Finding all anagrams in a string is one of the famous problems in Data structure that is often asked in technical interviews. In this article, we will understand this famous problem (also available in leetcode) and explore various approaches to solve it.
Find all Anagrams in a String Problem
First, let’s revise what an anagram is. An anagram is formed when the characters of one string can be rearranged to create another string. Take the words: “rama” and “amar”. The characters in “amar” can be rearranged to form “rama.”
In this problem we are given a string S and a pattern P, the task is to find the starting indices of substrings in S that are anagrams of P.
We will iterate through all possible substrings of S with the same length as P. For each substring, it checks whether the characters can be rearranged to match the characters in P. If a match is found, the starting index of that substring is added to the list of output indices. The final output is the list of starting indices where anagrams of P are present in S.
Let us discuss it with an example:
Input:
S = "favavfvaf"
P = "fav"Output:
[0, 3, 5, 6]Naive Approach: Using Sorting
In this approach, we will use the concept of sorting the string. Let us understand it better with an example:
String P is “fav,” we can identify anagrams in string S by sorting both the pattern P and its potential anagrams. For instance, the anagrams of P in S are “fav,” “vfa,” and “afv.” When we sort P and its anagrams, they all become “fav.” This helps us to simplify the identification process.
To find anagrams of P in S, we can iterate through all substrings of S, sort each substring, and compare it to the sorted version of P. If they match, the substring is an anagram of P.
Firstly we will sort P and after sorting P becomes “afv” Then we will iterate over S with a Window equal to P’s length.
After taking that particular substring from the current window (let’s say temp) we will sort it and if the sorted substring is equal to sorted P then we will push the starting index of the window to our answer array.
Sorted P = “afv”
Window size = 3
Current window substring = “fav”
Sorted substring = “afv”

Similarly, we will take all windows of size 3
The Time Complexity of using sorting approach for finding all anagrams in a string is O(m log m) + O((n-m+1) * (m + m log m + m)). Because sorting string P takes O(m log m) time, where m is the length of string P and Iterating through all possible substrings of S: The for loop runs (n-m+1) times, where n is the length of string S.
In each iteration, the algorithm builds a temporary substring (temp) of length m, sorts it (O(m log m)), and compares it with the sorted version of P (O(m)).
The Space Complexity of this approach is O(m) because of the sorted string P and the temporary substring (temp) created in each iteration.
Optimized Approach: Hashing + Sliding Window
The best way to find all anagrams in a string is by using hashing with sliding windows. We will use hashing and sliding windows to identify anagrams of a given string P within string S, we can examine every substring of S that has the same length as P. To check an anagram we have to check that a substring contains the same character with the same frequency as those in P.
Below is the step-by-step guide to using hashing to find all anagrams:
- We will keep two arrays to track the frequencies of characters in both string P and the current substring in string S. If these frequency arrays match for a substring, then that substring is an anagram of string P.
- To identify substrings of the same length as string P we will maintain a window with a size equal to the length of string P.
- In each iteration, we will include a new character in the window while removing the first character. This ensures that the window length remains constant throughout each iteration.

Window size = Size of P = 3
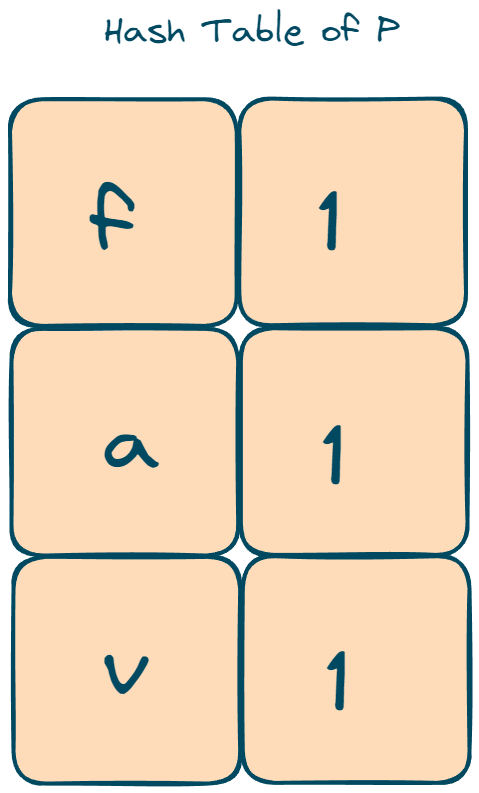
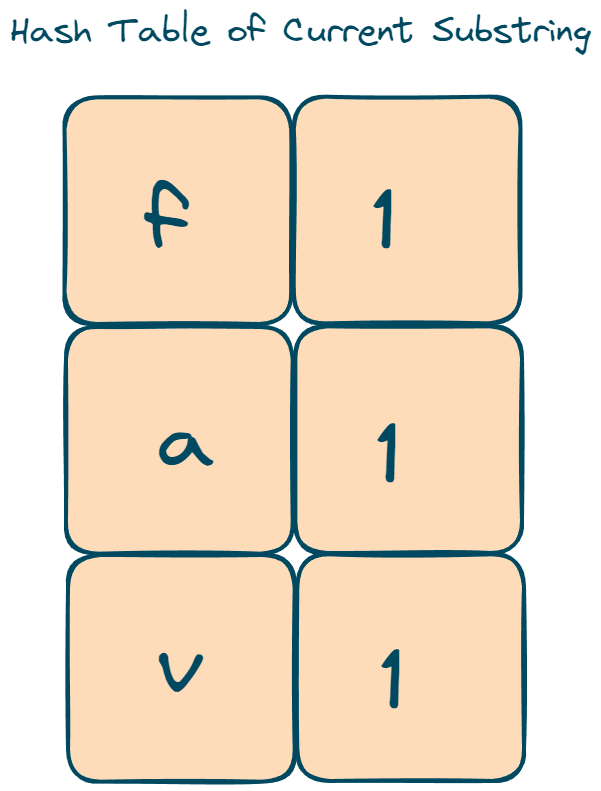
The hash table of both the current window substring and the hash table of string P are the same.
Hence both are anagrams.
Similarly, take all windows of size 3.
C++ Code
Here is the implementation in C++:
#include <bits/stdc++.h>
using namespace std;
// Function to find starting indices of anagrams of string 'p' in string 's'
vector<int> FindAnagrams(string &s, string &p)
{
// Vector to store the starting indices of anagrams
vector<int> ans;
// Frequency arrays for characters in 'p' and the current window in 's'
vector<int> arr1(26, 0), arr2(26, 0);
// Lengths of strings 's' and 'p'
int n = s.length(), m = p.length();
// If 'p' is longer than 's', no anagrams are possible
if (m > n)
return ans;
// Initialize the frequency arrays for the first window in 's'
for (int i = 0; i < m; i++)
arr1[p[i] - 'a']++, arr2[s[i] - 'a']++;
// Check if the frequency arrays match for the first window
if (arr1 == arr2)
ans.push_back(0);
// Iterate through the remaining windows in 's'
for (int i = m; i < n; i++)
{
// Include the new character in the current window
arr2[s[i] - 'a']++;
// Remove the first character from the window
arr2[s[i - m] - 'a']--;
// Check if the frequency arrays match for the current window
if (arr1 == arr2)
ans.push_back(i - m + 1);
}
return ans;
}
// Main function
int main()
{
// Example strings
string s = "favavfvaf", p = "fav";
// Find starting indices of anagrams
vector<int> arr = FindAnagrams(s, p);
// Display results
if (arr.empty())
cout << "There are No Anagrams of " << p << " in " << s << endl;
else
{
cout << "Starting Indices of Anagrams are " << endl;
for (auto &val : arr)
cout << val << " ";
}
return 0;
}Java Code
Find the Java code below to find all anagrams in a string:
import java.util.*;
class fav{
// Function to find starting indices of anagrams of string 'p' in string 's'
static ArrayList<Integer> FindAnagrams(String s, String p) {
ArrayList<Integer> ans = new ArrayList<>();
// Frequency arrays for characters in 'p' and the current window in 's'
int[] arr1 = new int[26];
int[] arr2 = new int[26];
int n = s.length(), m = p.length();
// If 'p' is longer than 's', no anagrams are possible
if (m > n)
return ans;
// Initialize the frequency arrays for the first window in 's'
for (int i = 0; i < m; i++) {
arr1[p.charAt(i) - 'a']++;
arr2[s.charAt(i) - 'a']++;
}
// Check if the frequency arrays match for the first window
if (Arrays.equals(arr1, arr2))
ans.add(0);
// Iterate through the remaining windows in 's'
for (int i = m; i < n; i++) {
// Include the new character in the current window
arr2[s.charAt(i) - 'a']++;
// Remove the first character from the window
arr2[s.charAt(i - m) - 'a']--;
// Check if the frequency arrays match for the current window
if (Arrays.equals(arr1, arr2))
ans.add(i - m + 1);
}
return ans;
}
// Main function
public static void main(String args[]) {
// Example strings
String s = "favavfvaf", p = "fav";
// Find starting indices of anagrams
ArrayList<Integer> arr = FindAnagrams(s, p);
// Display results
if (arr.isEmpty())
System.out.println("There are No Anagrams of " + p + " in " + s);
else {
System.out.println("Starting Indices of Anagrams are ");
for (int val : arr)
System.out.print(val + " ");
}
}
}Python Code
Check the python program to solve this problem:
def find_anagrams(s, p):
ans = []
# Frequency arrays
arr1 = [0] * 26
arr2 = [0] * 26
n, m = len(s), len(p)
if m > n:
return ans
# First window
for i in range(m):
arr1[ord(p[i]) - ord('a')] += 1
arr2[ord(s[i]) - ord('a')] += 1
if arr1 == arr2:
ans.append(0)
# Subsequent windows
for i in range(m, n):
arr2[ord(s[i]) - ord('a')] += 1
arr2[ord(s[i - m]) - ord('a')] -= 1
if arr1 == arr2:
ans.append(i - m + 1)
return ans
# Main function
def main():
s = "favavfvaf"
p = "fav"
arr = find_anagrams(s, p)
if not arr:
print(f"There are No Anagrams of {p} in {s}")
else:
print("Starting Indices of Anagrams are:")
print(*arr)
if __name__ == "__main__":
main()Output:
Starting Indices of Anagrams are
0 3 5 6 The Time Complexity to find all anagrams in a string using hashing and sliding windows is O((n-m+1)*26), because for loop iterates for “n – m + 1” times, representing the possible starting positions of substrings of length equal to string P within string S.
In each iteration, the frequency arrays of the current substring in string S and string P are compared. The Space Complexity of this optimized approach is O(1).
Here is the comparison of both approaches:
| Approaches | Time Complexity | Space Complexity | Details |
| Naive approach: Sorting | O(mlogm) + O( (n-m+1)*(m+mlogm+m) ) | O(n*m) | We take substrings from the window of size equal to the size of P and compare the sorted substrings with sorted P. If they are equal then they are anagrams. |
| Hashing + Sliding Window | O((n-m+1)*26) | O(1) | We take substrings from the window of size equal to the size of P and compare the hash table of characters substring with the hash table of P. If they are equal then they are anagrams. |
Conclusion
In conclusion, the optimized Hashing + Sliding Window approach stands out as the most efficient solution for finding all anagrams in a string problem. This approach is recommended for larger datasets.