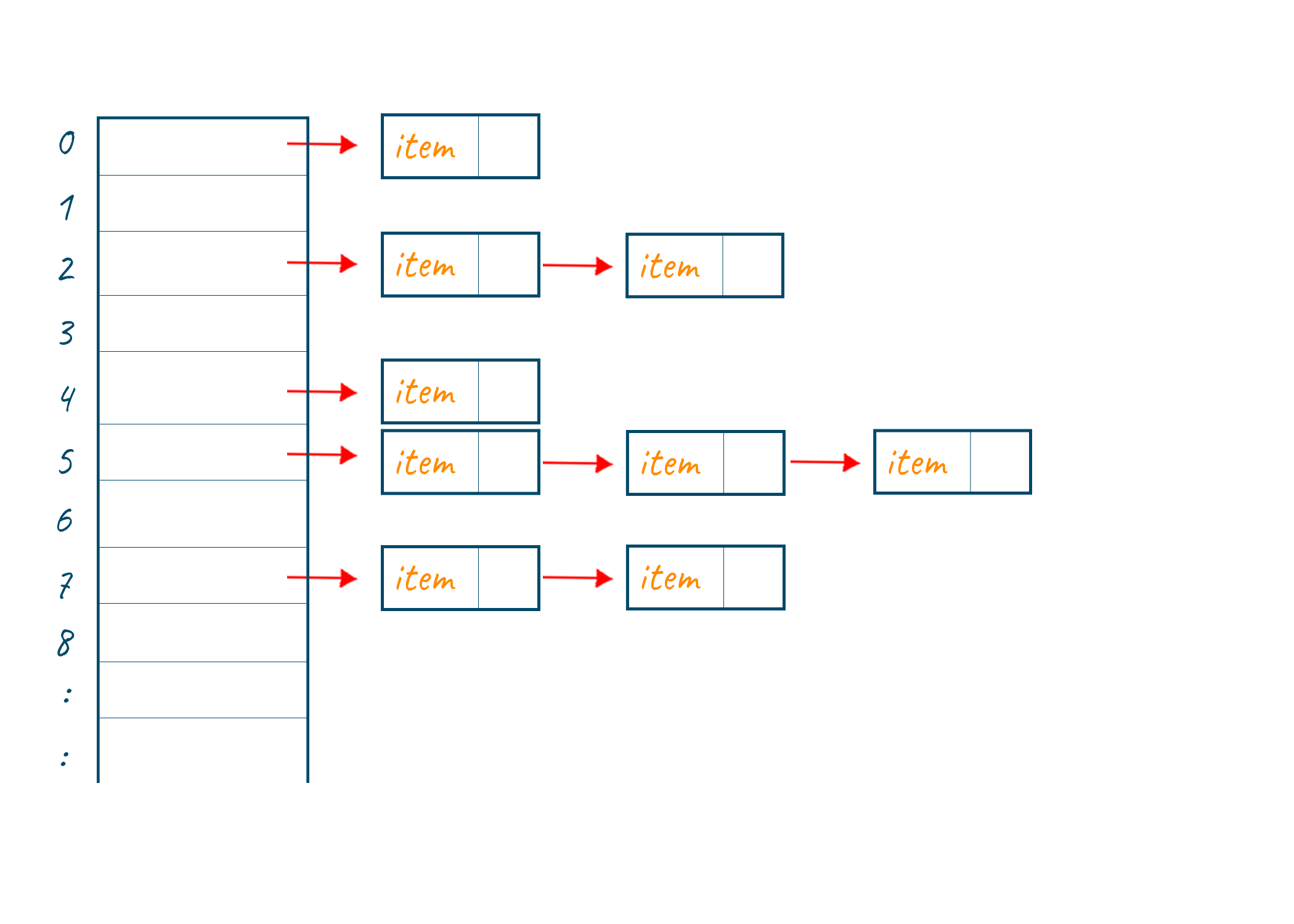
- Chaining: It is the most commonly used collision technique. Here we make every cell of the hash table point to the linked list of the values that have the same hash function value. Now if a collision occurs then we store both the values in the same linked list. As chaining is a simple process, but it requires additional memory outside the table for creating the linked list. But it can easily accommodate a large number of value if large space is available. Also, the time complexity of inserting data using the chaining technique is O(1) hence, gives better performance in comparison to other collision handling techniques.
How Hashing used to solve problems?
There are many problem statements available that can be solved using various techniques and methods. But solving such problem statements using hashing techniques gives us the best optimal solution possible. All such problem statements are frequently asked in coding interviews and it is very necessary to learn them briefly.Below are some such problems solved using hashing techniques.
Count of Elements in an Array
Problem Statement: We are given the integer array and we have to count the frequency of each element in the array.
We can solve this problem using the brute force approach i.e we can use the loop and increase the count of the element as its frequency increases. But using this approach the time complexity will be O(N2) and space complexity will be O(1) for an array of size N which is not optimal. Therefore we will use hashing technique to solve the above problem.
Using hashing technique we will create the hash map where the key will be the integer number itself and the value will be the frequency of occurrence of the element in the array. Now, we will trace each element of the array and if the element is repeated we will increase its occurrence by +1.
For example:
nums = [10, 25, 10, 15, 2, 15, 15, 2, 10]
key/element value/frequency
10 1 2 3
25 1
15 1 2 3
2 1 2
Output: [10-3, 25-1, 15-3, 2-2]
The time complexity of the above method is O(N) and the space complexity is also O(N) for an array of size N.
The code for the above problem statement is as given below:
def countElements(arr): memo = {} for currentVal in arr: if currentVal in memo: memo[currentVal] = memo[currentVal] + 1 else: memo[currentVal] = 1 for key in memo.keys(): print(key, memo[key]) return arr = [10, 20, 15, 20, 10, 20, 10] countElements(arr)
The output of the above code is:
10 3
20 3
15 1
Count distinct element in the array
Problem statement: We are given the integer array and we have to count the distinct elements in the array.
We can solve this problem using the brute force approach by running the loop over the array and then increase our answer variable by 1 when we discover the distinct element. But by using loops the time complexity of the method will be O(N2), where the size of the array is N and space complexity is O(1). This solution is not feasible and therefore we can use the hashing technique to find an optimal solution.
Now using hashing, we will create the hash map where the key will be the integer element of the array itself and the value will be the occurrence frequency of the element in the array. When the element frequency is increased, we will increase the corresponding value by 1. At last, we will run a loop over the hash map and the key having the value as 1 will be the distinct element of our array.
For example:
nums = [10, 20, 30, 15, 5, 20, 10]
key/element value/frequency
10 1 2
20 1 2
30 1
15 1
5 1
Output: [30, 15, 5]
The time complexity of the above method is O(N) and the space complexity is also O(N) for an array of size N.
The code for the above problem statement is as given below:
def countDistinct(nums): memo = {} answer = 0 for currentVal in nums: if currentVal in memo: memo[currentVal] = memo[currentVal] + 1 else: memo[currentVal] = 1 for key in memo.keys(): if memo[key] == 1: answer += 1 return answer nums = [10, 20, 30, 5, 15, 20, 10] print(countDistinct(nums))
The output of the above code is:
3
Finding Anagrams
Finding an anagram of the strings is another useful example of applying the hashing technique.
Problem Statement: Given two strings s and t, return true if t is an anagram of s, and false otherwise.
There are two conditions to check while proving two strings as an anagram of one other. They are as below:
- Length of both the string should be same
- The occurrence of every character should be the same in both strings
We can use the brute force approach to solve this problem by calculating the length of both the strings first and then we will run the loop to check the occurrence of every character in both the string. But the time complexity of this approach is O(N2), where N is the length of the string and space complexity is O(1). This solution is not feasible and therefore we can use the hashing technique to find an optimal solution.
Now using hashing technique, we will create a hash map of the string s where the characters of the string will be the key and its frequency will be its corresponding value. After the successful creation of the hashmap, we will trace each character of string t and reduce the frequency of the corresponding character by 1 from the hashmap. After tracing each character of string t if we find our hash map to be empty then string t is anagram if string s and if the hashmap is not empty then it is false.
For Example:
s = “anagram”
t = “nagaram”
key/characters value/freqyency
a 1 2 3 2 1 0
n 1 0
g 1 0
r 1 0
m 1 0
Output: True
The time complexity of the above method is O(N) and the space complexity is also O(1) for an array of size N.
The code for the above problem statement is as given below:
def checkAnagrams(s, t): if len(s) != len(t): return False memo = {} for currentChar in s: if currentChar in memo: memo[currentChar] += 1 else: memo[currentChar] = 1 for currentChar in t: if currentChar not in memo: return False memo[currentChar] -= 1 if memo[currentChar] == 0: del memo[currentChar] return True s = 'anagram' t = 'nagaram' print(checkAnagrams(s, t))
The output of the above code is:
True
So, above were some of the common problem statements that are usually asked in coding interviews for finding an optimal solution. There are many such problem statements discussed in detail with python code and examples on the online course Data Structure and Algorithm Hashing.
Conclusion
Hence in the above article, we studied what is hashing as a data structure and how it is better to use. Along with that we also learned the collision technique and negative indexing in hashing. Also, we learned some of the problems solved using hashing techniques in detail with the python code and output.





