



Generative AI Tools know all about our world, but how? They were trained on public data from the Internet. But can they somehow access private content that is behind paywalls? Can they read it? New research suggests they can.
New Evidence: ChatGPT was trained on O’Reilly Books
Researchers were set out on a mission to uncover whether non-public content from O’Reilly Media books was sneakily included in OpenAI’s training data. They used a DE-COP membership inference attack designed in 2014 to detect copyrighted content. The results were shocking!
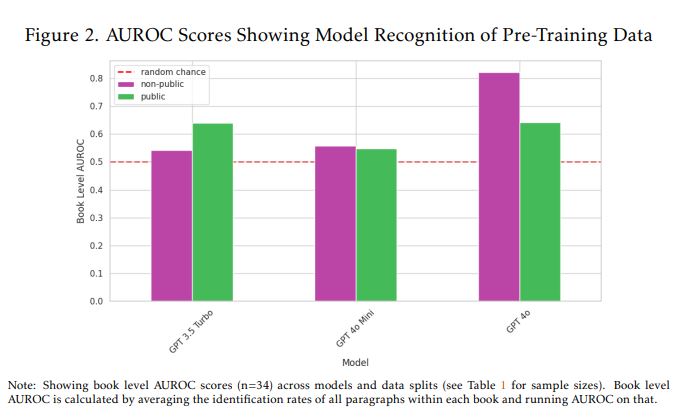
OpenAI’s GPT-4o model scored 82% AUROC on non-public, paywalled content. It was much higher than random guessing. This suggests that GPT-4o was trained on the premium content from O’Reilly.
However, GPT-3.5 Turbo (the older ChatGPT model) didn’t show any pattern to indicate stealing of copyrighted content.
O’Reilly Media isn’t any small publisher. They are known for many popular technical books. They offer both public content as well as paywalled books that are very high-quality. Founded in 1978, the company’s current estimated annual revenue is up to $500 million.
While the study focuses on O’Reilly Media books and ChatGPT models, it raises concerns that similar practices could be widespread across the AI industry, potentially harming the broader ecosystem of digital content.
What did the new Research Paper find?
The study aims to determine if non-public content from O’Reilly books was included in the training data of OpenAI’s models, particularly comparing older models (GPT-3.5 Turbo) with more recent ones (GPT-4o and GPT-4o Mini). Tim O’Reilly was also part of this research.
AI models like ChatGPT need vast amounts of data to learn language patterns, context, and reasoning. Training on diverse sources also improves adaptability, making AI useful for conversations, coding, and creative writing.
O’Reilly books typically have two sections: publicly accessible preview content and non-public content behind a paywall. The preview is just the first 1,500 characters of each chapter as well as the entirety of chapters one and four. This unique split allows researchers to check if models are recognizing content they shouldn’t have seen during training.
The researchers used a legally obtained dataset of 34 copyrighted O’Reilly Media books. They split the content into:
- Public text: Excerpts (e.g., first 1,500 characters of chapters) made freely available.
- Non-public text: The remainder of the text that is paywalled.
They employed a method where the model is given a multiple-choice quiz. For each paragraph from the books, the model has to identify which option is the original human-authored text among paraphrased alternatives generated by another model (Claude 3.5 Sonnet).
By comparing the model’s performance on texts published before the training cutoff (potentially seen) versus texts published after (definitely unseen), they calculated AUROCscores. An AUROC of 50% closer to 100% suggests strong recognition (i.e., prior exposure in training).
Note that the training cutoff for GPT-4o and GPT-4o mini is October 2024, while it is September 2021 for GPT-3.5 Turbo.
GPT-4o achieved an AUROC score of about 82% for the non-public O’Reilly book content, indicating it recognizes this paywalled material much better than random chance. It was just 64% of the public content.
Here’s the conclusion of the study: “GPT-4o’s high familiarity with O’Reilly Media books likely reflects a deliberate effort by OpenAI to train on the O’Reilly book dataset.“
Takeaways
While one experiment is not the final truth, it does stir up questions about how AI models are trained and where their data comes from. The question is there for transparency. Greater transparency would help content creators receive compensation. While OpenAI is partnering up with many content websites to get content ethically, their past practices will always be a big concern.




