



Stability AI made a major upgrade to its text-to-audio AI model with Stable Audio 2. Here’s what’s coming!
Highlights:
- Stable Audio 2 can now generate up to 3 minutes long at 44.1 KHz stereo using a single prompt.
- The model also has an audio-to-audio generation feature where users can modify samples using text prompts.
- The new model is available on the Stable Audio website for free.
What’s New in Stable Audio 2?
Stable Audio 2 by Stability AI is a text-to-audio AI tool that can make music up to 3 minutes. It enables high-quality, full tracks with coherent musical structure at 44.1 kHz stereo from a single natural language prompt.
Below is an example shared by the company where they generated a 3-minute-long soundtrack using the prompt “Cinematic Synthwave”:
Another major feature in this upgrade is audio-to-audio generation. Users can now combine their upload samples and transform them using with text prompts to further flexibility, control and an elevated creative process.
Here is a demo where the user uploaded their sample and with a single text prompt, additional drum or guitar effects are added:
The improved model is aimed at providing clear structures and high-quality sound. It simplifies complex audio waveforms into shorter, more manageable forms and then reshapes them to create music that tries to capture the essence of human compositions. The goal is for the AI to grasp the nuances of music to replicate the patterns and sequences
Stable Audio 2 was trained exclusively on a licensed dataset from the AudioSparx music library, honouring opt-out requests and ensuring fair compensation for creators. The 1.0 model was also trained using data from Audiosparx which has over 800,000 audio files containing music, sound effects as well as single instrument stems.
How Stable Audio 2 Works?
At its core, Stable Audio 2 leverages diffusion transformer technology (DiT), following the same approach as Stability AI’s upcoming Stable Diffusion 3 image generator, representing a shift from its previously adopted U-Net technology.
DiT and U-Net are both common architectures used in machine learning, but DiT is designed to refine random noise into structured data incrementally, making it particularly effective at handling long data sequences. U-Net, by contrast, focuses on accuracy for short generations but is less capable of handling longer, more complex sequences.
How to use Stable Audio 2?
Stable Audio 2 is available for free on the Stable Audio website. It will soon be available on Stable Audio API.
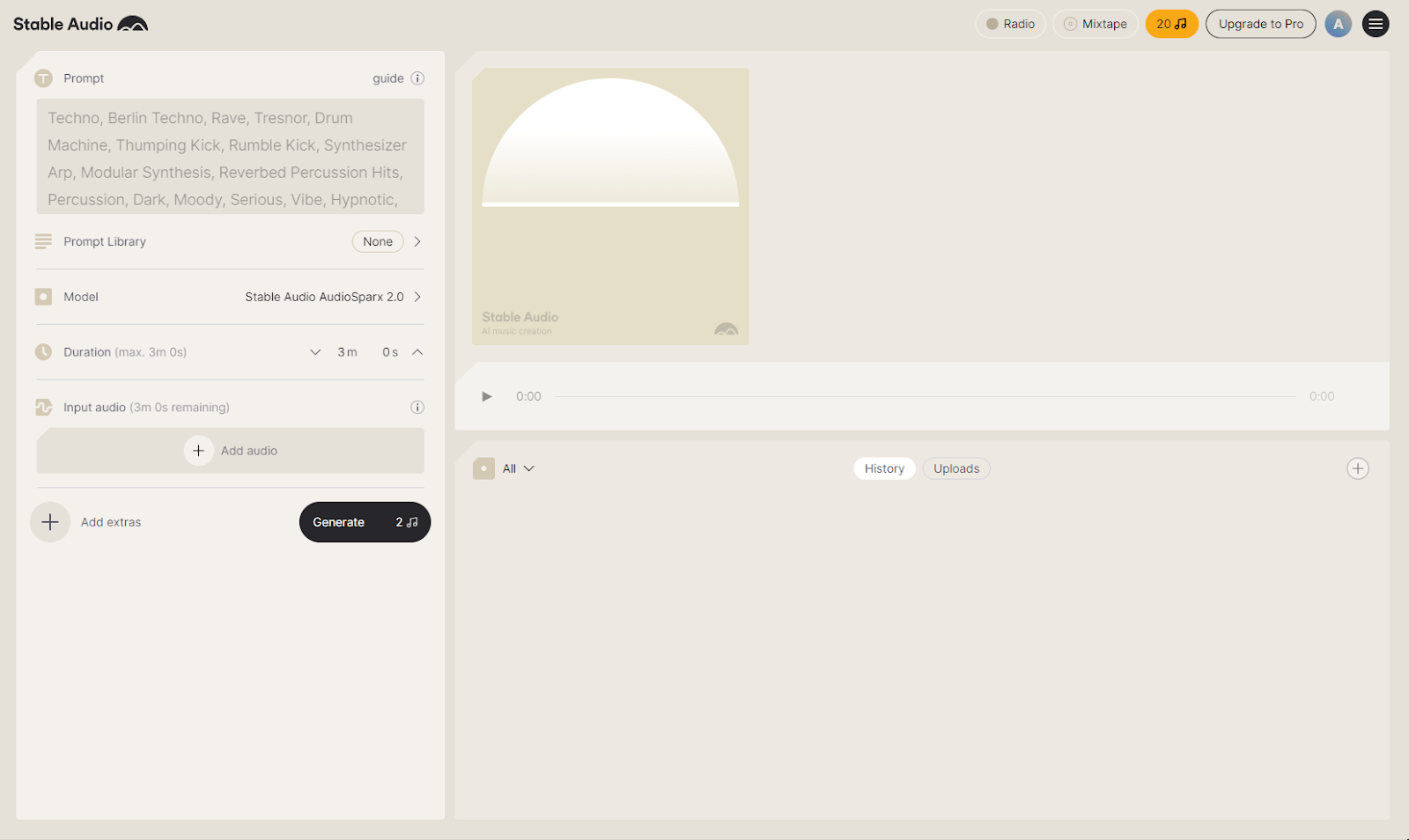
Stable Audio can be accessed through this web interface. Just sign up and prompt it! They have a prompt library which is a good starting point to start with. Each free account receives 20 free credits a month for an AI music generation. Note that Stable Audio 1 requires 1 credit and Stable Audio 2 requires 2 credits.
Comparison with Stable Audio 1
We tested both versions of stable audio with the same text prompt: “Create a chill, melodic downtempo instrumental with warm piano, mellow electric guitar, subtle bassline and light percussion textures like shakers and cymbals. The vibe should be introspective and dreamy.”
This was the output from version 1:
This is a sample generated with the following prompt using stable audio 1.0
— Kaustubh Saini (@kaustubh_saini) April 3, 2024
"Create a chill, melodic downtempo instrumental with warm piano, mellow electric guitar, subtle bassline and light percussion textures like shakers and cymbals. The vibe should be introspective and… pic.twitter.com/LK86ikjc0n
This was the output from version 2:
using the same prompt on stable audio 2.0, I found the generated audio to be much more detailed and consistent with the prompt. pic.twitter.com/oOGtt7FyMO
— Kaustubh Saini (@kaustubh_saini) April 3, 2024
Version 2 had a much more cohesive and detailed generation incorporating all specified elements of the prompt pleasingly and consistently.
Stability AI is becoming a big player in the AI space with tools like Stable Video 3D, Stable Diffusion 3, and Stable Code Instruct 3B.
Conclusion
Stable Audio 2 has massively improved on the capabilities of its earlier version as well as giving tough competition to engines like Suno. The fact that a user can whistle a simple tune and with the help of prompts turn it into a detailed track is its trump card and the reason it’s better than most audio engines out there.




