



After Llama 3.1 made waves, a more powerful model is now released. French AI startup Mistral has launched its own open-source Mistral Large 2. The company says its model outperforms all its competitors regarding various benchmarks like coding and reasoning.
Highlights:
- Mistral Large 2 achieves superior performance over Meta’s new model Llama 3.1, especially in MMLU and programming language proficiency.
- The model has 123B+ parameters, and good architecture and the training methodologies are strong enough to make it one of the best models available in the market right now.
- It is very useful for day-to-day practical applications and it is also open-source for non-commercial activities.
Mistral Large 2 vs Llama 3.1 Performance
Mistral Large 2 overtook Llama 3.1 exceptionally in several key areas. It is a 123-billion-parameter large language model (LLM) almost 1/3ed of Meta’s 405B Llama 3.1 model but still gives amazing results.
That happened just before Meta launched 3 new models, the largest one being Llama 3.1 405B. They are also calling it “Open-Source”.
“Today, we are announcing Mistral Large 2, the new generation of our flagship model. Compared to its predecessor, Large 2 is significantly more capable in code generation, mathematics, and reasoning. It also provides a much stronger multilingual support, and advanced function calling capabilities.”
This leap in performance is particularly evident in languages such as French (FR) and Portuguese (PT), where Large 2 consistently outperformed Llama 3.1.
This performance shows how much extensive training the model had to go through to achieve this level. Large 2 currently understands English, French, German, Spanish, Italian, Portuguese, Arabic, Hindi, Russian, Chinese, Japanese, and Korean, along with 80 coding languages including Python, Java, C, C++, JavaScript, and Bash.
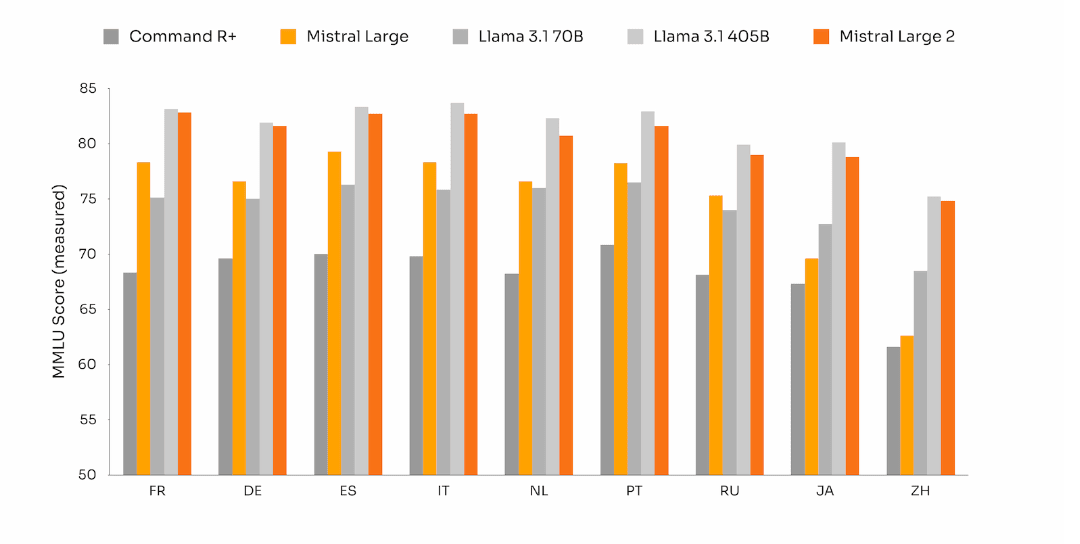
As you can see in the graph below, Large 2 scored exceptionally well in TypeScript and C++, with scores of 86.8% and 84.5%, respectively, surpassing Llama 3.1 and even GPT-4o in several categories.
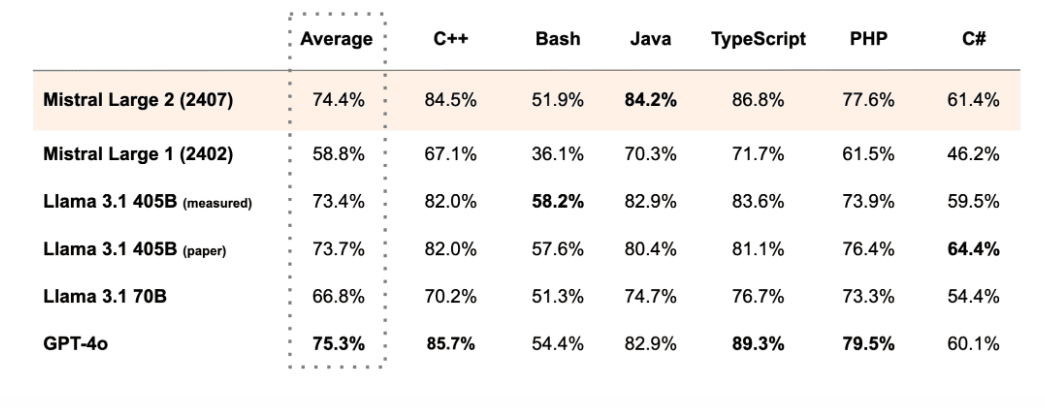
Especially in programming languages, the model secured 74.4% on average whereas Llama 3.1 405B secured 73.4%.
Mistral Large 2 in Real-World Tasks
Mistral Large 2 demonstrates remarkable performance in real-world applications, particularly in the area of code generation. As you can see in the below graph, the accuracy of the model in code generation benchmarks like MBPP Base is impressive.
In the Human Eval benchmark, Large 2 achieved an accuracy of 94%, surpassing its competitors and proving itself that it can write dependable and efficient code.
Furthermore, it has exhibited its capabilities well in handling complex mathematical problem-solving tasks. Its capacity to comprehend and solve tough mathematical problems with high accuracy makes it a valuable asset for educational and research purposes.
The company remarked that they focused mainly on reducing hallucinations and improving accuracy. It’s mathematical performance is the key factor that helps it distinguish itself from other models, including Llama 3.1.
“We are releasing Mistral Large 2 under the Mistral Research License, that allows usage and modification for research and non-commercial usages. For commercial usage of Mistral Large 2 requiring self-deployment, a Mistral Commercial License must be acquired by contacting us.”
“The company is making Mistral Large 2 available on its platform, la Plateforme under the name mistral-large-2407, and the general public can test it on le Chat. It has also released the weights for the instruct model on HuggingFace for research purposes.
Large 2 has 123B parameters and can be accessed on all the major cloud service providers, including Amazon Web Service, Google Cloud and Microsoft Azure.
Conclusion
The release of Mistral Large 2 is a huge advancement in the field of AI because it is like a challenge for other companies to outdo it. It not only raises the bar but also sets new standards for what can be achieved with AI language models in the future. Let us see how the other companies respond to it.




