



After OpenAI and Google, Mistral joins the LLM race by silently dropping one of the most powerful models yet!
Highlights:
- French start-up Mistral AI silently launches Mixtral 8x22B, its latest open-source LLM model.
- The model adopts the Mixture of Experts (MOE) architecture and shows promising benchmarks compared to Mixtral 8x7B.
- The model weights are available for download on Hugging Face with installation instructions.
So, how good is Mixtral 8x22B? What are its features and improvements compared to the previous Mixtral models? Let’s explore all these topics in-depth through this article.
Why Mixtral 8x22B is So Powerful?
French Startup Mistral AI released its latest Large Language Model named Mixtral 8x22B. Utilizing a sophisticated Mixture of Experts (MoE) architecture, the Mixtral 8x22B model has an astounding 176 billion parameters and a context window with 65,000 tokens.
To balance performance and costs, the sparse MoE strategy gives users access to a variety of models, each specialized in a distinct task area.
The Mixtral 8x22B model is Open-Source and it is accessed for torrent download via Hugging Face. Further instructions to install and run the model are available there. They have given separate instructions on how to run the model in full, half, and lower precisions depending on your system and GPU capabilities.
By committing to open-source development, Mistral not only challenges proprietary models but also solidifies its position as a major player in the AI market.
This is the latest LLM in the Generative AI market, after the release of DBRX by Databricks, OpenAI’s GPT-4 Turbo Vision, and also Anthropic’s Claude 3 (currently the world’s most powerful chatbot).
The model is more affordable and easier to use even if it only needs about 44 billion active parameters for each forward pass despite its enormous magnitude. Thus, it provides effective computing and enhanced performance for a variety of jobs.
The AI model 8X22B from Mistral is autocomplete. These are usually not the same as the chat or instruct versions of AI models. While Meta’s Code Llama 7B and 13B are teach models, OpenAI’s ChatGPT and Google’s Gemini AI are chat models.
To offer the appropriate response, chat models must be able to comprehend natural language and contextual inquiries. Typically, developers utilize instruct models to provide AI model instructions on how to complete a task. On the other hand, the sentence given in the prompt is completed using an autocomplete model.
The release of the Mixtral 8x22B model is indicative of a larger movement in AI development towards more transparent, cooperative methods.
This change is being led by Mistral AI, a company created by former employees of Google and Meta that promotes a more open ecosystem where researchers, developers, and enthusiasts may contribute to and make use of cutting-edge AI technology without having to pay exorbitant fees or overcome obstacles to access.
Looking into Benchmarks: How it Compares?
Known for its completely open-source AI models, Mistral unorthodoxly released its most recent model without any accompanying blog entries or announcement posts.
Despite the lack of official benchmarks from the AI company, users of the Hugging Face community tested it and shared benchmark results for the 8X22B model. The outcomes seem to become closer to the closed models developed by Google and OpenAI.
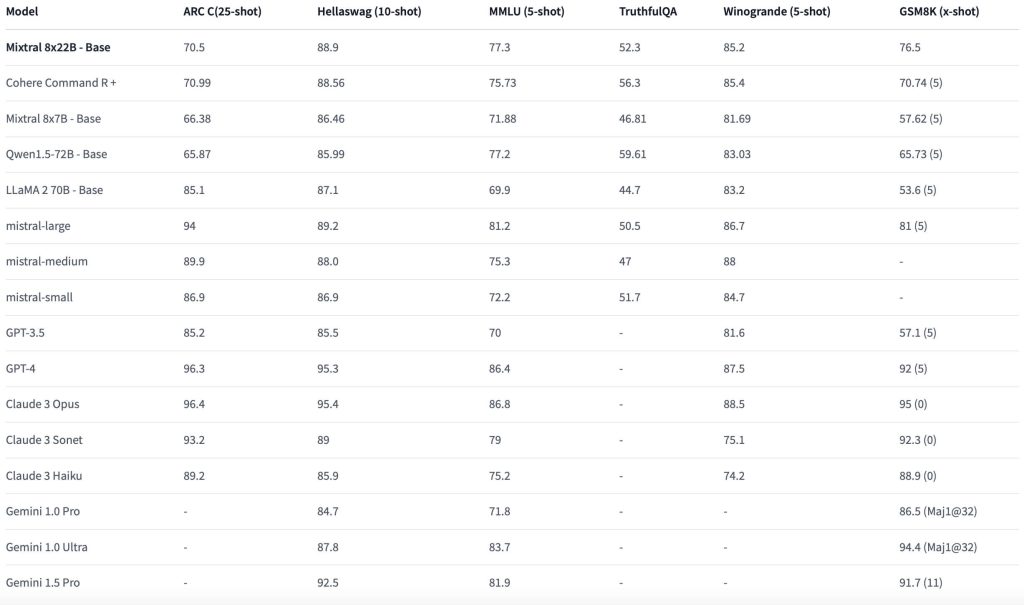
Reasoning Abilities
We can see from the above comparison that Mixtral 8x22B has a good ARC C score of 70.5. ARC-C is a good evaluation metric for testing an LLM’s reasoning abilities.
The ARC-C Challenge Set contains 2590 questions that at least one of a retrieval-based and a word co-occurrence algorithm—the Information Retrieval (IR) Solver and the Pointwise Mutual Information (PMI) Solver—incorrectly answered.
Even though it has better scores than previous Mixtral models, it still falls behind the GPT and Claude model families. This shows it is the most powerful reasoning model in the Mixtral family but it has work to do in catching up with GPT and Claude families.
Commonsense Reasoning
Mixtral 8x22B has a very good score of 88.9 in the HellaSwag benchmark. This metric is a good test for measuring an LLM’s commonsense reasoning abilities. Mixtral does well in keeping up with Gemini 1.0 Ultra and GPT-3.5 but falls behind Gemini 1.5 Pro and GPT-4.
So for common sense reasoning problems involving day-to-day variables, Mixtral 8x22B can show highly promising capabilities but not outstanding.
Natural Language Understanding
Massive Multi-Task Language Understanding, or MMLU benchmark, is a comprehensive assessment framework that evaluates machine learning model performance on many natural language understanding tasks at once.
Mixtral 8x22B achieves a fair score of 77.3 here and shows improvement compared to the previous Mixtral models. However, it still shows a similar trend falling behind the Gemini, Claude and GPT models. Still, it can perform fairly well in NLP-related tasks, which is highly important in today’s LLMs for solving Machine Learning projects for developers.
Truthfulness
A benchmark called TruthfulQA is used to assess how truthful a language model is when producing responses to queries. The benchmark consists of 817 questions covering 38 topics, such as politics, law, money, and health. The authors created questions that people with erroneous beliefs or misconceptions might answer incorrectly.
In the comparison chart above Mixtral 8x22B has a higher TruthfulQA score than the previous Mixtral models however no comparison was shown with GPT, Gemini, and Claude models.
We can conclude that 8x22B will perform fairly well when it comes to truthfulness. This is highly important as most LLMs nowadays are suffering from Hallucinations and produce a whole lot of incorrectly generated content.
Mathematical Reasoning
GSM8K (Grade School Math 8K) is a dataset of 8.5K high-quality linguistically diverse grade school math word problems. The dataset was created to support the task of question answering on basic mathematical problems that require multi-step reasoning. It is a good benchmark to measure an LLM’s Mathematical Reasoning capabilities.
Mixtral 8x22B achieves a good score here of 76.5, however, it yet again falls behind the GPT, Claude, and Gemini families. You can use Mixtral for normal average mathematical problems but stick to Claude and Gemini for complex problems requiring more processing capabilities.
Mistral is currently on a roll, with its GPT-4 competitor Mistral Large and Le Chat unveiled just a few weeks ago.
Conclusion
The AI community’s initial responses have been largely positive. Many are excited about the novel uses and ground-breaking research that Mixtral 8x22B will make possible. As developers and researchers work to fully realise the potential of this potent model, it is anticipated to completely transform several technical industries globally.




