

Refining the available raw data to make it easier to obtain valuable insights from it is called data manipulation. Removing columns from a dataset is also one such technique. It is necessary in situations where some parts of the data are redundant, not needed, or may cause confusion. Let’s look at how to remove columns in R.
Identifying Columns to Remove in R
It is important to ensure that the columns you remove don’t cause a problem for your analysis process in the future. So how do you identify the right columns to remove? Here are the steps to do before removing a column:
- Assess the dataset: Explore the dataset using functions like head() to display the first few rows, summary() to get statistical summaries, and str() to view the structure of the dataset. These functions give you a snapshot of the data, revealing its dimensions and data types.
- Identify the unnecessary columns: While trying to identify unnecessary columns, look out for the following:
- Redundant columns
- Constant columns
- Highly correlated columns
- Columns irrelevant to the analysis task
- Consider the impact of column removal on analysis: After you’ve identified the unnecessary columns, analyze how removing them might affect the achievement of the analysis goal. Consider its impact on the integrity and reliability of the data. Confirm that what you are removing is noise and not essential information.
How to Remove Column in R?
Consider the following sample dataframe:
employee_data <- data.frame( ID = c(101, 102, 103), Name = c("Lana", "David", "Emma"), Age = c(30, 28, 35), Department = c("Marketing", "Finance", "HR"), Salary = c(60000, 75000, 65000) )
Now let’s consider the different methods to remove a column in R:
1) Remove Column by Index
An index is the numerical position of a column in the dataframe. Using indexes to remove columns is not a very common method as it is less readable and is prone to errors. Let’s see how we can do it:
# Removing the column at index 3 (Age) employee_data <- employee_data[, -3]
Output:

2) Using subset() with Negative Index
We can remove columns by using the concept of negative indexing along with the subset() function. This provides a convenient way to create subsets of the dataset. For Example:
# Removing the column at index 3 (Age) employee_data <- subset(employee_data, select = -3)
It gives the same output as above.
3) Drop Column by Name
Removing columns by column name is a better alternative because it is flexible, improves readability and maintainability, and is less prone to errors. We will use $ Operator. This is one of the most commonly used methods. It is simple, concise, and directly modifies the original dataframe.
Example:
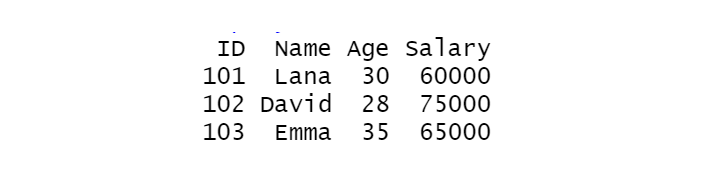
# Removing the 'Department' column employee_data$Department <- NULL
Output:
4) Using subset() Function
This function is more commonly used with column names than indexes. For Example:
# Removing the 'Department' column employee_data <- subset(employee_data, select = -Department)
5) Using the detach() function
This helps you detach a column, making it independent of your dataframe. This is how we can do it:
# Removing the 'Department' column detach(employee_data, columns = c("Department"))
6) Using the exclude argument in summary()
This helps you exclude specific columns from the summary. It can be done using:
# Removing the 'Department' column summary(employee_data, exclude = c("Department"))
7) Using dplyr Package's select() Function
Several packages in R have functions that can be used to remove columns from the dataset. This dplyr package provides a concise and readable syntax for data manipulation tasks. We can code it using:
library(dplyr) # Removing the 'Department' column employee_data <- select(employee_data, -Department)
8) Using remove_column() Function in tibble Package:
This is a package that enhances data frames, providing them with modern and tidy data structures. For example,
library(tibble) # Removing the 'Department' column employee_data <- remove_column(employee_data, Department)
9) Using remove_columns() Function from janitor Package
This package simplifies data cleaning and tabulation tasks with easy-to-use functions. For example:
library(janitor) # Removing the 'Department' column employee_data <- remove_columns(employee_data, Department)
10) Conditional Column Removal
Most of the above methods can also be used to remove columns that match specific conditions. Here is how you do that using the dplyr Package select() Function:
# Remove column if its name starts with a specific prefix library(dplyr) prefix_to_remove <- "De" employee_data <- select(employee_data, -starts_with(prefix_to_remove))
Conclusion
In a nutshell, removing columns makes the data more readable and easier to process and analyze. We learned the different ways that a column can be removed. We also saw the problems of removing important columns, and how to avoid this. This whole process helps you obtain more accurate results while working with data.





