

In a library catalog, books are strategically indexed by titles, authors, and subjects, acting as a roadmap for efficient access. The title index allows users to find books alphabetically, the author index allows finding works by specific authors, etc. Similarly, we use indexing in SQL for fast retrieval of data from our tables. In this article, we will learn Indexing in SQL and types of Indexing.
What is Indexing in SQL?
SQL index is a handy tool that makes finding information in a database quick and easy. It is a simple feature designed for speedy searches, making it particularly useful for connecting tables and shifting through large sets of data. It is like creating a roadmap for the database to locate specific information efficiently.
Essentially, indexes serve to allow swift access to specific data points within the database. They contribute significantly to the efficiency of data retrieval operations, ensuring that queries are executed with speed and precision even as the database increases in size.
Uses of Indexing
Let’s explore where Indexing is particularly useful:
- Indexing is fundamentally a performance-enhancing tool within a database. Its significance becomes particularly important as a database expands in size.
- As the volume of data grows, the role of indexes becomes increasingly crucial in optimizing query performance and retrieval speed.
- Indexing extends beyond SQL, serving various purposes like address allocation and value retrieval.
- Indexing plays a crucial role in optimizing data retrieval by creating organized structures that expedite the search for specific values.
Key Terms In Indexing
In SQL indexing, nodes play crucial roles in hierarchical trees. Following are some of the nodes.
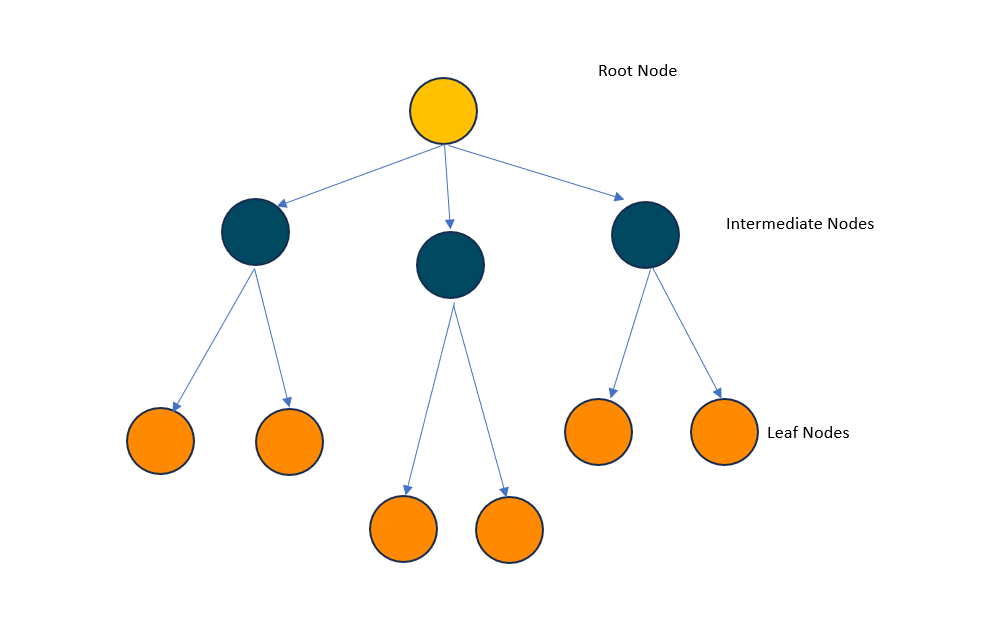
- Root Node: The root node is the topmost node in the tree. In a balanced tree index, the root contains key values and pointers to child nodes. It serves as the starting point for traversing the index structure.
- Leaf Nodes: Leaf nodes are the bottom-level nodes in the tree. In a balanced tree, leaf nodes contain key values along with pointers to the actual data. These nodes hold the real data, and the search path leads directly to them.
- Intermediate Nodes: Intermediate nodes are the internal nodes between the root and the leaves. In a balanced tree, they contain key values and pointers to child nodes, guiding the search path.
How to perform Indexing in SQL?
These index operations play a pivotal role in optimizing query execution and facilitating efficient data retrieval. Let us dive deeper into these key operations:
Creating an Index
The table provided below contains information about passengers, including attributes such as ID, name, PNR, and age.
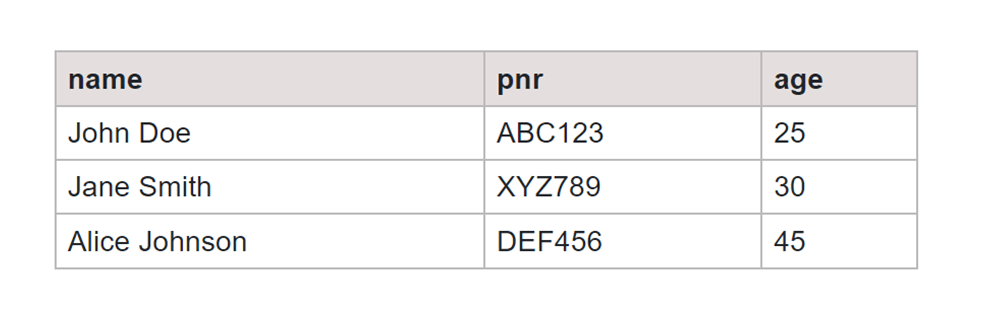
Now, we will create an index for the “name” attribute in the above table.
Syntax:
CREATE INDEX index_name ON table_name(column_name);
SQL Query:
CREATE INDEX passenger_name_index ON passenger(name);
Output:
SQL Query executed. Index added.
Fetching Data Using Indexing
When a table is indexed, a separate data structure is created that facilitates quicker access to specific rows based on the indexed column. This significantly improves the efficiency of search operations, as the database engine can swiftly locate relevant rows.
SQL Query:
SELECT * FROM passenger WHERE name = 'John Doe';
Output:
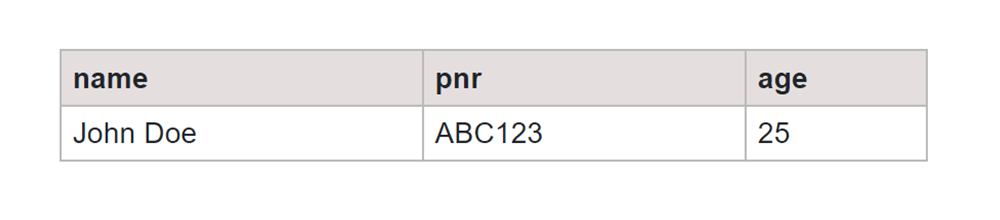
In this example, the table showed up faster, which is useful when dealing with big databases and long tables. It makes finding and organizing information much quicker. This speed boost is especially handy when working with a lot of data, saving time and making things more efficient.
Removing an Index
Removing an index in SQL is a straightforward process and can be done using the DROP INDEX statement. While removing an index it might speed up write operations (inserts, updates, deletes) because the index structure does not need to be maintained.
Syntax:
DROP INDEX index_name;
SQL Query:
DROP INDEX passenger_name_index;
Output:
SQL Query executed. Index removed.
Altering an Index
In SQL, altering an index involves modifying the characteristics of an existing index, such as changing its type or name.
Syntax:
ALTER INDEX index_name OPERATION(RENAME,ADD,DROP etc) ADD COLUMN column_name;
SQL Query:
ALTER INDEX passenger_name_index ADD COLUMN name;
Output:
SQL Query executed. New column added to index.
Renaming an Index
Renaming an index in SQL involves altering an existing index to a new and more meaningful name. A well-chosen name can convey the purpose or significance of the index, making it more understandable to developers and database administrators.
Syntax:
ALTER INDEX index_name RENAME TO new_index_name;
SQL Query:
ALTER INDEX passenger_name_index RENAME TO newpassenger_name_index;
Output:
SQL Query executed. Index name changed.
Types Of Indexing in SQL
Let us now explore different methods of using the SQL indexing function to access various rows and columns.
1) Clustered Indexing
A clustered index in SQL is a type of index that determines the physical order of data in a table. It is the phenomenon of arranging data on the disk to match the order of the indexed columns. This means that the rows in the table are physically organized on disk in the same order as the clustered index key.
This way of organizing things makes searches faster and improves how new data is added, making everything work better. However, it is important to pick the right columns for organizing, as it changes how the table is set up.
Example: The rows in an Employees Table, which comprises 6 rows, will be indexed based on the actual values in the table. This indexing allows the quick retrieval of specific values within the table.
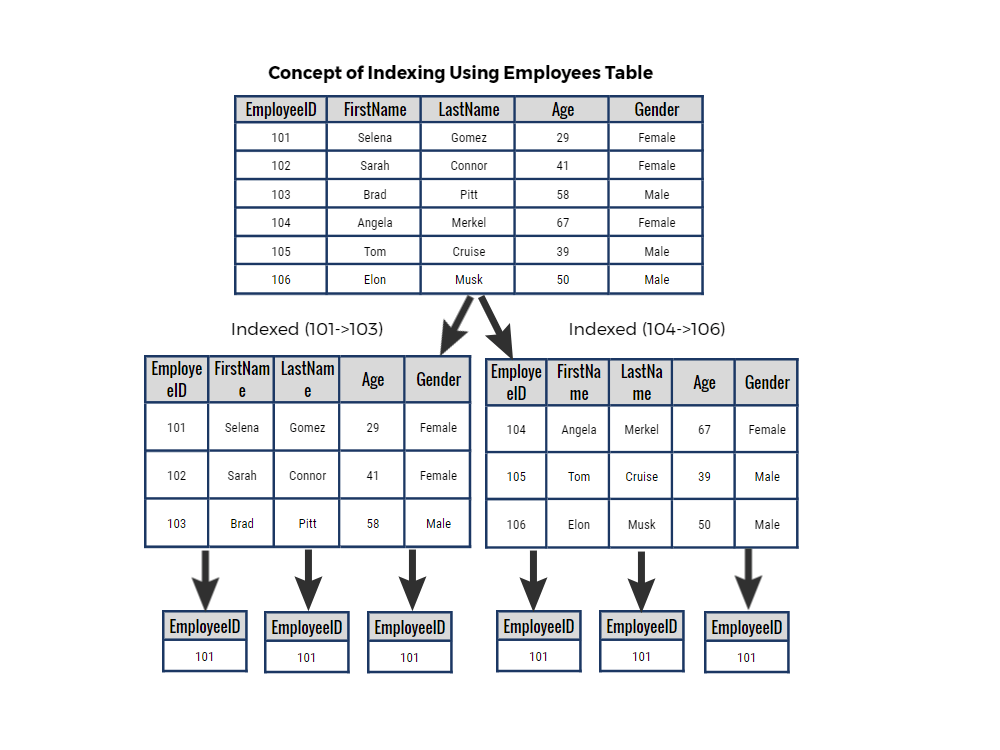
If a user wishes to know the FirstName associated with the EmployeeID of 1, the system will proceed by the roadmap outlined in the provided flowchart.
The following query is used to perform this operation:
select FirstName from employees where EmployeeID = 101
Output:
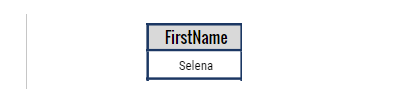
Now, think about the previous example but imagine it is for a huge table with millions of rows. Using indexing is like using a helpful trick to find things in this massive amount of data, similar to what we talked about before but on a much larger scale.
The following syntax is used for clustered indexing:
CREATE CLUSTERED INDEX Employees_IX ON member (FirstName ASC)
2) Un/Non-Clustered Indexing
An unclustered index is an index where the order of the rows does not match the physical order of the actual data. Unclustered indexing implies that the sequence of data remains unchanged, and when a query is executed for specific results, the data will be retrieved in the same sequence.
A Non-clustered index works differently from a Clustered index. It doesn't rearrange how the actual data in the table is stored. Instead, it uses index pages to keep track of the key values and points to where the rows are stored in the table.
Example: Consider having a table named "Employees," and we frequently need to search for employees based on their last names. If we create an unclustered index on the "LastName" column, you instruct the database to construct a distinct structure. This structure stores last names and pointers to the corresponding rows in the table, without changing the physical order of the rows.
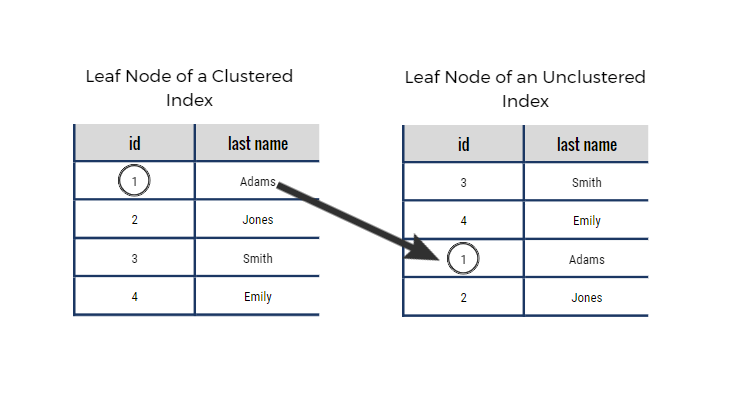
When we perform a query searching for an employee by last name, the database engine can swiftly use the unclustered index to locate the relevant rows without altering the actual data.
The following syntax is used for clustered indexing:
CREATE NONCLUSTERED INDEX Employees_IX on Employees.LastName
Evaluating the expenses associated with the non-indexed and Indexed Queries:
- For the non-indexed table, a complete table scan is necessary. This involves reading over thousands of rows to obtain the result, resulting in a higher execution time of.
- In contrast, the indexed table employed an index scan, leveraging the index to swiftly locate the requested data. This approach entirely avoids the need to unnecessarily read rows. Consequently, the execution time is significantly reduced exponentially.
- Ultimately, Indexed queries efficiently use index structures to pinpoint data locations, resulting in faster execution.
Conclusion
In SQL, indexing serves as a powerful tool, much like Google Maps does in finding a location. It optimizes data organization, making retrieval and analysis more efficient. By creating structured indices, SQL enhances data accessibility and accelerates query performance.





