



Since data science is evolving all the time, it can’t be expected that one will know it all and have it all memorized. Especially if some of this knowledge you use, let’s say, every several months or a year. So, Here’s where a cheat sheet come into the picture. Today, we will provide you with 8 Data Science Cheat Sheets to help you remember basic terminologies and key stuff for everyday work.
What do we mean by Data Science Cheat Sheets?
Data science cheat sheets are concise guides that summarize key concepts, methods, tools, and techniques used in data science for quick reference. They can help data scientists and analysts to quickly recall important information without needing to delve into more detailed resources.
Here’s what you might find in a data science cheat sheet:
- Programming Languages
- Python: Key libraries like NumPy, Pandas, Matplotlib, Seaborn, and scikit-learn.
- R: Important functions and libraries for statistical analysis, data manipulation, and visualization.
- SQL: Common commands and query patterns for database interaction.
- Statistical Methods
- Probability distributions
- Hypothesis testing
- Descriptive statistics
- Inferential statistics
- Machine Learning
- Algorithms: Linear regression, decision trees, random forests, SVM, k-means clustering, etc.
- Model evaluation metrics: Accuracy, precision, recall, F1 score, ROC curve, etc.
- Cross-validation techniques
- Hyperparameter tuning
- Data Preprocessing
- Data cleaning techniques
- Handling missing data
- Feature scaling (normalization and standardization)
- Encoding categorical variables
- Data Visualization
- Types of plots (bar charts, histograms, scatter plots, box plots, etc.)
- Plotting functions from libraries (e.g., plt.plot() from Matplotlib, sns.histplot() from Seaborn)
- Big Data Tools
- Hadoop ecosystem: HDFS, MapReduce
- Spark: RDDs, DataFrames, MLlib
- Deep Learning
- Neural network architectures: CNNs, RNNs, LSTMs
- Frameworks: TensorFlow, Keras, PyTorch
- Key concepts: Activation functions, loss functions, backpropagation
- Mathematical Foundations
- Linear algebra: Vectors, matrices, eigenvalues
- Calculus: Derivatives, integrals (as they apply to machine learning algorithms)
- Optimization techniques
- Tools and Frameworks
- Jupyter Notebook: Commands and shortcuts
- Git: Common commands
- Docker: Basic commands and usage
8 Useful Data Science Cheat Sheets
Here are 8 Data Science Cheat Sheets that you should have as references for your Data Science projects. These will help you stay ahead of your time and be optimal in your Data Science functionalities.
1. Data Structures Reference
The Data Structures Reference cheat sheet from Interview Cake provides a concise overview of common data structures, their use cases, and their performance characteristics.
The cheat sheet is a useful reference for understanding the properties, strengths, weaknesses, and use cases of key data structures. It can help you make informed decisions when choosing the right data structure for a particular problem.
The Cheat Sheet provides a lot of information on basic data structures such as Arrays, Linked Lists, Stack, Queues, Trees, Binary Search Trees and much more. It also contains example diagrams to explain each Data Structure in detail.
Example Content from the Cheat Sheet:

It is a great resource for fast reference since it provides a concise definition and visual representation of each data structure. You can click on any data structure to gain additional information about it, including its advantages and disadvantages, an explanation of how to add and remove data, and a list of its unique features.
2. Pandas Cheat Sheet for Data Science
The Pandas Cheat Sheet for Data Science from DataScientyst provides a quick reference to essential Pandas functionalities for data manipulation and analysis. Pandas is a powerful data manipulation library in Python, and this cheat sheet summarizes key commands and operations in a user-friendly format.
This reference sheet provides you with the codes for the primary pandas commands along with an explanation of what each code will yield. Data structures, importing and exporting data, inspecting it, and selecting are among the subjects covered.
Additionally, you will learn how to apply functions, sort, filter, group, convert, merge, and concatenate data, as well as add and remove rows and columns. Every topic has an understandable graphical representation.
Example Content from the Cheat Sheet:
#Apply function to DataFrame
def calc(x):
return x + 1
df.apply(calc, axis = 1)
#Create new DataFrame
df = pd.DataFrame(
{'col_1': [11, 12, 13],
'col_2': [21, 22, 23],
'col_3': [31, 32, 33]},
index=[0, 1, 2])The Pandas cheat sheet provides a handy summary of the most commonly used Pandas functions and methods, making it a valuable resource for data scientists and analysts working with data manipulation and analysis. By using this cheat sheet, you can efficiently handle, clean, and analyze data using Pandas.
3. Data Visualization Cheat Sheet
The Data Visualization Cheat Sheet from BioSci Global offers a quick reference for creating various types of data visualizations using common Python libraries, particularly Matplotlib and Seaborn. It covers how to create and customize different types of plots and graphs for effective data presentation.
An excellent summary of the graphs used in data visualisation is provided. Every type of chart has a brief description next to it along with an image that illustrates it so you can quickly see how each graph would appear.
Example Content from the Cheat Sheet:
#importing libraries
import matplotlib.pyplot as plt
import seaborn as sns
#line plot
plt.plot(x, y)
plt.xlabel('X-axis label')
plt.ylabel('Y-axis label')
plt.title('Title of the Plot')
plt.show()
#scatter plot
plt.scatter(x, y)
plt.xlabel('X-axis label')
plt.ylabel('Y-axis label')
plt.title('Scatter Plot')
plt.show()The Data Visualization Cheat Sheet is a practical resource for creating and customizing a wide variety of plots using Matplotlib and Seaborn. It helps you understand the essential functions and methods for effective data visualization, ensuring your data is presented clearly and informatively. This cheat sheet serves as a quick reference for visualizing data trends, distributions, relationships, and summaries, essential for data analysis and presentation.
4. Data Wrangling With Pandas Cheat Sheet
The Data Wrangling with Pandas Cheat Sheet from the official Pandas documentation is a comprehensive guide for using Pandas to manipulate and analyze data. It covers the core functionalities of the library, providing quick references to common operations. Here’s a detailed breakdown of what the cheat sheet includes:
It is a Step-by-step guide that is completely devoted to data wrangling.
Some of the areas of interests are how to create DataFrames, method chaining, modification of data based on the DataFrames shape, working on rows and columns, using queries, summarizing and grouping data, working on missing data, using Windows to make new columns, combining DataFrames, using Windows techniques, and plotting.
In each topic, basic figures are given and introduced shortly, and every pandas keyword is demonstrated by the code and the result.
Example Content from the Cheat Sheet:
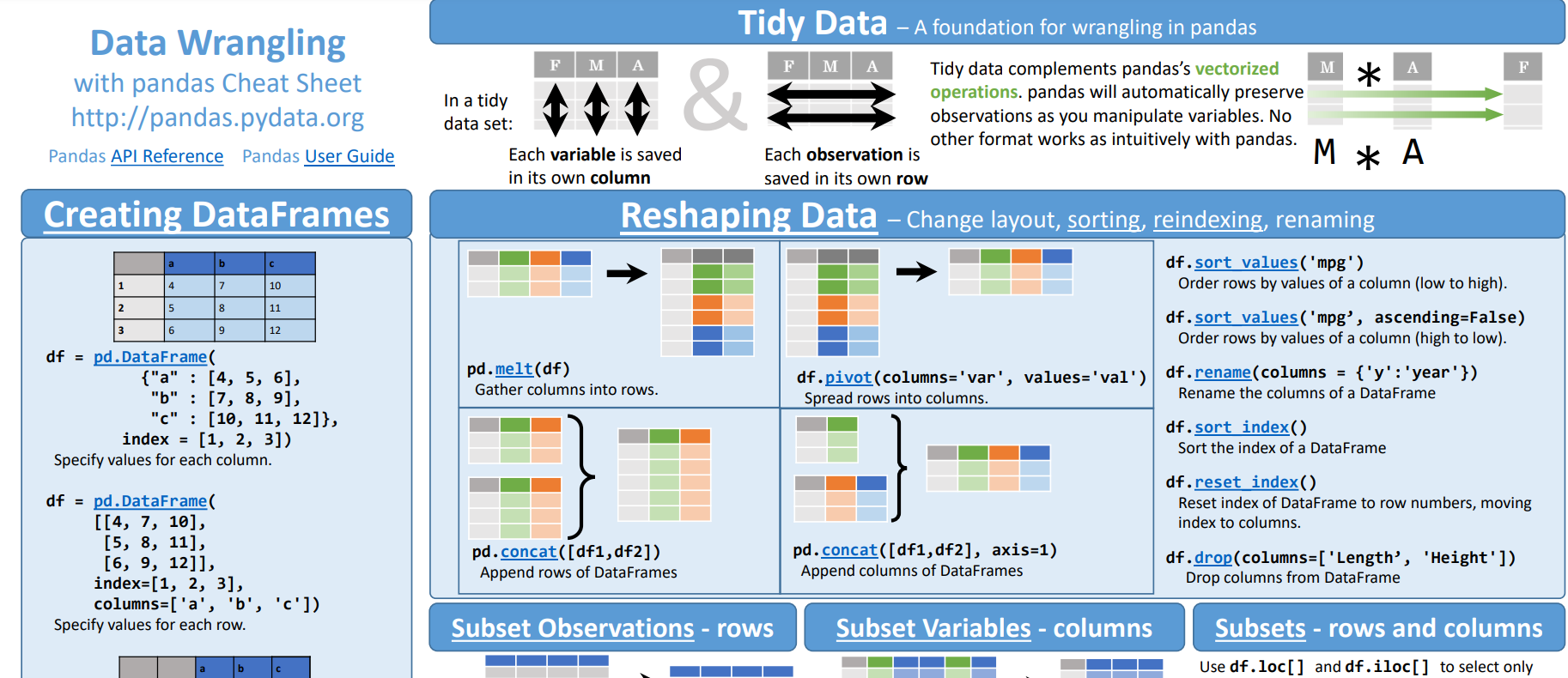
The Data Wrangling with Pandas Cheat Sheet provides a concise overview of essential Pandas functionalities for manipulating, cleaning, and analyzing data. This includes creating data structures, inspecting and selecting data, cleaning and transforming data, aggregating and merging datasets, working with dates, pivoting and reshaping data, and plotting.
It also covers input/output operations and configuration settings. This cheat sheet serves as a practical reference to streamline data wrangling tasks in Pandas.
5. A Comprehensive Statistics Cheat Sheet for Data Science Interviews
The Comprehensive Statistics Cheat Sheet for Data Science Interviews by StrataScratch provides a quick guide to key statistical concepts and methods frequently tested in data science interviews. This cheat sheet aims to give data science candidates a handy reference for fundamental statistical topics that are essential for solving real-world data problems and acing interviews.
Many of the topics a data scientist would require when handling statistics are captured in this cheat sheet. These are probability basics, A/B test, simple linear regression, combinations/permutations, Bayes theorem, Normal (Z) & T Distribution, confidence intervals, and hypothesis testing. All of these ideas come with clear examples that are accompanied by examples, formulas, and graphs.
Example Content from the Cheat Sheet:

#ANOVA test using the f_oneway() function from the scipy.stats library
from scipy.stats import f_oneway
# load the 'iris' dataset
iris = sns.load_dataset('iris')
# perform the ANOVA test
setosa_petal_length = iris[iris['species'] == 'setosa']['petal_length']
versicolor_petal_length = iris[iris['species'] == 'versicolor']['petal_length']
virginica_petal_length = iris[iris['species'] == 'virginica']['petal_length']
f_statistic, p_value = f_oneway(setosa_petal_length, versicolor_petal_length, virginica_petal_length)
# print the results
print('F-statistic:', f_statistic)
print('p-value:', p_value)The Comprehensive Statistics Cheat Sheet for Data Science Interviews is a valuable resource for preparing for interviews by summarizing key statistical concepts and methods. It covers descriptive statistics, probability theory, inferential statistics, regression analysis, classification metrics, key distributions, and exploratory data analysis (EDA).
By understanding and mastering these concepts, candidates can effectively analyze data, build models, and interpret results, essential for success in data science roles.
6. Cheat Sheet for Machine Learning Models
The Cheat Sheet for Machine Learning Models from Analytics Vidhya offers a concise overview of key machine learning models used in classification, regression, clustering, and dimensionality reduction. It outlines the purpose, key characteristics, advantages, and limitations of each model, providing a quick reference for data scientists and machine learning practitioners.
The Cheat Sheet is a comprehensive reference page on machine learning algorithms. The explanations are thorough and include, above all, the methods involved in creating each algorithm as well as examples.
The author discusses the following subjects: principal component analysis (PCA), linear discriminant analysis (LDA), processing text data, ROC curve, support vector machine (SVM), random forest, multiple linear regression, decision tree regression, logistic regression, naive Bayes classifier, evaluating the performances of binary classifiers, and more.
Example Content from the Cheat Sheet:

The Cheat Sheet for Machine Learning Models provides an essential guide to various machine learning algorithms. It covers the purpose, characteristics, advantages, and limitations of classification, regression, clustering, and dimensionality reduction models.
This cheat sheet serves as a quick reference for selecting appropriate models based on specific data science tasks, helping practitioners apply these models effectively to solve real-world problems.
7. Python Cheat Sheet
Python is, for a reason, translated as one of the most preferred programming languages for data science. It is superior in all the domains that are deemed pertinent. And it does it all from data ingestion and cleaning or statistical computation and data visualization to model building of machine learning and model deploying of pre-made programs to automation.
The Python Cheat Sheet by WebsiteSetup.org provides a quick reference for key Python programming concepts, syntax, and functions. It covers a broad range of topics, from basic syntax to more advanced features of the Python language, making it useful for both beginners and experienced programmers.
This extremely thorough and easily understandable cheat sheet is ideal for anyone looking to get a foundation in Python work. It describes the primary Python data types, how to create and store strings, and how to perform mathematical operations on data. Additionally, you will discover how to create functions, lists, tuples, dictionaries, and built-in functions.
Example Content from the Cheat Sheet:
#Change Item Value
#Change the "year" to 2020:
new_dict= {
"brand": "Honda",
"model": "Civic",
"year": 1995
}
new_dict["year"] = 2020
#Loop Through the Dictionary
#print all key names in the dictionary
for x in new_dict:
print(x)
#print all values in the dictionary
for x in new_dict:
print(new_dict[x])
#loop through both keys and values
for x, y in my_dict.items():
print(x, y)The Python Cheat Sheet provides a comprehensive overview of the essential Python programming constructs, including syntax, data structures, control flow, functions, modules, file handling, error handling, and object-oriented programming. This cheat sheet is a quick reference guide that helps developers recall and apply fundamental Python concepts effectively in their coding projects.
8. Top Prediction Algorithms
The Dataiku blog post on machine learning algorithms provides an in-depth look at various prediction algorithms commonly used in data science and machine learning. The cheat sheet given here covers both the general algorithms most commonly applied and the general ideas of machine learning.
Such machine learning techniques are neural network, decision trees, random forest, gradient boosting, and the logistic as well as linear regression models. It is very effective when an infographic of each of the algorithm’s strengths and weaknesses is provided.
Example Content from the Cheat Sheet:

Each of these algorithms has its own strengths and weaknesses, and the choice of algorithm depends on the specific problem and dataset characteristics. The blog also emphasizes the importance of understanding the underlying assumptions and appropriate use cases for each algorithm to make the most effective use of them in machine learning projects
Conclusion
These Data Science Cheat Sheets have been chosen selectively and researched upon based on the type of content they provide on various aspects of the Data Science field.




