

Sorting data is an essential task in data analysis, and Pandas provides a powerful method called sort_values() to sort DataFrames based on one or more columns. In this article, we will learn how to use sort_value method to Sort by Column a Pandas DataFrame and with the different parameters that can be used to customize the sorting behavior.
What is the sort_values() Function in Pandas?
The sort_values() function in Pandas allows us to sort DataFrames on the basis of one or more columns. It takes several parameters that can define the sorting behavior, such as: the columns to sort by, the sorting order (ascending or descending), and handling null values.
Let us now explore the various ways to use the sort_values function to sort a DataFrame based on single and multiple columns.
Sorting in Ascending Order
Sorting data in a DataFrame in ascending order is the default behavior of the sort_values() function. This means that when no sorting order is defined, the sort_values will sort the DataFrame in Ascending Order.
Sorting by a Single Column
To sort a DataFrame by a single column, we can simply pass the column name to the by parameter of the sort_values() function.
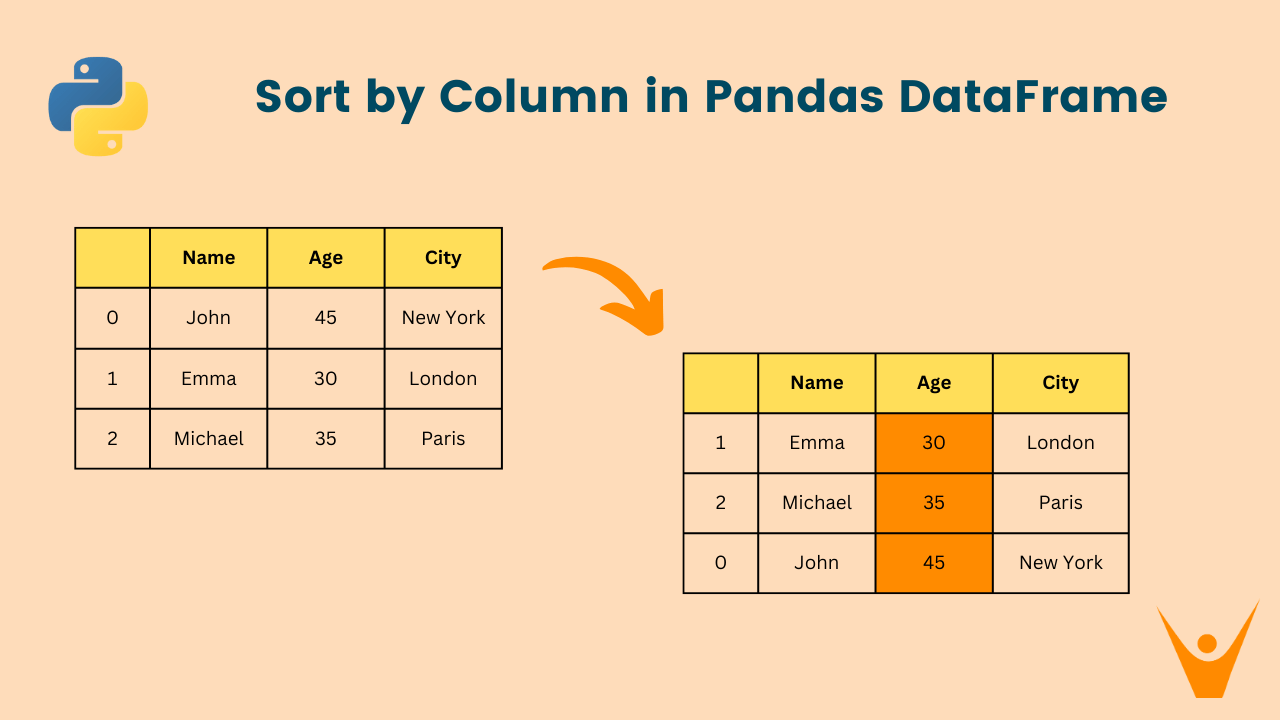
For example, let’s sort a DataFrame called df by the ‘Age’’ column with implementation in Python:
import pandas as pd
data = {
"Name": ["John", "Emma", "Michael"],
"Age": [45, 30, 35],
"City": ["New York", "London", "Paris"]
}
df = pd.DataFrame(data)
# Display the original DataFrame
print('Original DataFrame:\n', df)
# Sort the DataFrame by the 'Age' column
df = df.sort_values(by='Age')
# Display the sorted DataFrame
print('Sorted DataFrame:\n', df)Output:
Original DataFrame:
Name Age City
0 John 45 New York
1 Emma 30 London
2 Michael 35 Paris
Sorted DataFrame:
Name Age City
1 Emma 30 London
2 Michael 35 Paris
0 John 45 New York
Sorting by Multiple Columns
Sorting by multiple columns allows us to define a hierarchical sorting order. We can pass a list of column names to the by parameter to sort the DataFrame based on multiple columns. The sorting is performed sequentially, with the first column taking precedence over the second, and so on. This simply means, in the case of clashes in the first column, the second column will be used as a second preference.
Let us consider an example, let’s sort the DataFrame df by the ‘Age’ and ‘Name’ columns:
import pandas as pd
data = {
"Name": ["John", "Zmma", "Michael"],
"Age": [45, 30, 35],
"City": ["New York", "London", "Paris"]
}
df = pd.DataFrame(data)
# Display the original DataFrame
print('Original DataFrame:\n', df)
# Sort the DataFrame by multiple columns ('Age' and 'Name')
df = df.sort_values(by=['Age', 'Name'])
# Display the sorted DataFrame
print('Sorted DataFrame:\n', df)Output:
Original DataFrame:
Name Age City
0 John 45 New York
1 Zmma 30 London
2 Michael 35 Paris
Sorted DataFrame:
Name Age City
1 Zmma 30 London
2 Michael 35 Paris
0 John 45 New York
Sorting with Null Values
By default, the sort_values() function places null values at the end of the sorted DataFrame. However, we can change this behavior by setting the na_position parameter to ‘first’ to place null values at the beginning.
For example, let us try to sort the DataFrame df by the ‘Age’’ column with null values first:
import pandas as pd
data = {
"Name": ["John", "Emma", "Michael"],
"Age": [45, 30, None],
"City": ["New York", "London", "Paris"]
}
df = pd.DataFrame(data)
# Display the original DataFrame
print('Original DataFrame:\n', df)
# Sort the DataFrame by column ('Age') with null values placed first
df = df.sort_values(by='Age', na_position='first')
# Display the sorted DataFrame
print('Sorted DataFrame:\n', df)Output:
Original DataFrame:
Name Age City
0 John 45.0 New York
1 Emma 30.0 London
2 Michael NaN Paris
Sorted DataFrame:
Name Age City
2 Michael NaN Paris
1 Emma 30.0 London
0 John 45.0 New York
Sorting in Descending Order
We can also sort the DataFrame in similar ways in Descending Order. To do this we simply need to set the ascending parameter to False. This will reverse the sorting order of the specified column(s).
Let us try a simple example:
import pandas as pd
data = {
"Name": ["John", "Emma", "Michael"],
"Age": [45, 30, 55],
"City": ["New York", "London", "Paris"]
}
df = pd.DataFrame(data)
# Display the original DataFrame
print('Original DataFrame:\n', df)
# Sort the DataFrame by column ('Age') in descending order
df = df.sort_values(by='Age', ascending=False)
# Display the sorted DataFrame
print('Sorted DataFrame:\n', df)Output:
Original DataFrame:
Name Age City
0 John 45 New York
1 Emma 30 London
2 Michael 55 Paris
Sorted DataFrame:
Name Age City
2 Michael 55 Paris
0 John 45 New York
1 Emma 30 London
Sorting with Custom Sorting Algorithm
We can also use custom sorting algorithms to sort a DataFrame. The sort_values() function in Pandas provides different sorting algorithms to choose from. By default, the sorting algorithm used for the sort_values function is ‘quicksort’. We can change this to any algorithm according to our needs.
For example, let us try to sort a DataFrame using the ‘merge sort’:
import pandas as pd
data = {
"Name": ["John", "Emma", "Michael"],
"Age": [45, 30, 55],
"City": ["New York", "London", "Paris"]
}
df = pd.DataFrame(data)
# Display the original DataFrame
print('Original DataFrame:\n', df)
# Sort the DataFrame by column ('Age') using mergesort
df = df.sort_values(by='Age', kind='mergesort')
# Display the sorted DataFrame
print('Sorted DataFrame:\n', df)Output:
Original DataFrame:
Name Age City
0 John 45 New York
1 Emma 30 London
2 Michael 55 Paris
Sorted DataFrame:
Name Age City
1 Emma 30 London
0 John 45 New York
2 Michael 55 ParisYou should also now learn how to rename columns in Pandas.
Conclusion
In this article, we have explored the different ways and parameters used to sort the DataFrames on the basis of single or multiple columns. By mastering the techniques discussed in this article, we can manipulate and analyze data more effectively using Pandas.