



ChatGPT and other AI models are great for generating sales reports, summarising documents, and writing code. But is it that good? A new study published in IEEE Transactions on Software Engineering generated some interesting results.
Highlights:
- The study shows how efficient ChatGPT is at generating code with evaluation based on code functionality and security.
- ChatGPT performs better at Code Generation but is not so impressive at debugging or fixing errors.
- Further research or more training with coding datasets can help make ChatGPT perfect for coding.
This all came just a few weeks after a previous study showed that about half of the coding answers from ChatGPT were found wrong.
Deep Dive inside how Good ChatGPT is for Coding
Research assessing the functionality, complexity, and security of the code generated by OpenAI’s ChatGPT has been published recently. To analyze its coding capabilities, a group of researchers conducted several tests.
Specifically, for the code generation task, the researchers used 18 CWEs with 54 code scenarios from the LeetCode platform and 728 algorithm challenges in five different languages (C, C++, Java, Python, and JavaScript).
Through this study, the researchers wanted to get answers to the following questions across these topics:
- Functionally accurate Code Generation: Does ChatGPT produce functionally accurate code?
- Multi-round Fixing for Code Generation: To what extent does the multi-round fixing procedure enhance the functional correctness of code generation?
- Code Complexity: How complicated is the code that ChatGPT generates?
- Generation of Security Code: Is the code produced by ChatGPT secure?
- ChatGPT’s nondeterminism: What impact does ChatGPT’s nondeterministic output have on code generation?
The study evaluation includes a thorough examination of the code samples produced by ChatGPT, with particular attention paid to three crucial factors: security, complexity, and correctness.
Furthermore, ChatGPT’s capability to engage in a multi-round repair process of aiding code development (i.e., ChatGPT’s dialogue capacity, user chatting, and ChatGPT for fixing generated flawed code), was explicitly studied.
The Code Generation Workflow
In this approach, the researchers create a prompt that is appropriate for the provided CWE scenario or LeetCode problem (i.e., one CWE’s code scenario) and send it to ChatGPT.
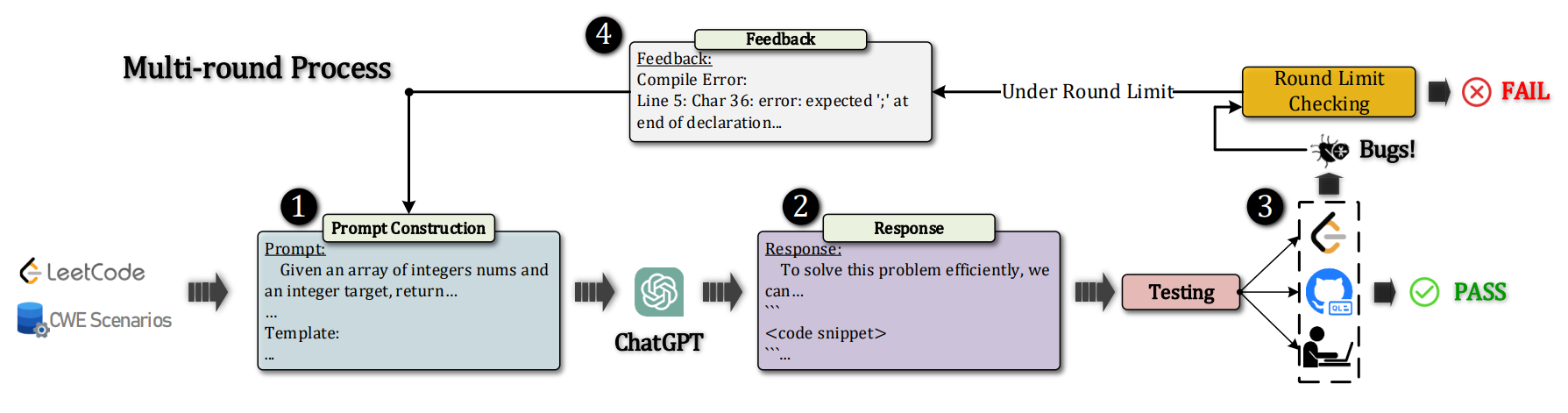
Based on the prompt from the current round and the context of the previous round’s conversation (the first round lacks the prior round’s conversation context), ChatGPT generates a response.
Next, the researchers used CodeQL (with manual analysis) to find CWE vulnerabilities and LeetCode online judgment to assess the produced code’s functional reliability. This was important to assess the response made by ChatGPT on several aspects.
Here, the code generation process is terminated if the testing outcome is successful, if all test cases pass or if no vulnerabilities are found. If not, the produced code snippet has errors (such as compile errors).
Suppose the number of rounds in the dialogue or conversation with ChatGPT does not surpass the round limit (for example, the maximum round number of 5). In that case, the researchers employ the input from LeetCode and CodeQL to rework a new prompt, which is then fed into ChatGPT for a fresh round of code production.
The code generation is considered unsuccessful if the testing is continuously unsuccessful and the conversation’s round number exceeds the round limit.
This entire process including multiple rounds in the conversation is called the multi-round (fixing) process. Here, finding the ideal prompt to maximize ChatGPT’s performance is not the aim of the prompt design.
Rather, the objective is to offer an acceptable prompt that approximates actual usage circumstances, particularly for code creation, which can help prevent overfitting to the specific datasets and prompts.
What did the Results show?
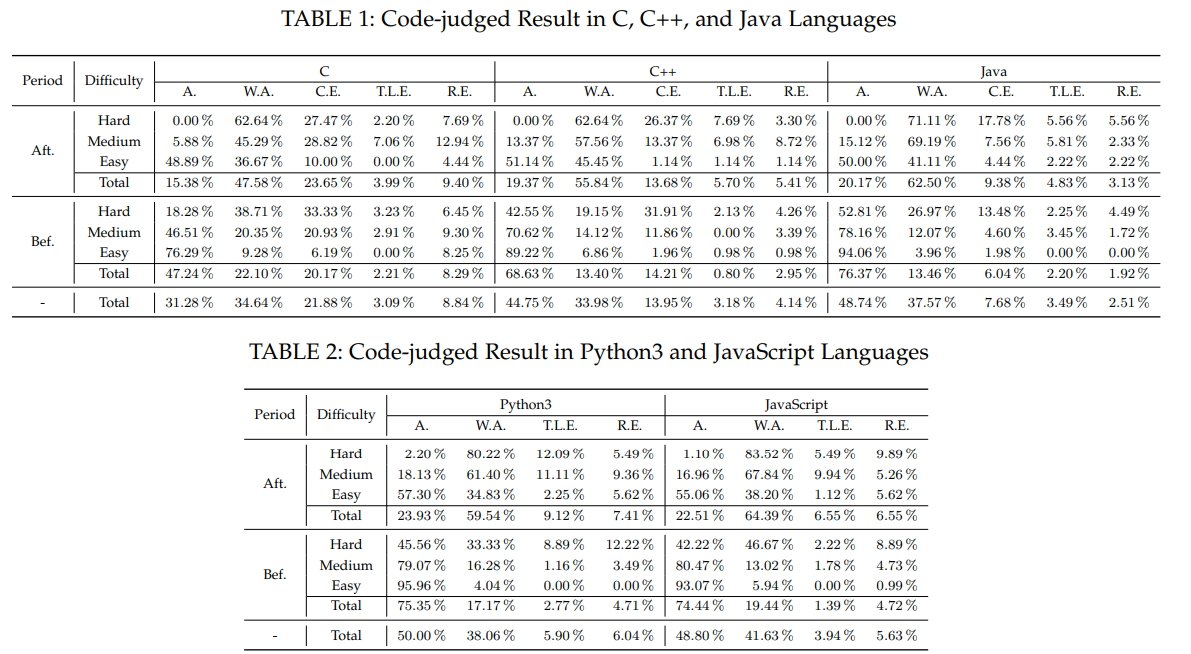
According to the results, ChatGPT’s success rate in producing functional code varies greatly, ranging from as low as 0.66 per cent to as high as 89 per cent, depending on the task’s complexity, the programming language, and a variety of other factors.
The results showed that ChatGPT is better at generating functionally correct code.
Furthermore, it was also found that the multi-round fixing process with ChatGPT typically maintains or raises the complexity levels of code snippets, which could potentially make it harder to understand the code that ChatGPT regularly and automatically generates.
In general, ChatGPT performed admirably when it came to resolving issues in the various programming languages—but particularly when it came to resolving issues with code that was present on LeetCode before 2021.
For example, it generated a working code with success rates of approximately 89, 71, and 40 per cent for easy, medium, and hard challenges, respectively.
“ChatGPT is better at generating functionally correct code for problems before 2021 in different languages than problems after 2021 with 48.14% advantage in Accepted rate on judgment platform”
Research Paper
For instance, after 2021, ChatGPT’s capacity to generate working code for “easy” coding challenges decreased from 89% to 52%. Additionally, after this period, its proficiency in producing workable code for “hard” issues decreased from 40% to 0.66 percent.
Is ChatGPT the Perfect Coding Tool?
Although ChatGPT seems quite efficient in generating code snippets across several languages, its ability to directly fix erroneous code with the multi-round fixing process to achieve correct functionality is relatively weak.
The findings also suggest that ChatGPT might not be able to write code for problems that are unknown or not present in the training dataset, even if those problems make sense to humans.
These results add to the ongoing body of research aimed at enhancing the production of functionally valid code. Of these, enhancing ChatGPT’s code generation stability and alignment with human attention are crucial, particularly for the latter. This is in addition to the need to further strengthen ChatGPT’s logical reasoning ability.
It’s possible that ChatGPT’s code generation method was sloppy, and the code that was produced didn’t fulfil all of the specific requirements stated. As a result, it was challenging to generate or fix (to make it functionally right) using the multi-round fixing procedure.
Therefore, future studies can concentrate on how to give ChatGPT extra valuable information to augment the multi-round fixing process for fixing, like missing features in the code or the correct algorithm logic, or how to create a productive workflow for automatic code production.
Also, developers must supply extra details to aid ChatGPT in comprehending issues or preventing vulnerabilities, as it is quite possible that ChatGPT may not understand coding algorithms and problems not present in its dataset and training.
Conclusion
The study provides a clear picture on where ChatGPT stands in the field of coding and development. We can call it perfectly imperfect. It is quite impressive for basic code generation, however further training and research can make it an immaculate coding tool for developers.




