



Researchers at Stanford University introduced Octopus v2, a groundbreaking on-device language model to address latency, accuracy, and privacy-related concerns associated with current language models.
What’s special about Octopus v2?
In the domain of Large Language Models (LLMs), achieving a balance between model effectiveness and real-world constraints like privacy, cost, and device compatibility is a significant challenge. Cloud-based models offer high accuracy but face issues such as privacy vulnerabilities and high costs.
Also, deploying models on edge devices introduces challenges in maintaining low latency and high accuracy due to hardware limitations
Stanford University’s Octopus v2 is a groundbreaking on-device language model with 2B parameters that address latency, accuracy, and privacy concerns associated with current LLMs.
Introducing Octopus V2 – On-Device 2B LLMs for actions, outperform GPT-4.
— Nexa AI (@nexa4ai) April 4, 2024
⚡️35x Faster and more accurate than RAG & Llama-7B <1s latency.
🚀The new era of on device AI agents is coming. Stay tuned for our super app! pic.twitter.com/aOORppEZ3S
Its approach is based on fine-tuning functional tokens that enable precise function calling, surpassing GPT-4 in efficiency while reducing context length massively by 95%.
So, how does it work?
1) Causal language model as a classification model
Accurately selecting an appropriate function from all available options and then generating the correct function parameters are essential steps for successfully invoking a function. This process comprises two stages a) a function selection stage and b) a parameter generation stage.
The traditional method involves retrieving relevant functions and providing context about multiple options to determine the optimal function names, which can be prone to inaccuracies due to the generation of multiple tokens.
To improve accuracy and reduce token complexity, they propose assigning unique functional tokens, like, to represent functions from a pool of N options.
This simplifies the prediction task to a single-token classification among the N functional tokens, achieved by introducing new special tokens into the tokenizer and modifying the pre-trained model architecture.
For function name prediction, the model selects the correct function among the N functional tokens using argmax probability selection. Additionally, to ensure the model understands each token’s meaning, function descriptions are incorporated into the training dataset. This allows the model to grasp the significance of these specialized tokens.
A prompt template supporting three response styles is designed to facilitate parallel and nested function calls. It is as follows:

This methodology offers a crucial advantage. Once the model is fine-tuned to recognize the importance of functional tokens, it can conduct inference using the special token as the early stopping criterion.
This eliminates the need to analyze tokens from function descriptions, reducing the retrieval and processing of relevant functions’ descriptions. As a result, this significantly reduces the number of tokens required for accurate function name identification.
The distinction between the conventional retrieval-based method and the proposed Octopus v2 model is shown in the image below:
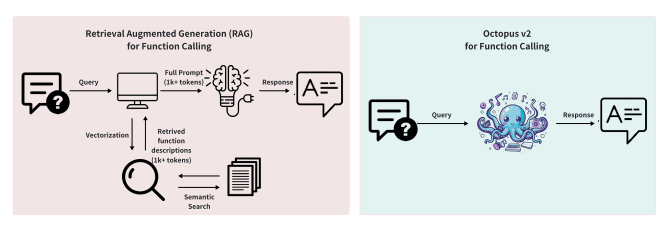
2) Data Collection
API Collection: In the API collection process, the team began by selecting Android APIs based on factors like usability, frequency of usage, and technical implementation complexity.
They curated 20 Android APIs across three categories: Android system APIs, Android app APIs, and Android smart device management APIs. These APIs cover a wide range of functions, from basic mobile operations to managing smart home devices within the Google Home ecosystem. An example of an Android API is as follows:
def get_trending_news(category=None, region='US', language='en', max_results=5):
Fetches trending news articles based on category, region, and language.
These are the parameters:
- category (str, optional): News category to filter by, by default, use None for all categories.
- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses ‘US’
- language (str, optional): ISO 639-1 language code for article language, by default, uses ‘en’.
- max_results (int, optional): Maximum number of articles to return, by default, uses 5.
It returns list[str]: a list of strings, each representing an article. Each string contains the article’s heading and URL.
2) Dataset Generation: The dataset generation involves three phases: a) generating relevant queries and function call arguments, b) developing irrelevant queries with suitable function bodies, and c) implementing binary verification support through Google Gemini.
They focused on creating positive queries resolved by a single API and incorporated both positive and negative examples to enhance the model’s analytical skills.
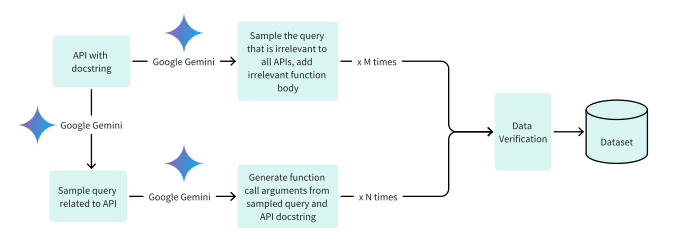
Dataset Verification: Despite the advanced capabilities ofLLMs like OpenAI’s GPT-4 and Google’s Gemini, errors in function call argument generation persist.
To address this, they introduced a verification mechanism where Google Gemini evaluates the completeness and accuracy of the generated function calls and initiates a regeneration process if any errors are detected in function calls.
3) Model Development and Training
In the framework, they utilized the Google Gemma-2B model as the pre-trained model and employed two distinct training methodologies: a) full model training and b) LoRA model training. For full model training, they used an AdamW optimizer with a learning rate of 5e-5, a warm-up step of 10, and a linear learning rate scheduler.
The same optimizer and learning rate configuration are then applied to LoRA training, with a specified LoRA rank of 16 and application to specific modules including q_proj, k_proj, v_proj, o_proj, up_proj, and down_proj. The LoRA alpha parameter is set to 32. Both training methods, full model and LoRA, are conducted for specified 3 epochs.
Here are the Results
To demonstrate the practical application of Octopus v2, they focus on Android system function calls, emphasizing accuracy and latency in function call generation. Initially, they curated a dataset foundation consisting of 20 Android APIs. They employed two distinct methods for generating function call commands.
Using Google Gemini, they sampled relevant queries for the selected Android function calls and manually labelled the ground truth to create the evaluation dataset. The benchmark results mainly focus on two critical metrics: accuracy and latency.
Llama-7B RAG Evaluation
In the initial evaluation of the Llama-7B model, they observed limited proficiency in producing the desired outcomes. Because of this, they turned to a fine-tuned variant of Llama-7B, referred to as Trelis, specifically tailored for function call generation.
During the assessment, they applied the RAG method with relaxed output format criteria, accepting responses even with missing parentheses as correct. This evaluation was executed on a single NVIDIA A100 machine, with all Llama-7B results compared against the ground truth.
The primary issues encountered included incorrect function name selection and erroneous parameter generation.
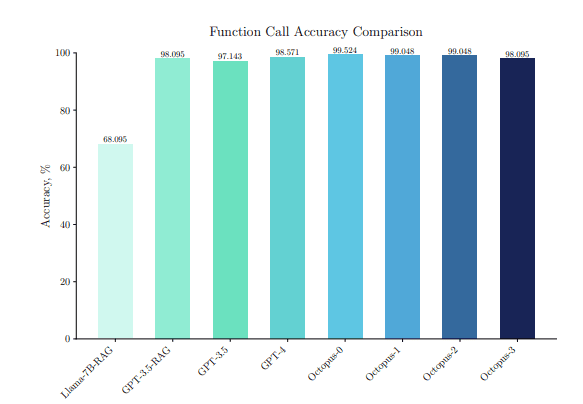
Despite leveraging few-shot learning to steer the model toward accurate function generation, its performance remained modest, achieving an accuracy rate of 68.095% when overlooking format requirements and exhibiting a latency of 13.46 seconds, excluding model loading time.
GPT-3.5 RAG Evaluation
Similar to the Llama-7B approach, they utilized GPT-3.5 for response generation, incorporating a semantic search strategy for context acquisition and designing a specific prompt style to enhance accuracy through one-shot learning.

In this evaluation, leveraging the gpt-3.5-turbo0125 checkpoint, known for its proficiency in function calling tasks, they achieved an impressive 98.095% accuracy. The latency for generating a single function call was notably reduced to 1.97 seconds, a significant improvement over the Llama-7B model’s performance.
Further analysis revealed that latency optimization involved precomputing function descriptions’ embeddings and employing parallel computation on multicore CPUs for faster retrieval.
GPT-3.5 and GPT-4
In THE evaluations of GPT-3.5 and GPT-4 models, they streamlined the process by including all 20 function descriptions directly in the context, avoiding microservices interactions and their associated IO-bound overheads. This adjustment led to a latency reduction to 1.18 seconds for GPT-3.5.
However, accuracy slightly declined to 97.143%, possibly due to the diminished effectiveness of the language model with longer text inputs.
Conversely, GPT-4 demonstrated superior accuracy at 98.571% and even lower latency than GPT-3.5, despite expectations of being a larger model.
This performance difference might be attributed to variations in API traffic or hardware configurations between the two models, suggesting potential differences in resource allocation or demand.
Octopus v2
The Octopus model was evaluated using 1000 data points for each API, resulting in an impressive 99.524% accuracy on the evaluation dataset. The prompt fed to Octopus v2 was as simple as this:
“Below is the query from the users, please call the correct function and generate the parameters to call the function. Query: {user_query} Response:”
In the methodology, they found that directly integrating function details into the context was unnecessary, as the Octopus model inherently maps functional tokens to corresponding function descriptions.
This optimization significantly reduces the number of tokens required for processing. With its compact size and minimal context needs, the Octopus model achieves a reduced latency of 0.38 seconds.
To ensure a fair comparison, they maintained consistent benchmark settings with the Llama-7B evaluation. Additionally, they explored deploying the Octopus v2 2B model on mobile devices through quantization.
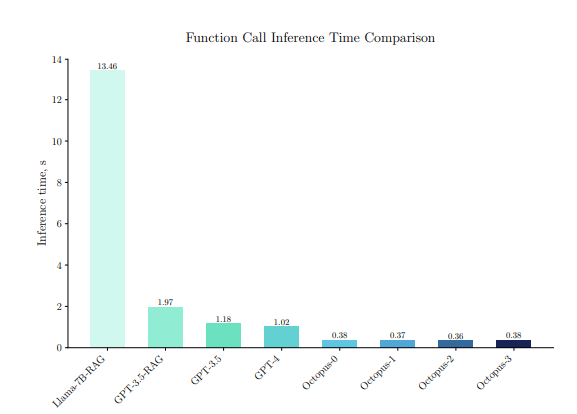
By precomputing the state for the fixed prompt mentioned above the on-device model delivers impressive performance, completing function calls within 1.1 to 1.7 seconds for typical queries containing 20 to 30 tokens using a standard Android phone.
Standford researchers recently also collaborated with Google Deepmind for SAFE, a fact-checking LLM.
Conclusion
Stanford’s Octopus v2 model marks a monumental advancement in on-device language models, ushering in a new era of heightened performance and efficiency. With its remarkable ability to maximize accuracy while minimizing latency and context length, Octopus v2 is poised to redefine the landscape of AI applications by enhancing operational efficiency.




