



AI models are going smaller in size but better in performance. First, DeepSeek shook this industry, but now Google has joined the revolution with Gemma 3. Maybe AI models don’t require a big data center to run, maybe a single GPU is enough!
Google launches Gemma 3
Gemma 3 is the latest addition to Google’s lightweight and open-source family of AI models designed to run directly on laptops and smartphones.
This is because of its design as a single-accelerator model, which is capable of running efficiently on just one GPU or TPU. Other LLMs require multiple accelerators to function effectively, limiting their accessibility.
It comes in 4 sizes: 1B, 4B, 12B, and 27B (B = Billion) parameters. People were already impressed with Gemma 2 2B and now this upgraded LLM will give a big boost to this family of AI models.
In the default state, it can support over 35 languages, and can be trained for more than 140 languages worldwide. Developers can use this model to build more intelligent applications as it can analyze images and short videos too (except only for 1B model).
According to the official Google blog, Gemma 3 offers a 128,000 tokens context window, as well as supports function calling. This is quite larger than its predecessor Gemma 2, which had only 8,192 tokens context window. A larger context window enables AI models to understand and process longer pieces of text, leading to more coherent and relevant responses.
Gemma 3 vs DeepSeek
On the LMArena leaderboard, it has outperformed Llama-405B, DeepSeek-V3, and o3-mini by human evaluators:
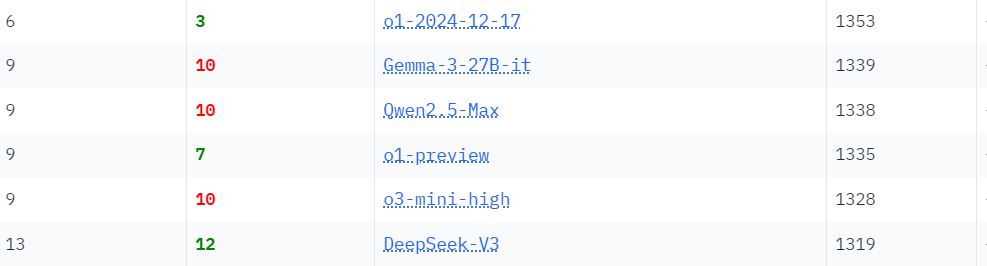
However, it didn’t beat DeepSeek R1 but came quite close on the Elo score:
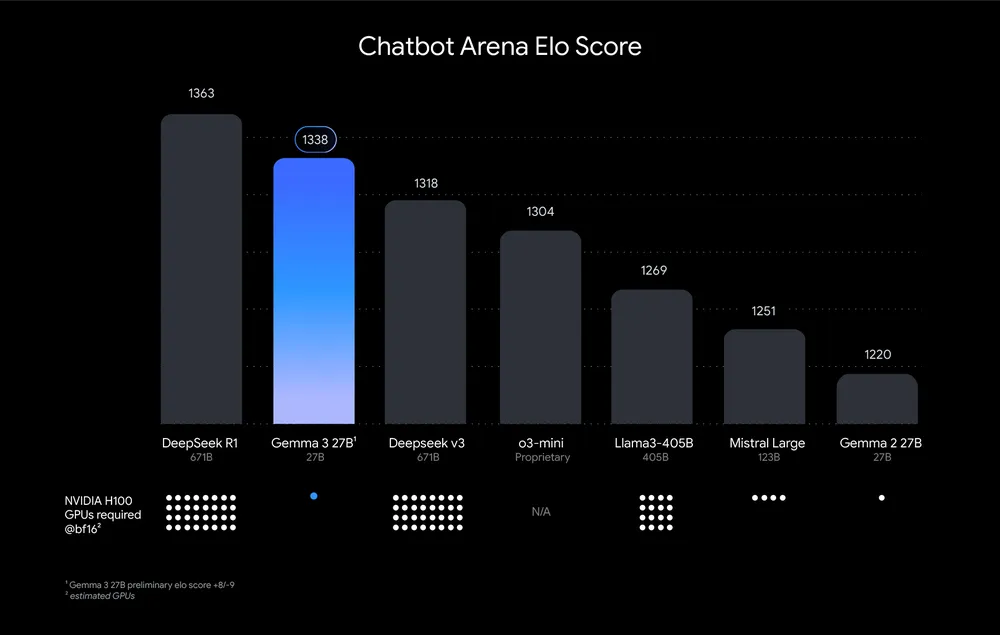
Gemma 3 27B achieved an Elo score of 1338, where DeepSeek’s R1 stands at 1,363. But the key point to note is that this performance is achieved while Gemma was running on a single GPU (1 NVIDIA H100 GPU). On the other hand, DeepSeek’s R1 requires substantially more computational power (32 NVIDIA H100 GPU).
Note that Google’s model also defeats Meta’s Llama 3’s Elo score. Llma 3 is using 16 such GPUs.
All this is achieved using distillation. In this AI process, scientists extract trained weights from larger models and insert them in smaller models to improve the performance to power ratio.
On a side note, it also raises some questions on NVIDIA. The more power efficiency the AI models become, the demand for high-end GPUs will decrease. The industry’s need for chips will shift in a different direction if this trend continues.
Also, on the MMLU-Pro benchmark, Gemma 3 27V scored 67.5%, where Claude 3.5 Haiku stands at 63% and OpenAI’s GPT-4o Mini is at 65%.
These models are available through Google AI Studio, Kaggle, and Hugging Face.
Some Real-World Examples
Here are some examples where users tested this model and how it compares to other LLMs:
Prompt: Create an SVG image of a rocket landing on Mars
— Iurii Alekseev (@iurii_alekseev) March 12, 2025
Left: Claude 3.7 Sonnet Thinking
Right: Gemma 3 27B
🤯🤯🤯 pic.twitter.com/9Haly44JaP
It did a great job here, but it failed in the bouncing ball test:
just tried the new Gemma 3 (27B) on the Hexagon Bouncing Ball test, it didn’t go great but understandable for its size
— Flavio Adamo (@flavioAd) March 12, 2025
Soon enough, small models will be just as good as today's best pic.twitter.com/Wyj4scvI7q
Takeaways
In addition to these new multimodal models, Google has unveiled ShieldGemma 2, a 4-billion-parameter model, designed to enhance image safety by detecting harmful content, including sexually explicit material, dangerous content, and violence.
Overall, Gemma 3 isn’t just another AI Model: it’s a powerhouse in a compact size.




