



NVIDIA isn’t new to generative AI chatbots, a few months ago it released ChatRTX. Now NVIDIA is looking to make a new impact in synthetic data generation and redefine datasets for generative AI training with this ‘Nemotron-4 340B’ Model.
Highlights:
- NVIDIA announces Nemotron-4 340B, an open-source family of LLMs that can generate synthetic data.
- It is built on the conventional decoder-only transformer model.
- Rivals GPT-4 and can be fine-tuned using the NeMo framework or LoRA.
NVIDIA’s Nemotron-4 340B
Nemotron-4-340B-Instruct is a Large Language Model that can be utilized in a synthetic data production pipeline to produce training data that will aid researchers and developers in developing LLMs of their own. It’s an improved Nemotron-4-340B-Base model for English-based single- and multi-turn conversation scenarios. 4,096 tokens of context length are supported.
These models are a family of open models. As a result, Nemotron-4 340B provides developers with a scalable, free method of creating synthetic data that may be used to construct robust LLMs, via a uniquely liberal open model license.
The model has been formally recognized and introduced, creating a lot of excitement in the AI world. It had been functioning on LMSys.org Chatbot Arena under the mysterious identity of “june-chatbot.”
Robust training datasets might be prohibitively expensive and difficult to obtain, yet they are essential to the performance, accuracy, and integrity of responses from a custom LLM.
Thus, this latest advancement from NVIDIA represents a major turning point for the AI industry since it enables companies in a wide range of industries to build strong, domain-specific LLMs without requiring large and expensive real-world datasets.
How can you Access it?
NVIDIA’s Nemotron-4-340B-Instruct’s model weights are open-source and available on the Hugging Face platform. You can download them from there and follow the usage instructions to deploy the model.
Also since the model is based on the NVIDIA Open Model License, you have to keep the following in mind:
- Models are commercially usable.
- You are free to create and distribute Derivative Models.
- NVIDIA does not claim ownership of any outputs generated using the Models or Derivative Models.
NeMo and TensorRT-LLM are also available to businesses via the cloud-native NVIDIA AI Enterprise software platform, which offers rapid and effective runtimes for generative AI foundation models. This platform is ideal for those looking for enterprise-grade support and security for production environments.
Looking Into The Model Build
It is quite interesting to look into the NVIDIA Nemotron-4 340B’s Model Build. It’s quite innovative and well-architected to make it efficient for a wide range of purposes.
The base, instruct, and reward models in the Nemotron-4 340B family work together to create synthetic data that is used to train and improve LLMs. The models are designed to function with NVIDIA NeMo, an open-source platform that enables data curation, customization, and evaluation during the whole model training process.
Additionally, they are designed using the open-source NVIDIA TensorRT-LLM library with support for inference.
Thus, this layout builds a comprehensive pipeline for generating high-quality synthetic data.
Furthermore, Nemotron-4-340B-Instruct is a conventional decoder-only Transformer that makes use of Rotary Position Embeddings (RoPE) and Grouped-Query Attention (GQA). It was trained using a sequence length of 4096 tokens.
Thus, a huge token set used in the training data makes it efficient for building and training domain-specific LLMs without requiring large datasets.
Generating Synthetic Data with Nemotron-4-340B-Instruct
Now we will understand the main function of the LLM, that is how you can generate synthetic data to build custom LLMs using Nemotron-4-340B-Instruct.
The Nemotron-4 340B Instruct model generates a variety of synthetic data that closely resembles real-world data, enhancing data quality to boost the robustness and performance of custom LLMs in a variety of domains.
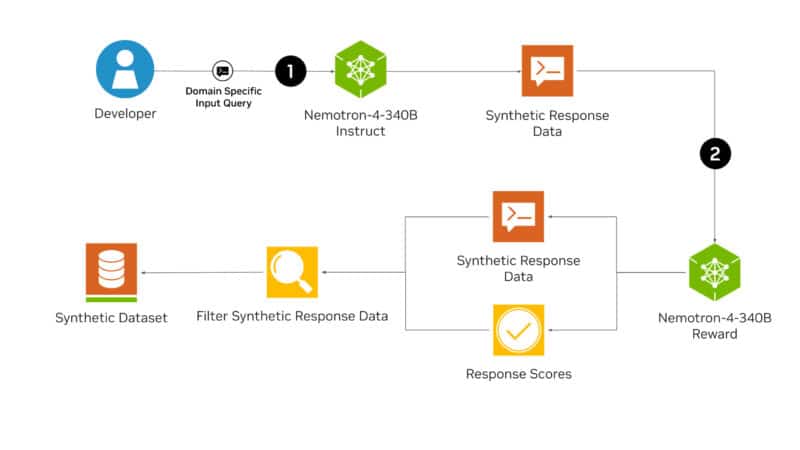
Developers can then utilize the Nemotron-4 340B Reward model to filter for high-quality responses, which will improve the quality of the AI-generated data. Five criteria are used by Nemotron-4 340B Reward to score responses: verbosity, coherence, accuracy, helpfulness, and complexity.
As of right now, it holds the top spot on the AI2-created Hugging Face RewardBench scoreboard, which assesses the strengths, vulnerabilities, and safety of reward models. Without these criteria, it would be difficult to feed the best quality responses to custom LLMs.
Lastly, by combining their private data with the included HelpSteer2 dataset, researchers can further customize the Nemotron-4 340B Base model to construct their own instruct or reward models.
Overall, this shows us that LLMs can be useful in situations where access to big, diverse labeled datasets is limited for developers creating synthetic training data.
Fine-Tuning Nemotron-4-340B
The Nemotron-4 340B Base Model can be tailored using the NeMo framework to fit certain use cases or domains. The base was trained on 9 trillion tokens. Using a large amount of pretraining data, this fine-tuning procedure produces outputs that are more accurate for particular downstream tasks.
Nowadays, it is highly a requirement of developers and gen AI enthusiasts to have an LLM that can be fine-tuned according to their needs and interests. The NeMo framework offers a range of customization options, such as parameter-efficient fine-tuning techniques like low-rank adaptation, or LoRA, and supervised fine-tuning techniques.
Developers can use NeMo Aligner and datasets annotated by Nemotron-4 340B Reward to align their models and improve model quality.
Using methods like reinforcement learning from human feedback (RLHF), a model’s behaviour is refined during alignment, a crucial phase in LLM training, to make sure its outputs are accurate, safe, acceptable for the context, and compatible with the model’s intended goals.
Tensor parallelism, a kind of model parallelism in which individual weight matrices are divided among several GPUs and servers—is a sort of parallelism that is optimized into all Nemotron-4 340B models using TensorRT-LLM. This allows for effective inference at scale.
Looking Into The Benchmarks
Nemotron-4 340B outperforms its competitors, including Mistral’s Mixtral-8x22B, Anthropic’s Claude-Sonnet, Meta’s Llama3-70B, Qwen-2, and even rivals the performance of GPT-4, with an astounding 9 trillion tokens used in training, a 4,000 context window, and support for over 50 natural languages and 40 programming languages.
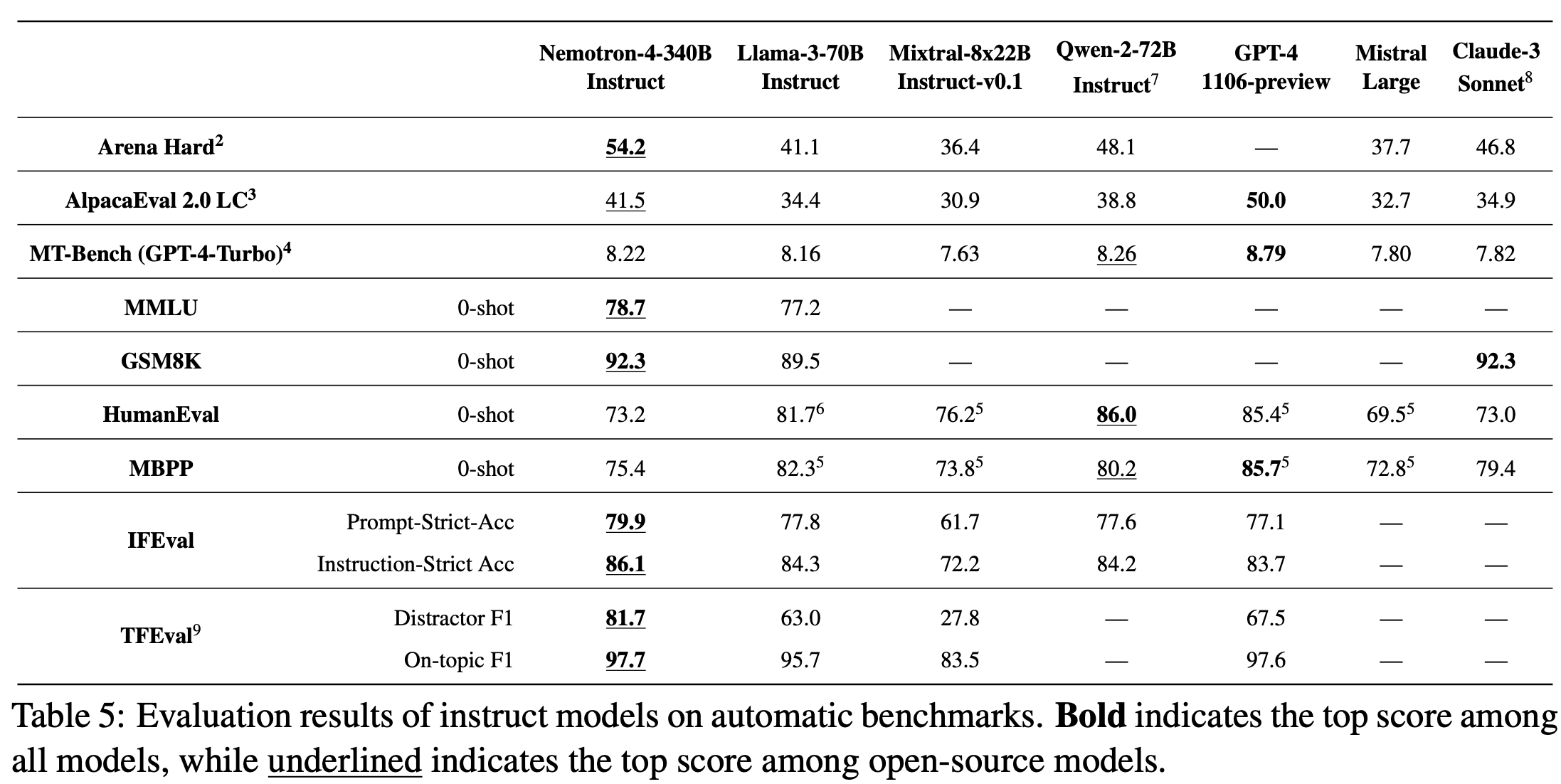
It beats GPT-4o on the IFEval (Instruction Following Evaluation) and TFEval benchmarks, two important evaluations that focus on a set of “verifiable instructions” such as “write in more than 400 words” and “mention the keyword of AI at least 3 times”.
As a consequence, a model that is optimized for mathematical reasoning, coding, and instruction following is created that is in line with human chat preferences and can produce high-quality synthetic data for a range of use scenarios.
Is the Synthetic Data generated safe and secure?
Nemotron-4 340B’s introduction also brings up significant issues regarding the security and privacy of data in the future. Businesses must make sure they have strong security measures in place to protect sensitive data and stop misuse as synthetic data becomes more common.
However, as biases and mistakes in the data may have unforeseen consequences, the ethical issues of utilizing synthetic data to train AI models need to be carefully explored.
Despite the challenges, the AI community has responded to the release of Nemotron-4 340B with excitement and enthusiasm, despite these obstacles. The model has received extremely good early responses from users on the lmsys.org chatbot arena, with many applauding its amazing performance and domain-specific knowledge.
Conclusion
NVIDIA has led a new foundation by redefining synthetic data generation. We can anticipate a wave of innovation and disruption across industries as more companies use Nemotron-4 340B and start producing their synthetic data. Only time will tell how successful this open-source GPT-4 rival becomes in the long run.




