



Stable Video 3D (SV3D) is something that we need and now we have it! Find out everything about Stable Video 3D by Stability AI, its features, architecture, model training and how to access it!
Highlights:
- Stability AI releases Stable Video 3D, its latest addition to its Stable Video Diffusion model family.
- Comes with 3D video rendering technology providing cutting-edge multi-view features.
- Available to use for both commercial and personal purposes worldwide.
What is Stable Video 3D?
Stability AI announced the release of Stable Video 3D or SV3D, a generative AI model that can render 3D videos, based on Stable Video Diffusion, which the company released back in November last year.
SV3D is said to lay the foundation for advanced 3D technology as it offers enhanced video quality with a three-dimensional view. Here is what they shared in their official release:
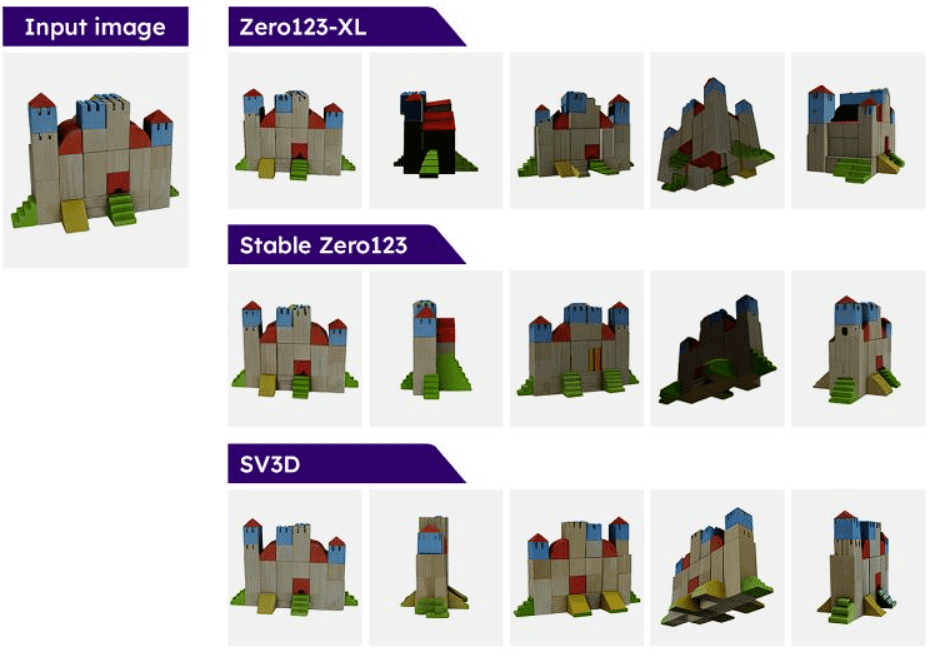
“When we released Stable Video Diffusion, we highlighted the versatility of our video model across various applications. Building upon this foundation, we are excited to release Stable Video 3D. This new model advances the field of 3D technology, delivering greatly improved quality and multi-view when compared to the previously released Stable Zero123, as well as outperforming other open source alternatives such as Zero123-XL.”
According to Stability, this new model has outperformed several previously released models such as Stable Zero123 and Zero123-XL. This goes to show how advanced the cutting-edge technology behind SV3D is.
The artificial intelligence (AI) model generates videos, however, it doesn’t accept text inputs like other well-known video producers like Pika 1.0, Runway AI, and Sora from OpenAI. SV3D’s primary goal is to convert a 2D picture into an orbiting 3D model using the image input.
How to Access Stable Video 3D?
Stability AI has released Stable Video 3D for developers and editors worldwide to enjoy its novel video generation features. For commercial purposes, you can access Stable Video 3D with a Stability AI Membership.
Also, for personal use, you can download SV3D’s model weights from Hugging Face. So go ahead and start deploying SV3D for your projects and developments.
Recently, Stability also partnered with TripoSR to generate 3D objects.
SV3D Variants
SV3D is being released in two variants namely SV3D_u and SV3D_p.
The first variant SV3D_u creates orbital videos from a single image input without any camera conditioning. This will be highly useful for video editors and even photographers who have a hard time getting high-quality video-conferencing with their cameras. You can say goodbye to the need for camera pre-conditioning.
The second variant extends the capability of SVD3_u, as it accommodates both single images and orbital views, allowing for the creation of 3D video along specified camera paths. This is the part where the multi-view feature kicks in. This variant brings a brand-new feature in video generation.
SV3D’s Model Architecture
Stable Video 3D’s model architecture is a key aspect behind its 3D video rendering technology. Let’s look at the architecture, obtained from their research paper, in-depth so that we can get an understanding of its workflow:
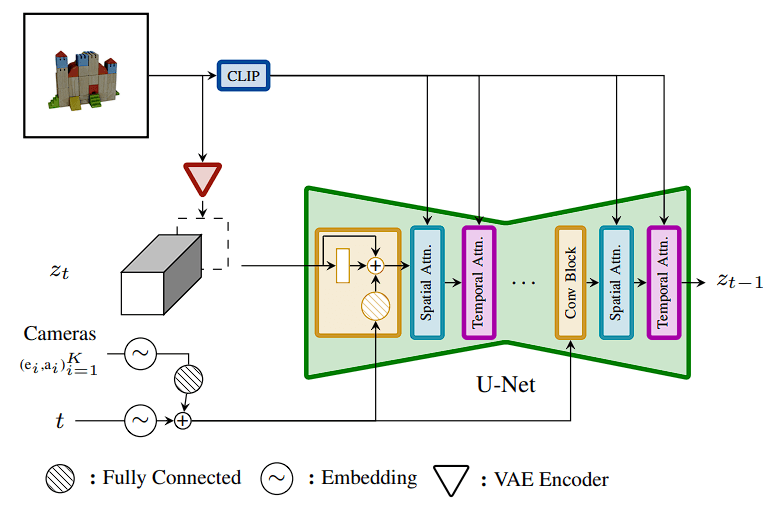
SV3D architecture is based on the Stable Video Diffusion architecture and consists of a multi-layered UNet with two transformer blocks (spatial and temporal) with attention layers and one residual block with Conv3D layers in each layer. Stability made four key advancements to the pre-existing architecture to achieve SV3D.
- The vector conditionings for “fps id” and “motion bucket id” were initially eliminated because they are unnecessary for SV3D.
- After the conditioning image is embedded into latent space by the SVD VAE encoder, it is concatenated to the noisy latent state input zt at noise timestep t to the UNet.
- Each transformer block’s cross-attention layers receive the conditioning image’s CLIP-embedding matrix as their key and value, with the query representing that layer’s feature.
- The final and most crucial stage was feeding the diffusion noise timestep and the camera trajectory into the residual blocks. First, sinusoidal position embeddings containing the noise timestep t and the camera pose angles ei and ai embedded.
Overall, this entire schema allows the camera pose embeddings to undergo a linear transformation, concatenation, and addition to noise timestep embedding. This is passed to each residual block, where it is linearly modified once again to match the feature size before being added to the block’s output feature.
The Technology Behind Stable Video 3D
By exploiting the generalization and multi-view consistency of the video models, SV3D’s state-of-the-art technology adapts the image-to-video diffusion model for new multi-view synthesis and 3D generation, further adding explicit camera control for NVS. Better 3D optimization methods are also included for using SV3D and its NVS outputs for image-to-3D generation.
Stability trained the SV3D model using two brand-new techniques and on multiple datasets. This is what gave rise to the novel technology on hand.
Static vs Dynamic Orbits
By designing both static and dynamic orbits, stability investigated the impacts of camera pose conditioning. The camera revolves around an object in a static orbit at regularly spaced azimuths and the same elevation angle as that of the conditioning image.
The static orbit’s drawback is that, depending on the conditioned elevation angle, it might be difficult to learn anything about the object’s top or bottom.
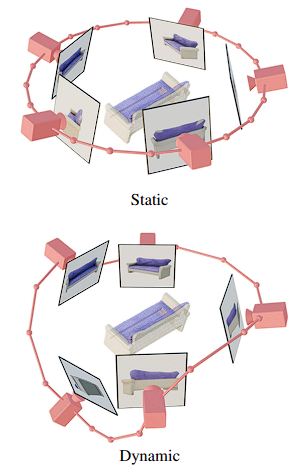
The height can change each view and the azimuths might be unevenly spaced in a dynamic orbit. Stability sampled a static orbit introduced little random noise to the azimuth angles and elevated it using a randomly weighted collection of sinusoids with varying frequencies to create a dynamic orbit.
In addition to ensuring that the camera trajectory loops around to finish at the same azimuth and elevation as those of the conditioning image, this produces temporal smoothness.
Overall, by utilizing video diffusion models, offering the camera trajectory as extra conditioning, and repurposing temporal consistency for spatial 3D consistency of the object, Stability was able to address all three aspects of generalization, controllability, and consistency in novel multi-view synthesis.
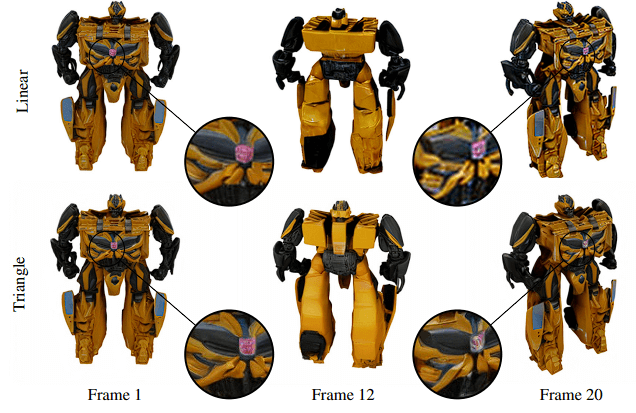
Triangular CFG Scaling
For classifier-free guidance (CFG), SVD employs a linearly increasing scale from 1 to 4 over the generated frames. Nevertheless, this scaling resulted in an oversharpened final few frames in Stability’s constructed orbits.
During inference, Stability suggested using a triangle wave CFG scaling as it produces videos that loop back to the front-view image. It grew CFG linearly from 1 in the front view to 2.5 in the rearview, and then it declined linearly from 1 in the front view to 1.
The image below shows that triangle CFG scaling produces more details in the back view.
Model Training
Stability-trained three image-to-video models that were fine-tuned from SVD. They first trained SV3Du, a pose-unconditioned model that is solely conditioned on a single-view picture, to create a video of a static orbit around an object.
Based on dynamic orbits, the second model, the pose-conditioned SV3Dc, is trained with a sequence of camera elevation and azimuth angles in an orbit, in addition to the input image.
SV3Dp, the third model, was trained by fine-tuning the SVD to generate static orbits unconditionally, followed by additional fine-tuning on dynamic orbits with a requirement on the camera pose.
All three models were later trained on the Objaverse dataset which includes artificial 3D objects with a broad range of variability.
They created 21 frames surrounding each object at a resolution of 576 x 576 pixels and a field of view of 33.8 degrees, using a randomly coloured background. They decided to adjust the SVD-xt model so that it produced 21 frames.
Overall, with an effective batch size of 64, all three models (SV3Du, SV3Dc, and SV3Dp) are trained for 105k iterations total on 4 nodes of 8 80GB A100 GPUs for around 6 days. SV3Dp is trained unconditionally for 55k iterations and conditionally for 50k iterations.
This just goes to show how far SV3D has gone in terms of efficient training and harnessing its 3D video generation capabilities on powerful GPUs.
Advantages or Features of Stable Video 3D
The major feature of Stable Video 3D is the ability to generate Multi-view videos of the 3D object. Compared to image diffusion models employed in Stable Zero123, the usage of video diffusion models offers significant advantages in terms of the generalization and view consistency of generated outputs.
Furthermore, developers can enhance 3D optimization by utilizing Stable Video 3D’s potent ability to produce arbitrary orbits around an object. Stable Video 3D can consistently produce high-quality 3D meshes from single image inputs by combining these methods with novel masked score distillation sampling loss function and disentangled lighting optimization.
1) Multi-View Generation
Significant improvements in 3D generation, especially in novel view synthesis (NVS), are introduced by Stable Video 3D. It can provide coherent images from any viewpoint with good generalization, in contrast to earlier methods that frequently struggle with constrained perspectives and inconsistent results.
This feature significantly improves important aspects of realistic and accurate 3D generations by guaranteeing consistent item appearance across numerous viewpoints in addition to boosting pose-controllability.
Video Editors and Developers can now have advanced three-dimensional spatial and temporal views of their video objects generated at ease. They can access those viewpoints that were very difficult to access or not accessible at all with simple video rendering and camera tools.
2) 3D Generation
Utilizing its multi-view consistency, Stable Video 3D optimizes mesh representations and 3D Neural Radiance Fields (NeRF) to raise the calibre of 3D meshes produced straight from new views. To further improve 3D quality in areas not visible in the expected views, it includes a masked score distillation sampling loss.

Moreover, Stable Video 3D uses a disentangled illumination model that is concurrently optimized with 3D shape and texture to lessen the problem of baked-in lighting. So now users can expect not only 3D generated objects but “optimal” objects that have been adjusted and fine-tuned accordingly to the user’s video environment variables.
Conclusion
Stable Video 3D is a major improvement with the multi-dimensional view feature for 3D videos. Let’s see how developers worldwide benefit from the tool and come up with impressive 3D-generated videos.




