


The world of chatbots gets the latest addition to their family: Chat with RTX. Now use the GPU in your PC to ask questions about your documents or from a YouTube video. So, without any further delay let’s dive into the working depths of this latest development by NVIDIA.
Highlights:
- NVIDIA announces its first AI-powered chatbot ‘Chat with RTX’ that runs locallyPC.
- It can perform various tasks including giving queries on local data files across various file formats.
- Chat with RTX is free to download but requires only works on the GeForce RTX 30 video card series or above.
Chat with RTX: What Sets It Apart?
NVIDIA, a leading company in the market of Video Cards and GPUs, has taken a new step in its AI journey. The company’s first product for consumers offers one-to-one AI services in the form of a chatbot.
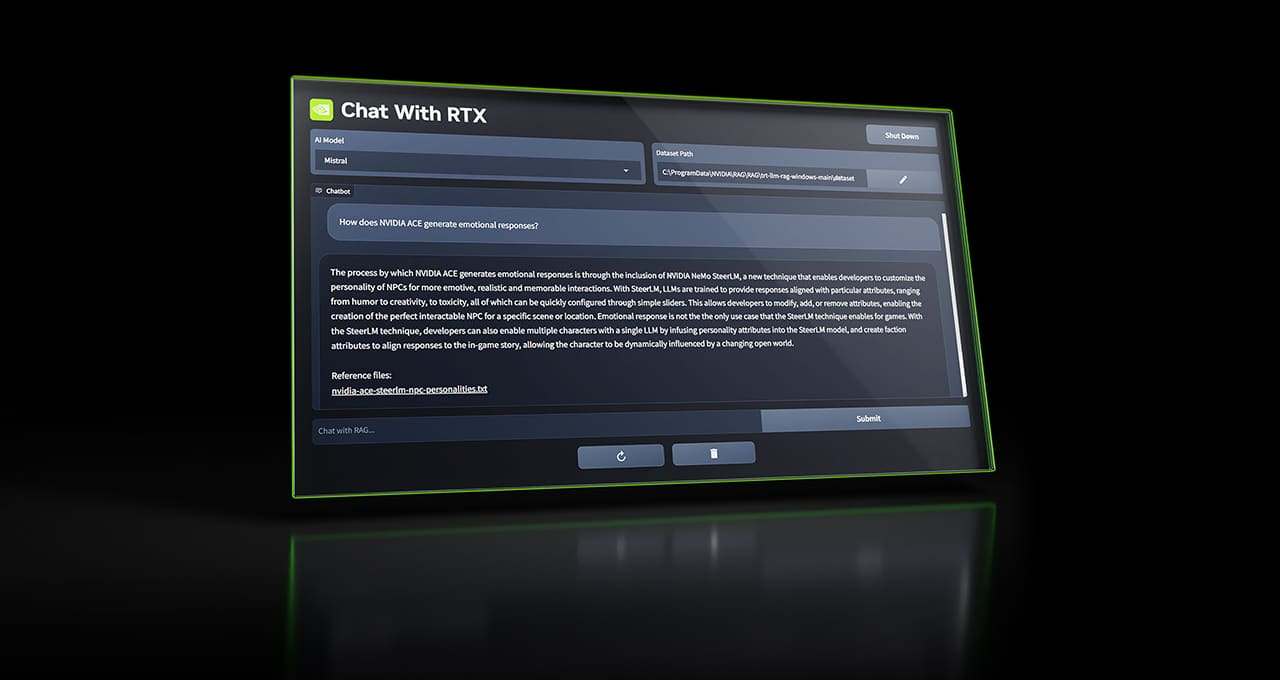
Chat with RTX is an artificial intelligence chatbot from NVIDIA, that can be launched locally on PCs with Nvidia GeForce RTX graphics cards. By providing the chatbot with documents, text files, PDFs, and YouTube videos to power its responses, users can ask queries and get answers from them.
Utilizing an AI chatbot online often involves running queries via an API or utilizing a web platform like ChatGPT, with inference happening on cloud computing servers. The expenses, latency, and privacy issues with exchanging personal or business data are its several disadvantages.
But this breakthrough by GPU company might change things up, with this locally running AI-powered chatbot. They announced Chat with RTX on February 13, 2024, calling it a personalized AI Chatbot that operates without requiring an active internet connection.
How does Chat with RTX Work?
To use Chat with RTX, you need to download it first from NVIDIA’s website and do the basic setup. Then, you need to select the local file to process it. Now, you can ask the questions from the file and it can give you answers from the data of the local file.
Users can utilize Llama 2 or Mistral to develop a customized chatbot with Chat with RTX. It makes use of NVIDIA’s inference-optimizing TensorRT-LLM software and retrieval-augmented generation (RAG). It also lets developers create and implement their own RAG-based RTX applications by providing them with that reference.
Note that Chat with RTX is a local chatbot, meaning it has no awareness of the outside world. On the other hand, users can configure it to do queries on their data, including papers, files, and more. Yet, you can ask questions about the files in a folder on your PC by directing Chat with RTX there. Numerous file formats are supported, such as .txt,.pdf,.doc/.docx, and .xml.
Its flexibility with different types of file formats is highly commendable in this era of online chatbots which have several drawbacks based on costs, latency, and privacy concerns. You can be carefree about the privacy and integrity of your shared data as the model is based on LLM, which analyses locally stored files throughout your operating system.
Also, don’t think its functions are only limited to local operations. It can also be used effectively for summarizing YouTube videos and playlists. For this functionality, you will need an active internet connection, so that it can use the transcripts of the respective videos and answer your queries.
Narrowing the gap between cloud-based online systems and localization functions offline, this Chatbot is great for working with your research assignments, writing thesis or paper articles, and even summarizing online multimedia.
Is Your PC Compatible for Chat With RTX?
NVIDIA’s Chat with RTX is available only for Windows 11 PCs and requires NVIDIA GeForce™ RTX 30 or 40 Series GPU with at least 8GB of VRAM, along with 16GB RAM or more.
The Verge reported that the program has a size of about 40GB and that the Python instance can take up to 3GB of RAM. The article specifically brought up the chatbot’s creation of JSON files inside the directories you ask it to index. Therefore, it could be problematic to give it your whole document folder or a large parent folder.
Consumers will probably interface with LLMs via local AI chatbots that have very low latency and zero API call costs. The adoption of free models, as opposed to conventional ones like GPT, OpenAI, etc, will be fueled by on-device AI thanks to the open-source strategy adopted by businesses like Meta.
This is a big step in laying the focus on localization of Chatbots and will need many more advancements to improve its latency. Mobile and laptop users will have to wait a little longer before RTX GPUs can develop enough efficiency to fit into smaller devices.
Conclusion
As of now, it is safe to say that Chat With RTX is a demo still in its initial phases of development. Even though its approach is different, it lays down the foundation for utilizing LLMs to improve file compatibility and offline access for AI-powered chatbots. Let us wait and find out what’s next for this marvelous innovation!




