



OpenAI, in their spring update just announced a new model called GPT-4o (“o” for “omni”). This model is available to all categories of users both free and paying users. This is a huge step by OpenAI towards freely accessible and available AI.
our new model: GPT-4o, is our best model ever. it is smart, it is fast,it is natively multimodal (!), and…
— Sam Altman (@sama) May 13, 2024
GPT 4o provides GPT-level intelligence but it is much faster with audio, image, and textual inputs
This model focuses on Understanding the tone of voice and providing a real-time audio and vision experience. It is 2x faster, 50% cheaper, and has 5x higher rate limits compared to GPT-4 turbo.
This experience is demonstrated by their new voice assistant. The demo was streamed live for users to watch and see all new developments.
How To Access OpenAI GPT-4o?
GPT-4o has been made available to all ChatGPT users, including those on the free plan. Previously, access to GPT-4 class models was restricted to individuals with a paid monthly subscription.
it is available to all ChatGPT users, including on the free plan! so far, GPT-4 class models have only been available to people who pay a monthly subscription. this is important to our mission; we want to put great AI tools in the hands of everyone.
— Sam Altman (@sama) May 13, 2024
How exactly is GPT-4o better than previous GPT iterations?
Prior to GPT-4o, Voice Mode could be used to talk to ChatGPT with latencies of 2.8 seconds (GPT-3.5) and 5.4 seconds (GPT-4) on average. The pipeline of three separate models- transcription of audio to text, the central GPT model that takes text input and gives text output, and lastly the model that converts the text back to audio.
This process means that the main source of intelligence, GPT-4, loses a lot of information—it can’t directly observe tone, multiple speakers, or background noises, and it can’t output laughter, singing, or expressing emotion.
GPT-4o is a single end-to-end model, trained across text, vision, and audio data. I.e. All inputs are processed by a single neural network. This is the first all-encompassing model they have developed so GPT-4o has barely scratched the surface with its capabilities.
Evaluation and Capabilities
The model was evaluated on traditional industry benchmarks. GPT-4o achieves GPT-4 Turbo-level performance on text, reasoning, and coding intelligence while setting new high watermarks on multilingual, audio, and vision capabilities.
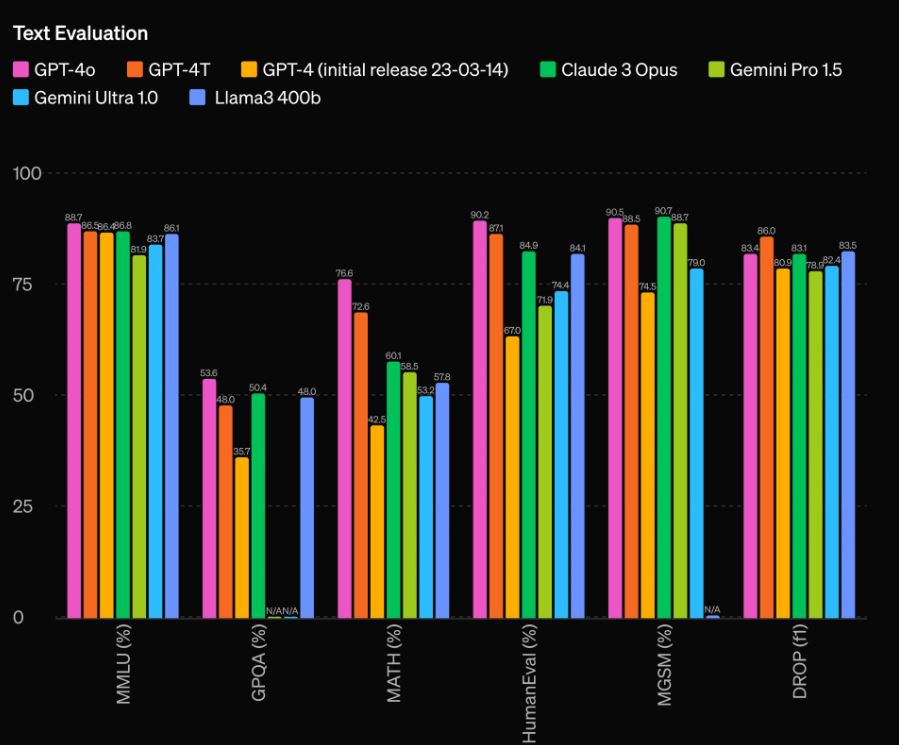
This model also implements a new tokenizer that provides better compression across language families.
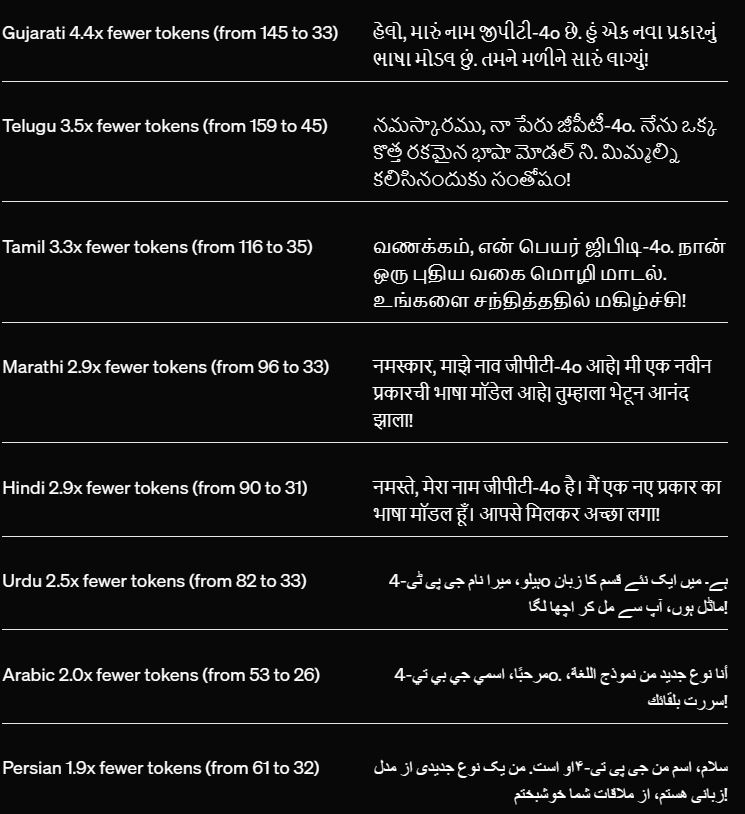
OpenAI in their release blog gave a detailed explanation of the model capabilities with many different samples.
The researchers also discussed the limitations of the model along with the safety of the model.
We recognize that GPT-4o’s audio modalities present a variety of novel risks. Today we are publicly releasing text and image inputs and text outputs. Over the upcoming weeks and months, we’ll be working on the technical infrastructure, usability via post-training, and safety necessary to release the other modalities. For example, at launch, audio outputs will be limited to a selection of preset voices and will abide by our existing safety policies. We will share further details addressing the full range of GPT-4o’s modalities in the forthcoming system card.
OpenAI
AI companies are constantly looking for increased computational power. For previous voice interactive models, three models- transcription, intelligence, and text-to-speech all came together to deliver voice mode. However, this brings high latency and breaks the immersive experience. But with GPT 4o, this all happens seamlessly and natively with voice modulations and minimal latency. This is truly an incredible tool for all users!




