



Stability AI just released Stable Code Instruct 3B, an instruction-tuned Code Language Model based on Stable Code 3B. By using natural language prompting, Instruct 3B can handle various tasks such as code generation, software development, and mathematics-related queries. Let’s look at how Stable Code Instruct 3B works.
Highlights:
- Stability AI just released Stable Code Instruct 3B, an instruction-tuned Code Language Model that can handle tasks such as code generation, software development, and math operations.
- It outperforms comparable models such as Codellama 7B Instruct, and DeepSeek-Coder Instruct 1.3B in various coding-related tasks.
- The weights and code for Stable Code Instruct 3D are available publicly on HuggingFace from where users can test it model for non-commercial uses.
What is Stable Code Instruct 3B?
Stable Code Instruct 3B is Stability AI’s latest instruction-tuned large language model (LLM), built on top of Stable Code 3B. This model enhances code completion and has support for natural language interactions, aiming to improve the efficiency of programming, math, and software development related tasks.
Stability AI introduced the Instruct 3B model with the following post on X:
Introducing Stable Code Instruct 3B, our new instruction tuned LLM based on Stable Code 3B. With natural language prompting, this model can handle a variety of tasks such as code generation, math and other software engineering related outputs.
— Stability AI (@StabilityAI) March 25, 2024
This model’s performance rivals… pic.twitter.com/RsZhKpWu57
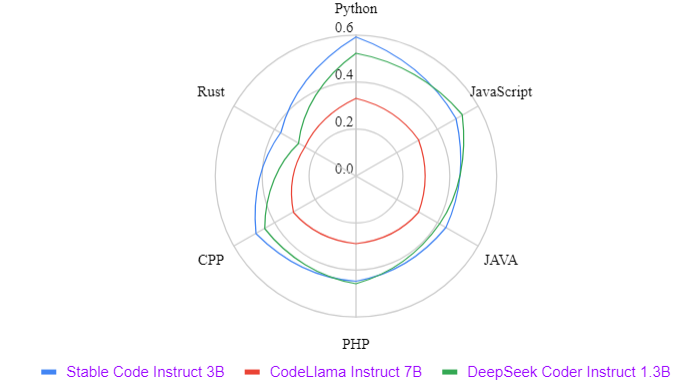
Stability AI’s analysis suggests that Instruct 3B outperforms comparable models like Codellama 7B Instruct and DeepSeek-Coder Instruct 1.3B in several coding-related tasks. Stable Code Instruct also exhibits state-of-the-art (SOTA) performance on the MT-Bench coding tasks and Multi-PL completion compared to other instruction-tuned models.
Their analysis suggests that Stable Code Instruct 3B outperforms comparable models such as Codellama 7B Instruct, and DeepSeek-Coder Instruct 1.3B in various coding-related tasks.
The model is available with a Stability AI Membership for commercial use. The weights and code for Stable Code Instruct 3B are now available on Hugging Face. Users can test the model for free using HuggingFace and can download the weights and code for non-commercial use.
What can Stable Code Instruct 3B do? Here’s the list:
- Automated Code Completion
- Insertion of Missing Code Snippets
- Code Generation for Database Interaction
- Translation of Programming Languages
- Explanation of Code Functionality
- Code Generation Based on User Instructions
Training Data for Stable Code Instruct 3B
To make the pre-training dataset for Stable Code, the team gathered diverse data from various publicly available sources, including code repositories, technical documents, mathematical texts, and extensive web datasets.
The primary aim of this initial pretraining phase was to develop a comprehensive internal representation that goes beyond mere code understanding. Their goal was to significantly enhance the model’s proficiency in mathematical comprehension, logical reasoning, and processing complex technical texts related to software development.
By selecting such a diverse dataset mix, they aimed to create a language model well-equipped to handle a wide range of software engineering tasks, not limited to code completion alone. Additionally, the training data incorporates general text datasets to provide the model with broader linguistic knowledge and context.
1) Synthetic Dataset
They incorporated a small synthetic dataset into the pre-training corpus, generated from the seed prompts of the CodeAlpaca dataset, consisting of 174,000 prompts. To enhance the diversity and complexity of the prompts, they utilized the “Evol-Instruct” method
This method involves progressively increasing the complexity of seed prompts using a language model, in this case, WizardLM, through strategies that focus on breadth, reasoning, deepening, and complexity.
As a result, they augmented the dataset with an additional 100,000 prompts. They employed the DeepSeek Coder 34B model to generate synthetic outputs for the newly developed “Evol-Instruct” prompts. This early introduction of synthetic data during the pretraining phase aimed to improve the model’s ability to respond to natural language text.
2) Long-Context Dataset
Expanding upon the initial pre-training phase, they also developed an additional training stage focused on enhancing the model’s ability to process and understand long sequences, particularly beneficial for coding models dealing with multiple files within a repository.
After analyzing the median and mean token counts in software repositories, they determined a context length of 16,384 tokens.
In this stage, they utilized a curated selection of programming languages from The Starcoder dataset, including programming languages such as Python, Java, Javascript, C, C++, and GoLang based on the insights provided by the 2023 Stack Overflow Developer Survey.
These are the languages that are most used by developers. Apart from these languages, they also included training for different broadly adopted languages like SQL, PHP, and Rust.
The long context dataset was created by combining files from these languages within a repository, with a special <repo_continuation> token inserted between each file for separation while maintaining content flow. They employed a randomized strategy to generate two distinct orderings for each repository to avoid potential biases from fixed file orderings.
Multi-Stage Training
They adopted a staged training methodology, a strategy commonly employed in other similar strong code language models like CodeGen, Stable Code Alpha, CodeLLaMA, and DeepSeekCoder models. In training Stable Code, they utilize standard autoregressive sequence modelling to predict the next token.
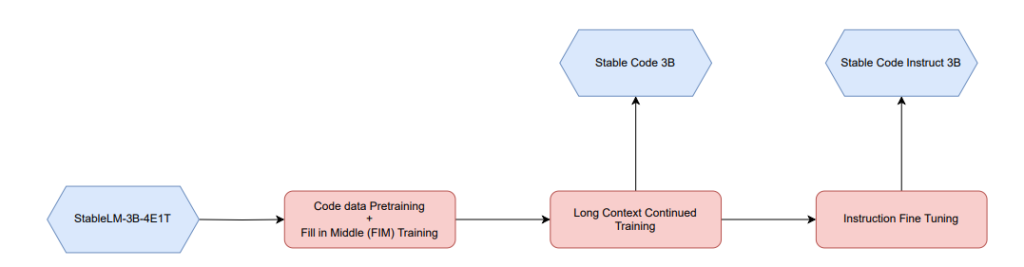
The model has been initialized from the Stable LM 3B checkpoint, with a base context length of 4096 for the initial training stage, incorporating the specified data mix. Subsequently, a continued pretraining stage follows, as illustrated in the figure below.
Fill in the Middle (FIM) Training
Utilizing the “Fill in the Middle” (FIM) objective is a strategy adopted to address the challenge posed by the non-linear ordering of tokens in code, which often deviates from the left-to-right causal ordering observed in natural language.
This approach involves randomly dividing a document into three segments – prefix, middle, and suffix – and then relocating the middle segment to the end of the document before continuing with the autoregressive training process.
By doing so, the model can learn to condition structural patterns beyond the traditional prefix-only format typical in causal language modelling.
The data augmented through this process is categorized into two modes: “Suffix-Prefix-Middle” (SPM) and “Prefix-Suffix-Middle” (PSM), with FIM applied at the character level with a rate of 50%, and the choice between SPM and PSM modes determined uniformly.
This FIM approach is implemented during both stages of pretraining. To ensure consistency with FIM in the long context training phase, precautions are taken to restrict its application within individual files, thus preventing the introduction of unrealistic scenarios into the training objective.
Fine-tuning and Alignment
After completing pre-training, the model’s abilities are further enhanced through a fine-tuning stage, which involves both Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
For SFT, publicly available datasets such as OpenHermes, Code Feedback, and CodeAlpaca are utilized, providing approximately 500,000 training samples post-dedication.
Following SFT, DPO is applied, leveraging a dataset of approximately 7,000 samples curated from UltraFeedback and Distilabel Capybara DPO-7k Binarized. To ensure model safety, samples related to code are filtered using an LLM-based approach, and additional datasets like Helpful and Harmless RLFH are included.
Results
The main benchmark used for comparison is the model’s proficiency in code completion tasks, which is crucial for assessing its practical applicability in code-related contexts. They use the Multi-PL benchmark as the standardized evaluation metric for these assessments.
The image below shows the performance of Code Instruct 3B versus other similar instruction-tuned LLMs with 3B parameters.
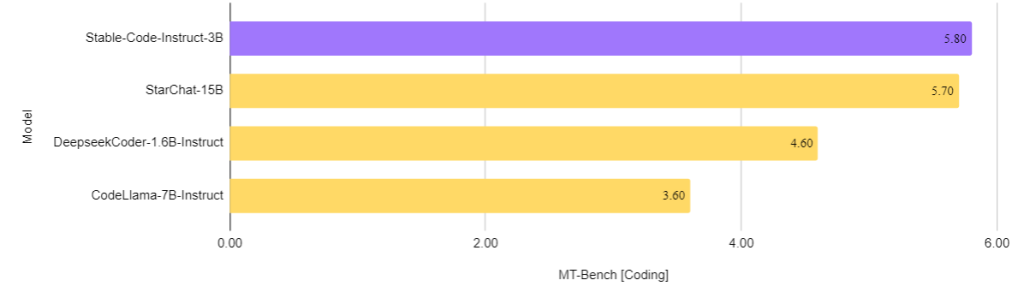
They also evaluated instruction-tuned models on the code subset of the challenging Multi-turn benchmark (MT-Bench). The image below shows the results of coding questions in MT-Bench.
Another important application for code language models is database query tasks. For this, they compared the performance of Stable Code Instruct 3B against other popular instruction-tuned models and models specifically trained to perform well in SQL.
They use the benchmark created by Defog AI to evaluate the models. The results are shown in the table below.

Examples
Let’s test Code Instruct 3B through HuggingFace. You will see an interface that looks like this:
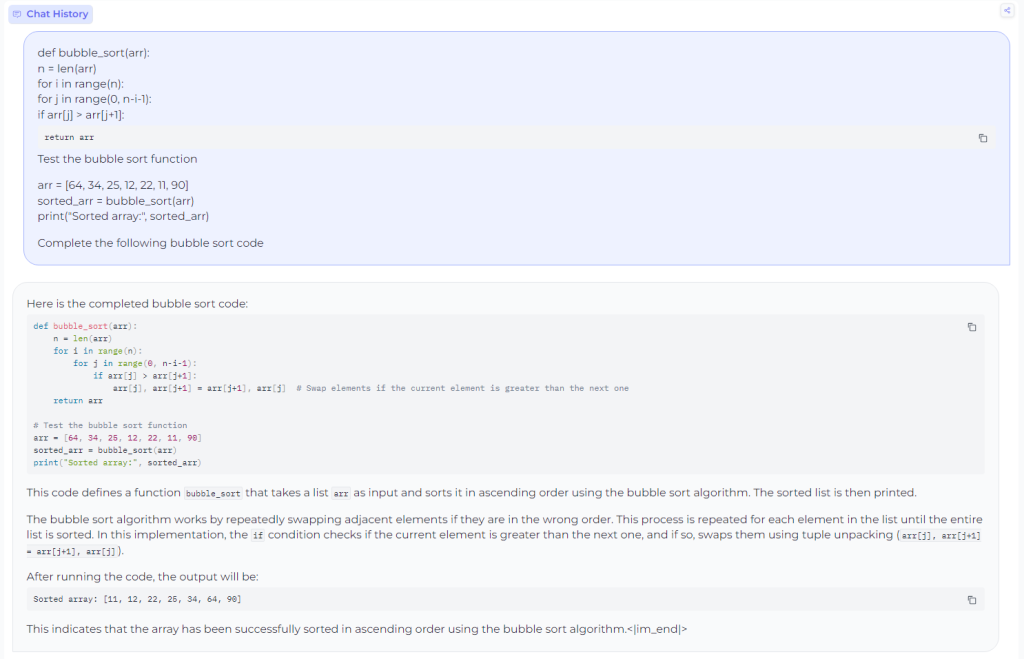
Prompted the model to complete the code for the bubble sort algorithm. Here, the model successfully performs FIM (Fill in the middle):
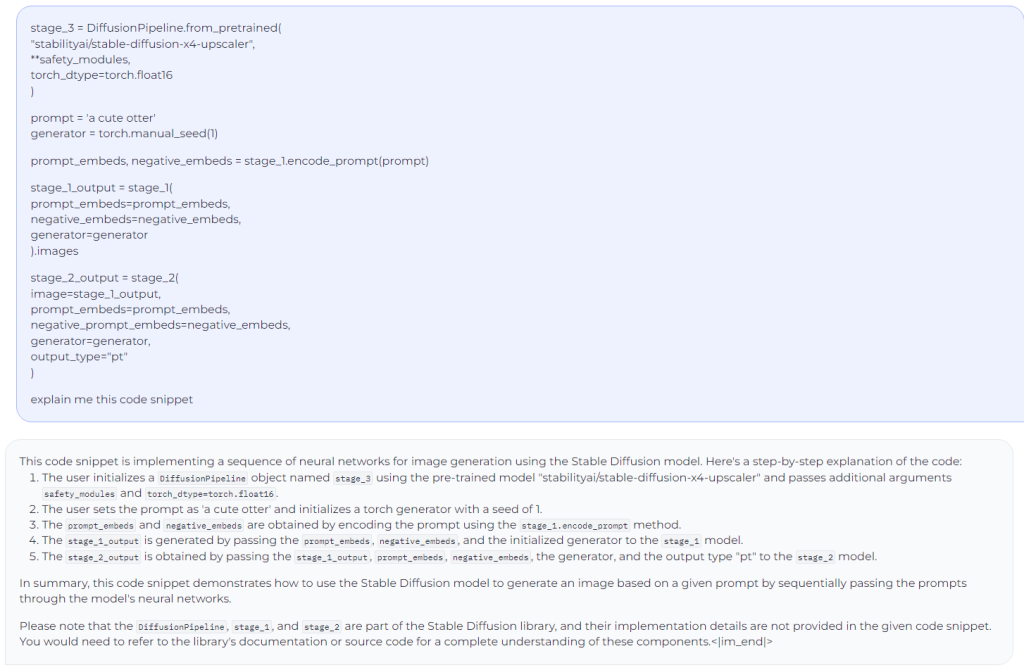
Prompted the model to explain a code snippet:
Prompted the model to complete an incomplete SQL code:
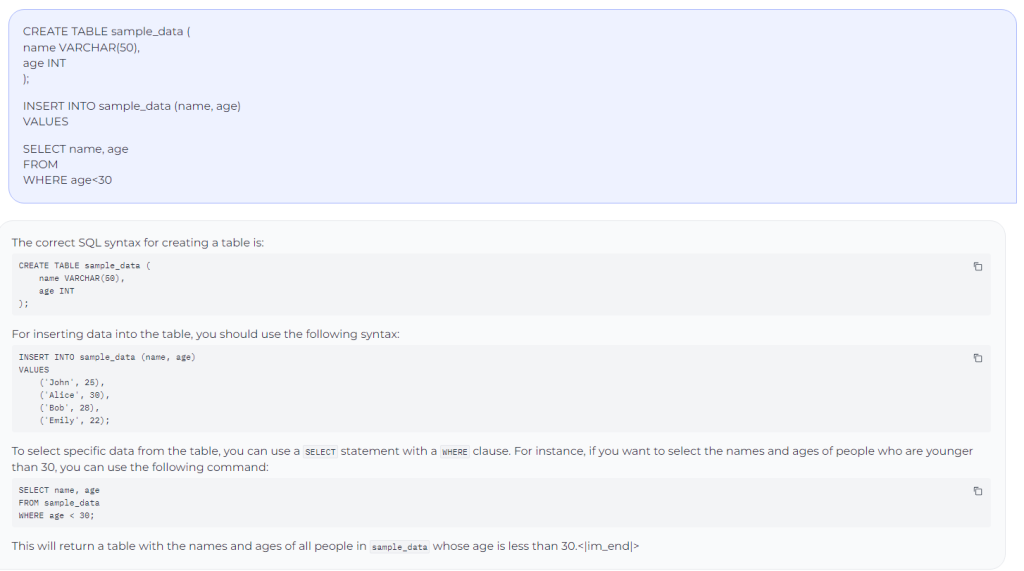
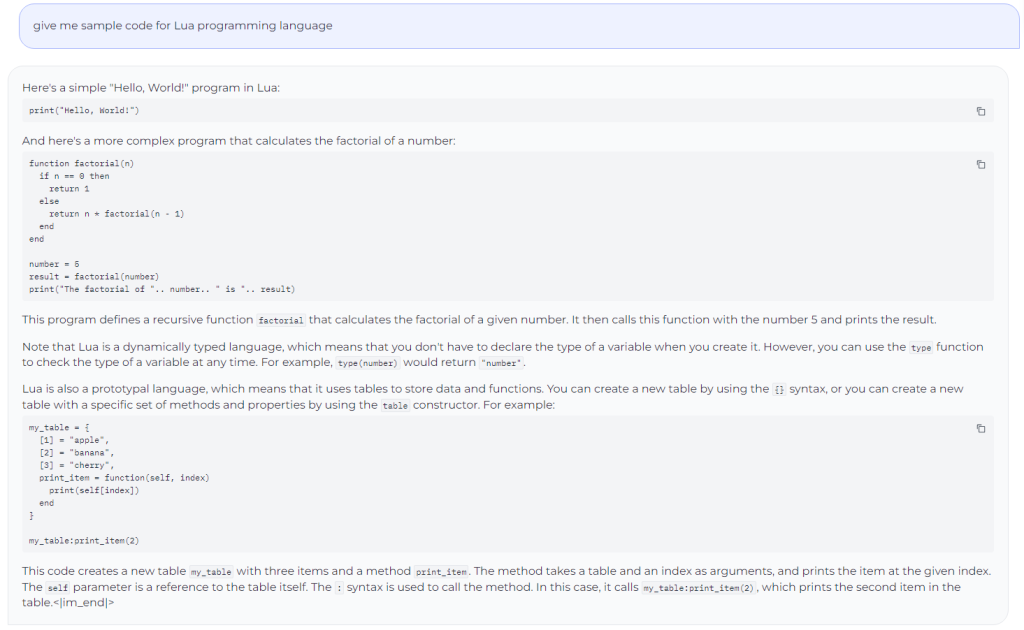
Stable Code Instruct 3B delivers strong test performance even in languages that were not initially included in the training set, such as Lua. The example below shows how the model can provide a simple code in the Lua language.
This proficiency may stem from its understanding of the underlying coding principles and its ability to adapt these concepts across diverse programming environments.
Conclusion
Stable Code Instruct 3B represents a significant advancement in instruction-tuned Code Language Models, excelling in code generation, FIM (Fill in the middle) tasks, database queries, translation, explanation, and creation.
Its instruction comprehension enables diverse coding tasks beyond completion, with superior performance across standard benchmarks promising transformative impacts in the field of software engineering.




