

Data Structures is one of the most important subjects to conquer to become a good programmer. In this article, we will discuss the “First Unique Character in a String” problem from leetcode and how to code the solution.
First Unique Character in a String problem
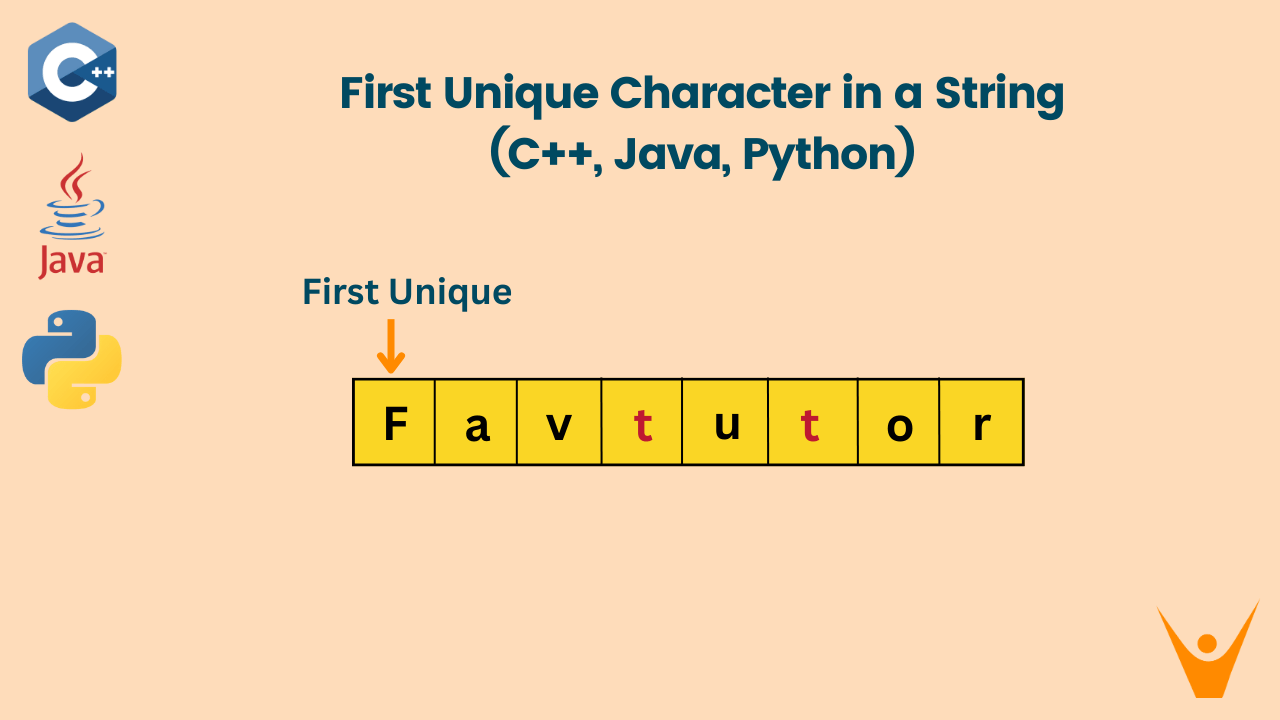
In the First Unique Character in a String problem, we have given a string and we must find the index of the first non-repeating character from the string.
For example, if you have given a string “favtutor” then non-repeating characters in this string are f, a, v, u, o, r. The first non-repeating character is ‘f’. So the index is 0.
Let’s look at some more examples:
Input: s = “amma”
Output: -1 (as all the characters in this string have more than one occurrence)
Input: s = “favtutor”
Output: 0
Input: s = “abcac”
Output: 1

Note: String only contains lowercase alphabetical characters.
The easiest way is to go to each index and check if the same character is present in the string or not. If not, return this index; otherwise, check for the next index. If no such element is present, return -1.
Let’s examine this approach on the string s = “favtutor.” Simply, Iterate over the string and check if that character is present in that string or not. In this case, f is only present at index 0. So the answer is 0.
Time Complexity here will be O(n^2), where ‘n’ is the size of the string. As we are iterating over two loops. One to go at each place, another to check if that character is present more than once or not. Space complexity will be O(1) as we are not using any extra space.
Hash-Map Approach
The brute force approach is taking too much time. We can reduce the time complexity if we use a hash map to store the characters of the string. This will reduce the time complexity from O(n^2) to O( n log(n) ).
Let’s find out the steps involved:
- Create a hash map that will store the frequency of each character.
- Store each character on the map.
- Iterate over the string and check the frequency of that character. If the frequency is one then return this index. Otherwise, check for the next index.
- If there is no such character, return -1.
Time Complexity will be O( n log(n) ). Here n is the size of the string. As we are storing each character in the map and storing values in the map it requires log(n) time. Space complexity will be O(26), which is approximately O(1), as there are only 26 different characters.
Optimized Approach
In the hash map approach, we saw that if we store the frequency of each character we can easily find out the first non-repeating character. However, storing elements into the hash map requires Log(n) time complexity. This can be reduced if we use an array of size 26 and store the frequency using it.
Let’s examine this approach.
- First, create an array of size 26 with initially all values equal to 0.

- Iterate over the string and keep updating the values of the array.
- Index: 0

- Index: 1

- Index: 2

- Index: 3

- Index: 4

- Index: 5

- Index: 6

- Index: 7

- Last, Iterate over the string again and check in the array if the character frequency is one or not. If one returns that index.
Let’s see the code for the above approach.
C++ Code
Here is the C++ solution:
#include <bits/stdc++.h>
using namespace std;
int main(){
string s = "favtutor";
// array count to store the frequency of characters.
vector<int>count(26,0);
for(int i=0;i<s.size();i++){
// storing the frequency of the character.
count[s[i]-'a']++;
}
for(int i=0;i<s.size();i++){
// checking if the character is non-repeating or not.
if(count[s[i]-'a']==1) {
cout<<i<<endl;
goto he;
}
}
cout<<-1<<endl;
he:;
return 0;
}Java Code
Below is the Java program to find the first unique character in a string:
public class Main {
public static void main(String[] args) {
String s = "favtutor";
// array count to store the frequency of characters.
int[] count = new int[26];
for (int i = 0; i < s.length(); i++) {
// storing the frequency of the character.
count[s.charAt(i) - 'a']++;
}
for (int i = 0; i < s.length(); i++) {
// checking if the character is non-repeating or not.
if (count[s.charAt(i) - 'a'] == 1) {
System.out.println(i);
break;
}
}
}
}Python Code
We can implement the optimized apprach in Python also:
s = "favtutor"
count = [0] * 26
for char in s:
# storing the frequency of the character.
count[ord(char) - ord('a')] += 1
for i, char in enumerate(s):
if count[ord(char) - ord('a')] == 1:
print(i)
break
else:
print(-1)Output:
0In this approach, we are storing the values in the array which requires O(1) time to store which reduces our time complexity to O( n log(n) ). Space Complexity is O(1) as only 26 values are stored in the array.
Here is a comparison of the three approaches we discussed:
| Approach | Time Complexity | Space Complexity | Description |
|---|---|---|---|
| Brute Force Approach | O(n^2) | O(1) | As we are iterating the string two times. |
| Hash Map Approach | O( n log(n) ) | O(1) | Storing the values in the hash map requires log(n) time complexity. |
| Optimized Approach | O(n) | O(1) | Storing the values in the array reduces the time to O(n). |
Conclusion
In this article, we found various ways to find the first unique character in a string, a problem listed in leetcode as well. We had only considered lowercase in this article to try to solve this question if there are both lower and uppercase on your own. Try to find out those and also find out their time complexity.