



Benchmarks are the primary method of evaluating new LLMs and comparing their performance. Model capabilities and whether it’s “better than GPT-4” are all decided based on benchmarks. But what if this method is biased?
A new research paper titled “A Careful Examination of Large Language Model Performance on Grade School Arithmetic” by Scala AI, explored the likelihood of a few models having overfit on the benchmark dataset and suggested remedies for the same.
Highlights:
- The researchers created GSM1k, a new dataset mirroring GSM8k, to test LLM overfitting and data contamination in mathematical reasoning benchmarks.
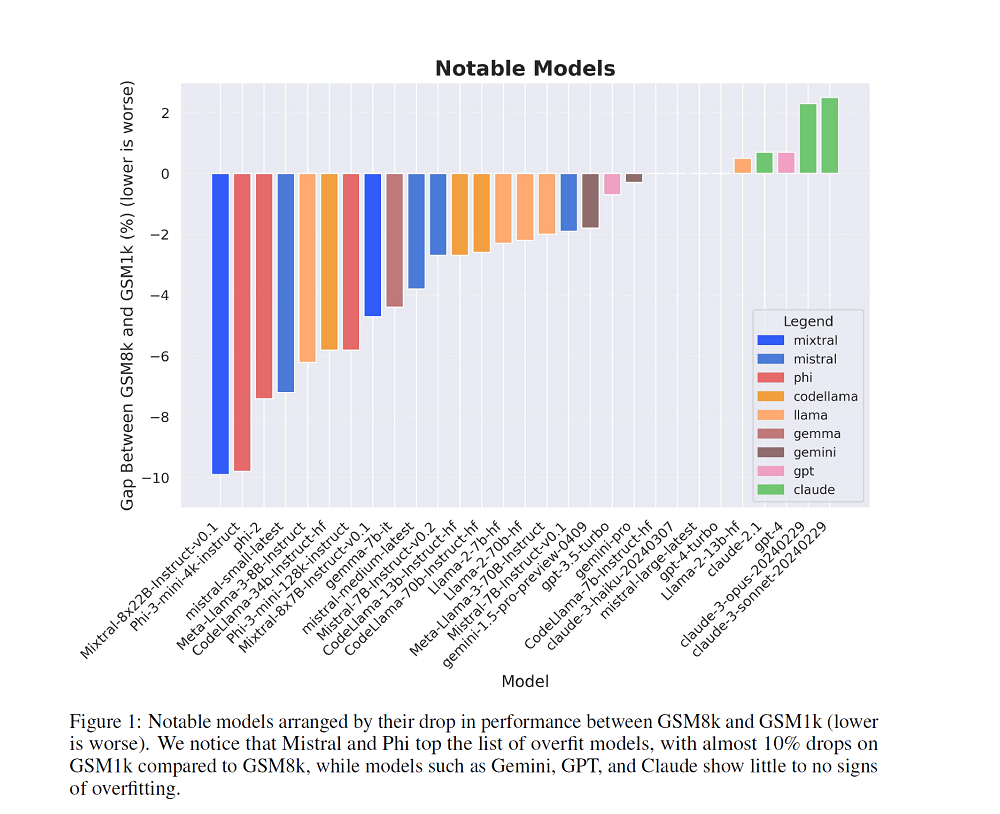
- Some models, particularly Phi and Mistral families, showed significant overfitting (up to 13% accuracy drop) on GSM1k compared to GSM8k; frontier models like Gemini, GPT, and Claude showed minimal overfitting.
- Overfitting is correlated with GSM8k generation probability, suggesting memorization; however, overfit models still exhibit reasoning abilities, albeit lower than benchmark numbers indicate.
The study provided insights into the current state of LLM reasoning capabilities, the extent of benchmark overfitting, and recommendations for future benchmark design to reduce data contamination risks.
What does it mean by Overfitting for LLMs?
Overfitting occurs in deep learning networks when the model performs excellently only on the specific training dataset but fails to generalize well. In this case, the training accuracy is good but the validation and testing accuracy falls.
This paper suggests that academic benchmarks may be widely contaminated, i.e. the data from the academic benchmark datasets is used in the training process making the model better at evaluation on the same dataset.
Think of it like memorization. If a student knows the exact question that will be asked in a math exam, he will memorize only those questions and score very high on the test. However, that does not mean he has understood the concept or is able to reason out the solution. LLMs are dealing with exactly this.
The new dataset:
Data contamination has been a well-known issue in the AI field with many prominent researchers suggesting methods to avoid contamination using different embeddings, preventing overlap or similarity, and using functions to generate an infinite number of specific evaluation data points, each with slightly different numbers.
The approach of this paper was to generate a new dataset called GSM1k. It is a collection of 1250 grade-school level math problems designed to mirror that of GSM8k.

All problems were annotated by human annotators, who were 9instructed to create problems solvable only with basic arithmetic ( addition, subtraction, multiplication, division ) and which did not require any advanced math concepts.
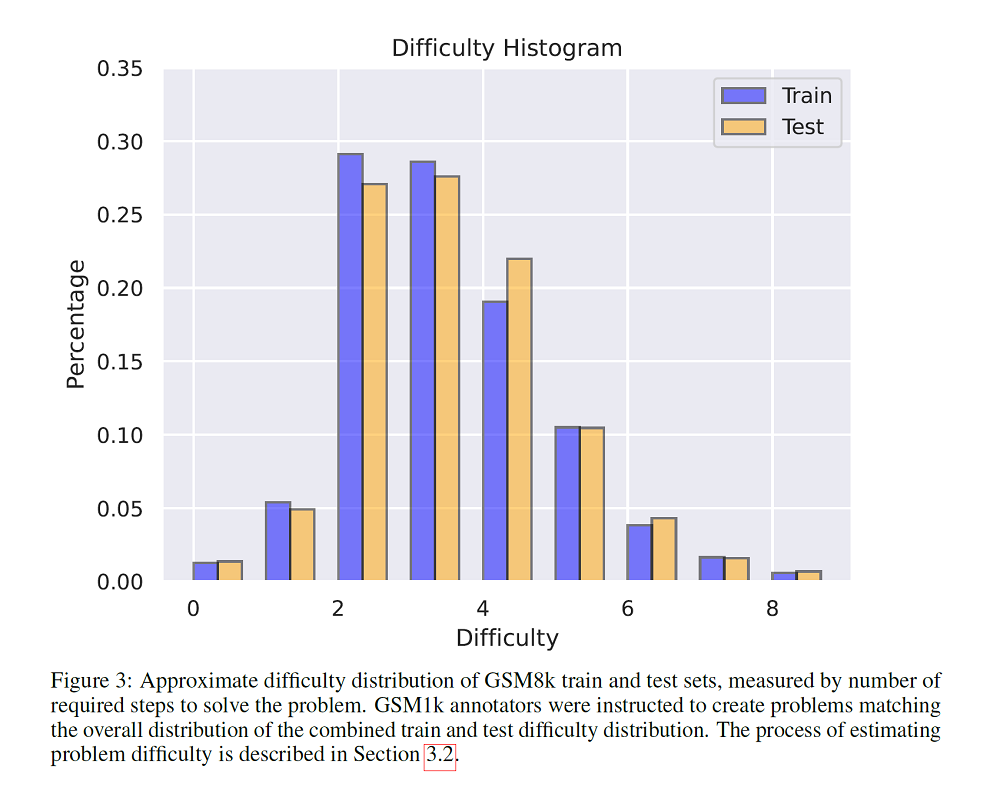
To prevent data contamination, the authors chose not to reveal the contents of the dataset publicly. The new dataset, while highly similar to GSM8k, is not identically distributed despite their best efforts.
Results of testing on old and new benchmarks:
Several model families, most notably Phi and Mistral, exhibited consistent overfitting across almost all model sizes and versions. These models performed significantly worse on GSM1k compared to GSM8k, indicating that their impressive GSM8k performance might not reflect true reasoning ability.
In contrast, frontier models such as Gemini, GPT, and Claude showed minimal signs of overfitting, with similar performance on both GSM8k and GSM1k. This suggests that these models may have more robust reasoning capabilities and are less prone to overfitting on specific benchmarks.
The authors found a positive correlation (Spearman’s r² = 0.32) between a model’s probability of generating examples from GSM8k and its performance gap between GSM8k and GSM1k.
This indicates that models with a higher likelihood of generating GSM8k-like examples tend to have larger performance gaps, suggesting partial memorization of GSM8k.
Despite the observed overfitting, all models, including the most overfit ones, still demonstrated the ability to solve novel grade school math problems.
However, their performance on truly unseen problems was lower than their benchmark numbers suggested, highlighting the impact of overfitting on the accuracy of performance assessments.
While data contamination (i.e., test set leakage into training data) is a plausible explanation for overfitting, the authors suggested that other factors may also contribute. These factors include collecting training data that closely resembles benchmark data and selecting model checkpoints based on benchmark performance.
In a piece of related news, a new study about LLMs also found how to improve them by providing them with more examples.
Conclusion
This study was specifically about the grade school mathematics benchmark that most models are evaluated on. But what of the other benchmarks? The findings of this study suggest that other benchmarks may be contaminated in a similar manner, especially the human eval benchmark.




