



During the GTC24 conference, NVIDIA made many announcements, but one of the most interesting to look into is NIM, so let’s know more about it!
Highlights:
- NVIDIA unveiled NIM to simplify the deployment of AI models in production environments.
- They are collaborating with tech giants like Amazon, Google, and Microsoft.
- NIM microservices may get integrated into platforms like SageMaker, Kubernetes Engine, and Azure AI.
NVIDIA’s NIM Explained
NIM by NVIDIA is a novel software platform engineered to simplify the deployment of custom and pre-trained AI models into production environments.
In simple terms, a NIM is a container full of microservices. Microservices, or microservice architecture, is an architectural style that structures an application as a collection of services that are loosely coupled and independently deployed.
NVIDIA aims to accelerate and optimize the deployment of generative AI-based LLMs with a new approach to delivering models for rapid inference.
These services are organized around business capabilities with each service owned by a single and small team. The microservice architecture helps an organization deliver large, complex applications rapidly and reliably.
The container includes any type of model that can run anywhere where there is an NVIDIA GPU. This could be on the cloud or your local machine. The models can include various kinds of models spanning open to proprietary ones.
“We believe that NVIDIA NIM is the best software package, the best runtime for developers to build on top of, so that they can focus on the enterprise applications”.
Manuvir Das, VP of enterprise computing at NVIDIA
This container can be deployed wherever a basic contained can be run. This can be a Kubernetes deployment in the cloud architecture, a Linux-based server, or any serverless function-as-a-service model.
NIM doesn’t replace any prior approach to model delivery from NVIDIA. Rather, it’s a container that includes a highly optimized model for NVIDIA GPUs along with necessary technologies to help improve inference.
Some other interesting previous launches by NVIDIA in 2024 are Chat with RTX and StarCoder2 AI collaboration.
Here’s What NIM does?
Patrick Moorhead- Founder, CEO, and Chief Analyst at Moor Insights & Strategy said the following about NIM on X:
Bigger than Blackwell is @nvidia’s "NIM" for enterprises. Nvidia Inference Microservices.
— Patrick Moorhead (@PatrickMoorhead) March 18, 2024
Enterprise SaaS & SW Platforms (ie Adobe, SAP) & Data Platforms (ie Cloudera, Cohesity, & SnowBricks) write once across the hybrid multi-cloud Infrastructure (ie AWS, Dell) and Model… pic.twitter.com/rPoAsDKvW8
The NIM platform leverages the company’s expertise in inferencing and model optimization, simplifying the process of deploying AI models into production environments.
Combining a model with an optimized inferencing engine and packaging it into a container, offers developers a streamlined solution that would typically take weeks or months to achieve.
This initiative aims to create an ecosystem of AI-ready containers, utilizing NVIDIA’s hardware as the foundational layer.
NIM packages optimized inference engines, industry-standard APIs, and AI model support into containers for easy deployment. While offering prebuilt models, it also accommodates organizations to integrate their proprietary data and facilitates the acceleration of Retrieval Augmented Generation (RAG) deployment.
This technology represents a significant milestone for AI deployment, serving as the cornerstone of NVIDIA’s next-generation strategy for inference. Its impact is expected to extend across model developers and data platforms in the AI space.
NIM currently supports models from various providers, including NVIDIA, A121, Adept, Cohere, Getty Images, Shutterstock, and open models from Google, Hugging Face, Meta, Microsoft, Mistral AI, and Stability AI.
How NIMs will help the RAG approach?
NVIDIA’s NIMs are poised to facilitate the deployment of Retrieval Augmented Generation (RAG) models, a key focus area for many organizations. With a growing number of customers already implementing RAGs, the challenge lies in transitioning from prototyping to production.
NVIDIA and several leading data vendors are hoping that this is the answer to this challenge. Vector database capabilities are critical to enabling RAG, and there are several vector database vendors supporting NIMs such as Apache Lucene, Datastax, Faiss, Kinetica, Milvus, Redis and Weaviate.
NIMs offer a solution to this by streamlining the deployment process, enabling organizations to deliver real business value with their models.
Additionally, the integration of NVIDIA NeMo Retriever microservices enhances the RAG approach by providing optimized data retrieval capabilities. NeMo retriever was announced by NVIDIA in November 2023 to help enable RAG with an optimized approach for data retrieval.
How to use NVIDIA’s NIM?
Using NVIDIA NIM is a simple process. Within the NVIDIA API documentation, developers have access to various AI models that can be used for building and deploying their AI applications.
To deploy a microservice on your infrastructure, sign up for the NVIDIA AI Enterprise 90-day evaluation license and follow the steps given below:
First, Download the model that you want to deploy from NVIDIA NGC (Nvidia GPU Cloud). For the given example, a version of the Llama-2 7B Model has been downloaded:
ngc registry model download-version "ohlfw0olaadg/ea-participants/llama-2-7b:LLAMA-2-7B-4K-FP16-1-A100.24.01Then, Unpack the downloaded model into a target repository:
tar -xzf llama-2-7b_vLLAMA-2-7B-4K-FP16-1-A100.24.01/LLAMA-2-7B-4K-FP16-1-A100.24.01.tar.gzNow, Launch the NIM Container with the desired model:
docker run --gpus all --shm-size 1G -v $(pwd)/model-store:/model-store --net=host
nvcr.io/ohlfw0olaadg/ea-participants/nemollm-inference-ms:24.01
nemollm_inference_ms --model llama-2-7b --num_gpus=1Once the Container is deployed, start making requests using REST API:
import requests
endpoint = 'http://localhost:9999/v1/completions'
headers = {
'accept': 'application/json',
'Content-Type': 'application/json'
}
data = {
'model': 'llama-2-7b',
'prompt': "The capital of France is called",
'max_tokens': 100,
'temperature': 0.7,
'n': 1,
'stream': False,
'stop': 'string',
'frequency_penalty': 0.0
}
response = requests.post(endpoint, headers=headers, json=data)
print(response.json())NVIDIA NIM’s partners
LlamaIndex, an innovative data framework designed to support LLM-based application development, was announced as a launch partner for NIM.
⭐️Just announced at GTC keynote⭐️ NVIDIA Inference Microservice or NIM and we are a launch partner!
— LlamaIndex 🦙 (@llama_index) March 18, 2024
NIM accelerates deployment of LLM models across NVIDIA GPUs and integrates with LlamaIndex to build first-class RAG pipelines.
NVIDIA's blog post: https://t.co/8bOpEOSL0N
Our…
NIM accelerates deployment of LLM models across NVIDIA GPUs and it can now be integrated with LlamaIndex to build first-class RAG pipelines.
LangChain also announced its integration:
🤝 Our Integration With NVIDIA NIM for GPU-optimized LLM Inference in RAG
— LangChain (@LangChainAI) March 18, 2024
As enterprises turn their attention from prototyping LLM applications to productionizing them, they often want to turn from third-party model services to self-hosted solutions. We’ve seen many folks… pic.twitter.com/A0vFP1Bv8T
Haystack, the open-source LLM framework by Deepset, has also partnered with NMI which will now give users the flexibility to deploy hosted or self-hosted RAG pipelines.
The new NVIDIA NIM integration in Haystack 2.0 gives you the flexibility to deploy hosted or self-hosted RAG pipelines.https://t.co/h4ewr1qcMx
— Haystack (@Haystack_AI) March 18, 2024
NVIDIA is collaborating with Amazon, Google, and Microsoft to integrate these NIM microservices into platforms like SageMaker, Kubernetes Engine, and Azure AI, as well as the above-mentioned frameworks such as Deepset, LangChain, and LlamaIndex.
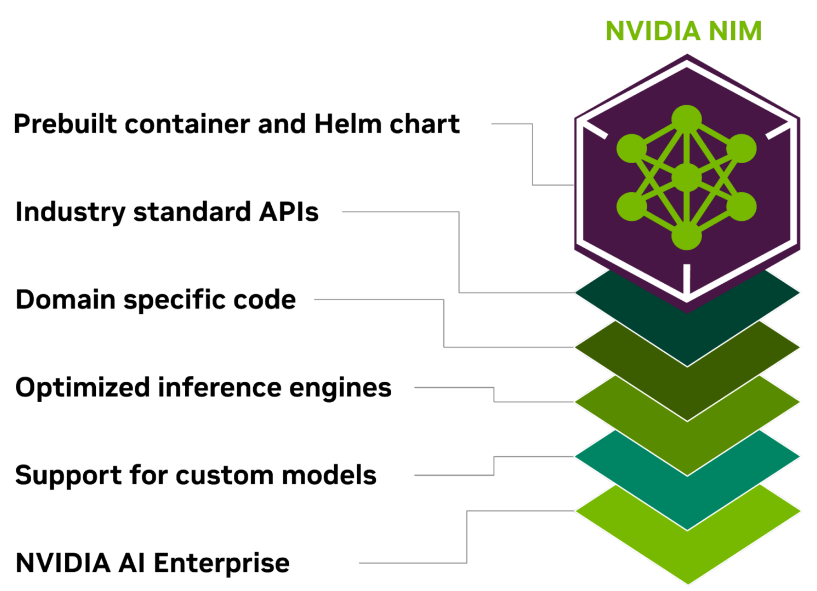
Here are the benefits it will provide:
- Deploy generative AI applications anywhere
- Prebuilt container and Helm Chart- a package that contains all the necessary resources to deploy an application to a Kubernetes cluster
- Develop with defacto standard and industry-defined APIs
- Harness domain-specific models
- Run on optimized inference engines
- Accelerated models that are ready for deployment
Conclusion
This recent development in the deployment of RAG models will greatly increase the efficiency of production environments. NIM will offer a streamlined solution to both experienced developers and those still new to the world of Generative AI!




