Anagrams are an interesting concept in the realm of programming that most new techies feel a little confused about. In this article, our goal is to explore one such leet code problem called ‘Valid Anagram’ where we have to check whether two strings are Anagrams of each other with a proper solution.
What is a Valid Anagram Problem?
An anagram is a word formed by rearranging the letters of another word, using all the original letters exactly once.
In the Valid Anagram problem, we are given two strings and we have to check if the two strings contain the same characters, regardless of their order.
Let us understand it with a couple of examples below:
Input: s = “cab”, t = “abc”
Output: True

Both the strings contain ‘a’, ‘b’, and ‘c’ each.
Input: s = “rat”, t = “car”
Output: false
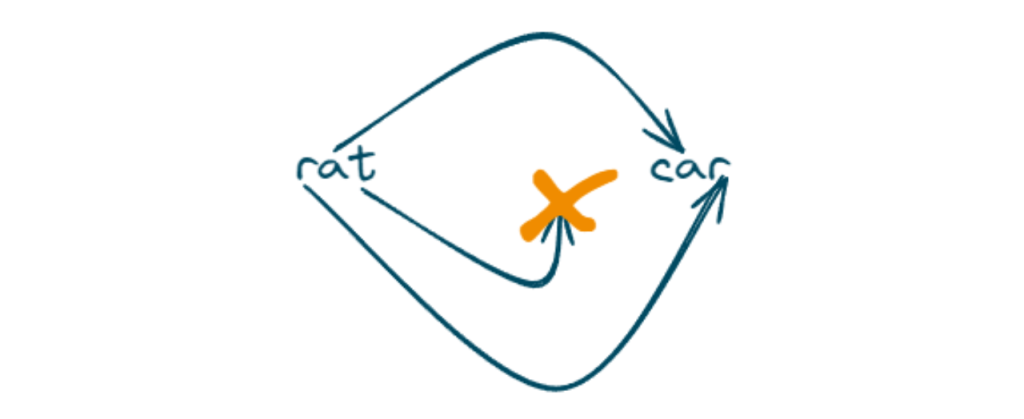
The first string contains ‘r’, ‘a’, and ‘t’, and the second string contains ‘c’, ‘a’, and ‘r’.
Naive Approach: Sorting
In this approach we will compare both strings after sorting them, if they are not equal at any point then we will return false otherwise they are anagrams of each other.
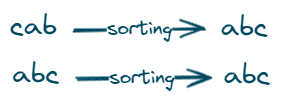
Steps used in this approach:
- Firstly we will check the lengths of two input strings, the lengths of two strings should be equal to further check if they are valid anagrams.
- Now we will sort both strings and run a loop to check each character of the first string with each character of the second string.
- If we find a different character in a sorted string then we will return a false
- If each character of both strings matches. Then they are valid anagrams.
Complexity Analysis
The time complexity of this approach is O(n * logn), as in this we are running our loop for n times and log n for sorting of strings
The space complexity is O(1) as we are not using any extra space.
Optimized Approach: Using Hashing
In the hashing approach, we will use a hashmap data structure to check if two strings are valid anagrams. Here are all the steps involved:
- Firstly we will check the lengths of two input strings, the lengths of two strings should be equal to further check if they are valid anagrams.
- Now we will create a hashmap mp to store the frequency of each character in the first string. The loop iterates through each character in the first string and increments its count in the map.
- Now we will run another loop that iterates through each character in the second string decreasing the count of each character in the map.
- If the second string has a character that is not present in the first string or has more occurrences than in the first string, it will result in a negative count.
- A final loop iterates through the map, checking if any character has a non-zero count
- If any character has a count other than zero, it means the frequencies in the first string and second string are not the same, indicating that the strings are not anagrams.
- If the loop completes without finding such a character, the function returns true, indicating that the strings are valid anagrams.
C++ Code
Let’s implement all the above steps in C++:
#include <bits/stdc++.h>
using namespace std;
bool areAnagrams(const string& a, const string& b) {
// Check if the lengths of the strings are different
if (a.length() != b.length()) {
return false;
}
// Create a map to store the frequency of each character in the first string
unordered_map<char, int> mp;
for (int i = 0; i < a.length(); i++) {
mp[a[i]]++;
}
// Adjust the frequency counts based on the second string
for (int i = 0; i < b.length(); i++) {
mp[b[i]]--;
}
// Check if any character has a non-zero count, indicating the strings are not anagrams
for (const auto& it : mp) {
if (it.second != 0) {
return false;
}
}
// If the loop completes without returning, the strings are anagrams
return true;
}
int main() {
string string1 = "cab";
string string2 = "abc";
if (areAnagrams(string1, string2)) {
cout << "\"" << string1 << "\" and \"" << string2 << "\" are anagrams!" << endl;
} else {
cout << "\"" << string1 << "\" and \"" << string2 << "\" are not anagrams." << endl;
}
return 0;
}Python Code
Let’s implement the hashing approach in Python:
def are_anagrams(a, b):
# Check if the lengths of the strings are different
if len(a) != len(b):
return False
# Create a dictionary to store the frequency of each character in the first string
char_count = {}
for char in a:
char_count[char] = char_count.get(char, 0) + 1
# Adjust the frequency counts based on the second string
for char in b:
if char not in char_count:
return False
char_count[char] -= 1
# Check if any character has a non-zero count, indicating the strings are not anagrams
for count in char_count.values():
if count != 0:
return False
# If the loop completes without returning, the strings are anagrams
return True
# Example usage
string1 = "cab"
string2 = "abc"
if are_anagrams(string1, string2):
print(f'"{string1}" and "{string2}" are anagrams!')
else:
print(f'"{string1}" and "{string2}" are not anagrams.')Java Code
Here is the Java program as well:
import java.util.HashMap;
import java.util.Map;
public class AnagramChecker {
public static boolean areAnagrams(String a, String b) {
// Check if the lengths of the strings are different
if (a.length() != b.length()) {
return false;
}
// Create a map to store the frequency of each character in the first string
Map<Character, Integer> charCount = new HashMap<>();
for (int i = 0; i < a.length(); i++) {
char c = a.charAt(i);
charCount.put(c, charCount.getOrDefault(c, 0) + 1);
}
// Adjust the frequency counts based on the second string
for (int i = 0; i < b.length(); i++) {
char c = b.charAt(i);
if (!charCount.containsKey(c)) {
return false;
}
charCount.put(c, charCount.get(c) - 1);
}
// Check if any character has a non-zero count, indicating the strings are not anagrams
for (int count : charCount.values()) {
if (count != 0) {
return false;
}
}
// If the loop completes without returning, the strings are anagrams
return true;
}
public static void main(String[] args) {
String string1 = "cab";
String string2 = "abc";
if (areAnagrams(string1, string2)) {
System.out.println("\"" + string1 + "\" and \"" + string2 + "\" are anagrams!");
} else {
System.out.println("\"" + string1 + "\" and \"" + string2 + "\" are not anagrams.");
}
}
}Output:
"cab" and "abc" are anagrams!The Time complexity is O(n) for the hashing approach to check if two strings are anagrams of each other, where n is the length of the input strings. The loop iterating through the unordered_map contributes a constant factor based on the number of distinct characters
The space complexity is O(c), where c is the number of distinct characters in both strings. In the worst case, this is O(26) for lowercase English letters.
Analysis of Both the Approaches
| Approaches | Time complexity | Space complexity | Details |
| Sorting Approach | O(n * logn) | O(1) | In this we have used a loop that iterates for the length of the string |
| Hashing Approach | O(n) | O(c) | In this loop iterates through the unordered_map contributes a constant factor based on the number of distinct characters |
Conclusion
In conclusion, we found a perfect solution to the famous Valid Anagram leetcode problem using hashing. We also provided the complete programs in C++, Python, and Java, along with the time and space complexities.