



On April 3rd, 2024, Opera browser announced that it will be providing experimental support for 150 local Large Language Models (LLMs). These LLMs include variants from approximately 50 families of models in the developer stream.
Highlights:
- Opera announces that it will provide local access to 150 Large Language Models through it’s browser.
- Includes model variants over approximately 50 families including Mixtral, Llama and Gemma.
- Can only be accessed through the latest version of Opera Developer.
A few months ago, NVIDIA’s Chat With RTX released the first local chatbot that can be locally installed on systems with high-end GPUs and processors. But this is the first time that a browser will allow local access to LLM variants.
How good is this Opera’s built in feature and what else comes along with it? Which LLMs is Opera giving local access to? We are going to explore all of these topics in-depth through this article. So, let’s find out right away!
Opera’s new addition to the AI Feature Drops Program
As part of its new AI Feature Drops Programme, which enables early adopters to test early, frequently experimental versions of the browser’s AI feature set, Opera is testing this new collection of local LLMs in the Opera One development stream.
With the use of Opera’s built-in feature, local LLMs may now be readily accessed and maintained from a major browser for the first time. Opera’s online Aria AI service now comes with free local AI models.
“Introducing Local LLMs in this way allows Opera to start exploring ways of building experiences and knowhow within the fast-emerging local AI space,”
Krystian Kolondra, EVP Broswers and Gaming at Opera
Opera is now locally supporting over 150 LLM variants. Some of the supported LLMs are:
- Llama from Meta
- Vicuna
- Gemma from Google
- Mixtral from Mistral AI
- And many families more
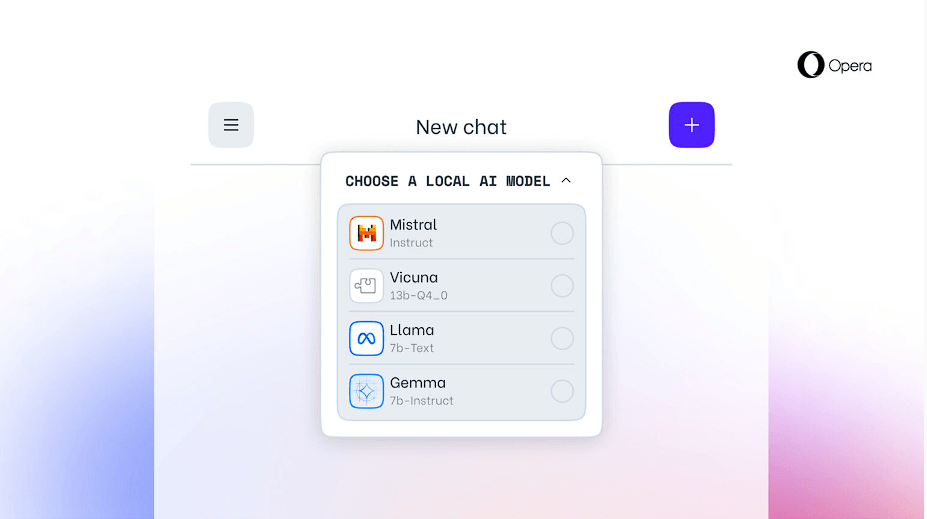
Opera is looking to change the scene of local LLMs forever by bringing this feature. Users can use generative AI without sending data to a server by using local large language models, which keep users’ data locally on their device. Opera One Developer users now have the option to choose which model they wish to use to process their input.
How can you access these models?
Opera’s browser is rolling out the local LLM access feature publicly to developers worldwide. Early adopters can test it early and enjoy the groundbreaking experience. Users must update to the most recent version of Opera Developer and take a few steps to enable the new capability before they can test the models.
Perform the following steps to test the models locally:
- As before, open the Aria Chat side panel.
- “Choose local mode” will be the drop-down menu at the top of the chat window.
- Click “Go to settings”
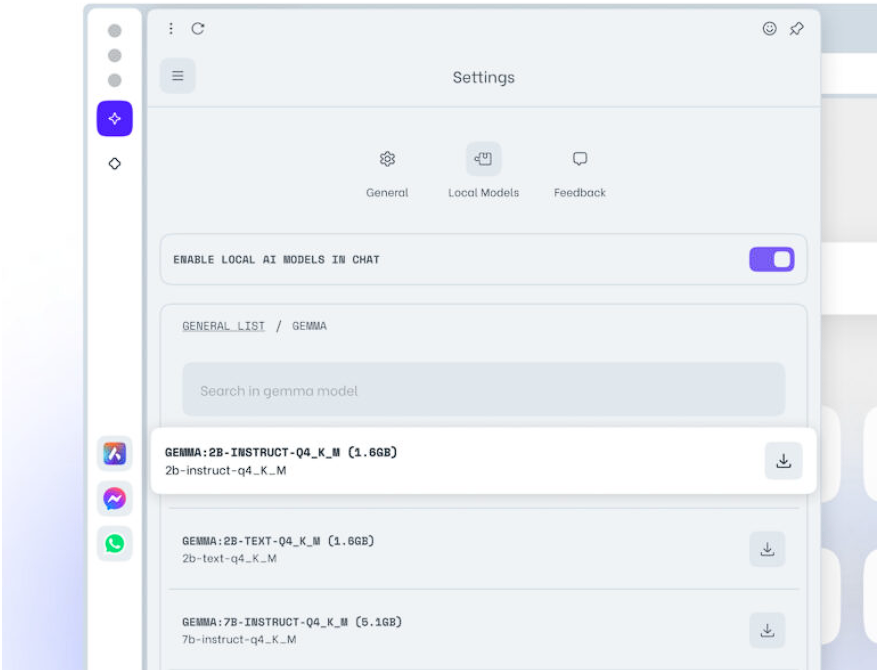
- You can search and explore the model or models that you wish to download right here. Click the download button on the right to get one of the faster and smaller variants, GEMMA:2B-INSTRUCT-Q4_K_M.
- Once the download is finished, click the menu button in the upper left corner to launch a new chat window.
- “Choose local mode” will be the drop-down menu at the top of the chat window.
- Choose the model that you recently downloaded.
- Enter a question in the chat window, and the local model will respond.
Congratulations! You have successfully made local access to an LLM with the help of Opera’s browser. Selecting a local LLM will cause it to be downloaded to your computer. However, you must remember that each of them takes 2–10 GB of local storage space.
Because it depends on the computing power of your hardware, a local LLM is likely to produce output much more slowly than a server-based one. Until you initiate a new discussion with Aria or turn it back on, Opera’s built-in browser AI, the local LLM, will be used.
Which LLM models should you try out locally?
Out of the several LLM variants that Opera is offering, some are really noteworthy and must be definitely tried to enjoy the local access features first hand.
Code Llama is an intriguing local language machine (LLM) that can be investigated further. It is an extension of Llama designed to generate and discuss code, with an emphasis on developer efficiency. There are three versions of Code Llama: 7, 13, and 34 billion parameters. Many popular programming languages are supported by Llama, including Python, C++, Java, PHP, Typescript (JavaScript), C#, and Bash.
There are several variants of Code Llama:
- Code – it is the foundational paradigm for completing codes
- Instruct – it is optimised to provide secure and beneficial responses in natural language
- Python – it is a customised Code Llama version that has been further refined on 100B Python code tokens
Phi-2 is another model that you should try out. The 2.7B parameter Phi-2 language model, published by Microsoft Research, exhibits exceptional reasoning and language understanding abilities. Prompts with question-answering, chat, and coding styles work well with the Phi-2 paradigm.
Lastly, you should definitely try out Mixtral. Text generation, question answering, and language understanding are just a few of the many natural language processing applications that Mixtral is built to be excellent at. Three main advantages are accessibility, performance, and versatility.
These are just few of the special models that you can try out. Opera is offering much more that is suited to you and your preferences as a developer.
The Future of Local LLMs
The introduction of local LLMs in Opera marks a significant step forward for this technology. The general public, not just those with access to pricey cloud services, may have more access to local LLMs. This has the potential to democratize AI and enable anyone to use its power for a range of purposes.
Data would no longer need to be sent to the cloud because local LLMs would process information locally on the device. This tackles privacy issues related to cloud-based LLMs. A more individualized AI experience could result from local LLMs that are adjusted to certain user requirements and preferences. Imagine LLMs offering automation and real-time support incorporated in our daily gadgets, like as wearables and cellphones.
But there are still obstacles to be addressed. It’s possible that modern devices lack the processing capability to perform complicated LLMs locally. Hardware advancements are required. Adequate training of local LLMs necessitates large computational resources. To solve this, new methods like federated learning are being investigated.
All things considered, the future of local LLMs appears bright, with Opera’s initiative serving as a spur. We may anticipate local LLMs to grow in strength, accessibility, and integration into our daily lives as technology develops.
Conclusion
Opera is making history as the first browser to provide local access to multiple LLMs. Till now it has been a difficult task in setting up LLMs locally due to their heavy model weights and system requirements, but Opera is completely transforming the scene of Generative AI with the help of this feature. Let’s find out in the days to come, how developers worldwide are benefitting from this.




