



While we are still waiting for SORA, new tool announcements and research on Image-to-Video are coming up almost every week. Now, Microsoft joins the race with VASA-1!
Highlights:
- Microsoft’s new framework VASA-1 can generate hyper-realistic videos through just a single photo and speech audio.
- The results showed improved lip movement along with various facial representations.
- It’s built using a diffusion-based holistic facial dynamics and head movement generation model and advances far beyond any previous models.
Here is an example of Mona Lisa singing Paparazzi, made with VASA-1:
Microsoft just dropped VASA-1.
— Min Choi (@minchoi) April 18, 2024
This AI can make single image sing and talk from audio reference expressively. Similar to EMO from Alibaba
10 wild examples:
1. Mona Lisa rapping Paparazzi pic.twitter.com/LSGF3mMVnD
What Can Microsoft’s VASA-1 Do?
Yesterday, Microsoft researchers released VASA-1, a framework for generating lifelike talking faces of virtual characters with appealing visual affective skills (VAS), given a single static image and a speech audio clip.

Through a single picture and a voice sample, the model can create a lifelike human deepfake! Here is what they shared in the official release:
“Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness.”
This technology takes a promising step towards enriching digital communication, increasing accessibility for those with communicative impairments, transforming education methods with interactive AI tutoring, and providing therapeutic support and social interaction in healthcare.
Recently, Google DeepMind has also introduced the VLOGGER AI Model that produces lifelike videos of the image subject. But The results for VASA-1 are quite impressive:
4. Out-of-distribution generalization – singing audios pic.twitter.com/h7BvTq4vAE
— Min Choi (@minchoi) April 18, 2024
It is built on an innovative method that includes a diffusion-based holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos.
The model was not only extensively tested but also evaluated on a new set of metrics against existing video models. This innovative method significantly outperforms previous models on various parameters.
How is it better than the previous methods?
Despite deepfakes and facial recreation with audio gaining much attention in recent years, pre-existing techniques aren’t yet close to achieving an authentic replication of human faces.
Researchers have been heavily focused on the precision of lip synchronization and the creation of convincing facial expressions and subtle nuances of human faces have flown under the radar. This results in robotic and rigid faces that are quite easy to distinguish from actual human faces.
Another area that has been largely neglected is that of natural head movements. While recent research has tried to replicate realistic head movements, there is a very noticeable difference between human and generated faces.
The large computational resources required for real-time communication efficiency in generated videos have limited the practical application of these models.
The VASA-1 framework presented in this paper has significantly advanced the state-of-the-art in audio-driven talking face generation.
Here is another example that shows how great it is in generating hyper-realistic videos:
10. Realism and liveliness – example 2 pic.twitter.com/ZaS3MYJbTm
— Min Choi (@minchoi) April 18, 2024
The method has collectively achieved new levels of realism in lip-audio synchronization, facial dynamics, and head movements. Combined with high-quality image generation and efficient real-time performance, VASA-1 can produce talking face videos that are highly realistic and lifelike.
The creators believe that VASA-1 represents an important step towards a future where digital AI avatars can engage with humans naturally and intuitively, exhibiting appealing visual affective skills that enable more dynamic and empathetic information exchange.
How VASA-1 works?
Given the previous limitations, researchers developed an efficient yet powerful model that works in the latent space of head and facial movements. The developers of this model trained a diffusion transformer model on the latent space of holistic facial dynamics as well as head movements.
The challenge in this goal was constructing the latent space for the previously mentioned facial dynamics and gathering data for the diffusion model training. The researchers wanted to build the latent space that possesses both- a total state of disentanglement between facial dynamics and other factors as well as a high degree of expressiveness to model rich facial details.
Now you must be thinking, what exactly is latent space of holistic facial dynamics?
Instead of modelling facial attributes like blinking, expressions, gaze, and lip movement separately, the paper proposes a method to consider all facial dynamics as a single latent variable and model its probabilistic distribution.
Specifically, the research trains encoders to decompose a facial image into several disentangled latent factors:
- 3D appearance volume (Vapp): This is a 3D feature volume that represents the canonical 3D appearance of the face.
- Identity code (zid): This latent code encodes the identity-specific information of the face, independent of its appearance, dynamics, and head pose.
- 3D head pose (zpose): This latent code represents the 3D orientation and position of the head.
- Holistic facial dynamics code (zdyn): The holistic facial dynamics code (zdyn) captures comprehensive facial movements, including lip motion, expressions, eye gaze, blinking, and other nuanced facial behaviours.
By modeling the facial dynamics in this holistic latent space using the diffusion transformer model, the researchers aim to enable the generation of a diverse array of lifelike and emotive talking behaviours, in contrast to previous methods that often apply separate models for different facial attributes.
The overall framework generates holistic facial dynamics and head motion in the latent space conditioned on audio and other signals instead of generating video frames directly.
Based on these latent space variables, the model then produces video frames by a face decoder which also takes the appearance and identity features extracted using a face encoder from the input image as input.
Trained on face videos in a self-supervised or weakly-supervised manner, their encoder can produce well-disentangled factors including 3D appearance, identity, head pose and holistic facial dynamics, and the decoder can generate high-quality faces following the given latent codes.
Results of VASA
The authors used two benchmark datasets for the evaluation:
- VoxCeleb2 Subset: The authors randomly selected 46 subjects from the VoxCeleb2 test split and sampled 10 video clips for each, resulting in a total of 460 clips. The video clips are 5-15 seconds long, predominantly consisting of interviews and news reports.
- OneMin-32 Dataset: The authors collected an additional dataset of 32 one-minute video clips from 17 individuals, featuring more diverse talking styles such as coaching sessions and educational lectures.
The authors evaluated the key aspects of the generated talking face videos as compared to other previously built frameworks to test the performance of VASA.
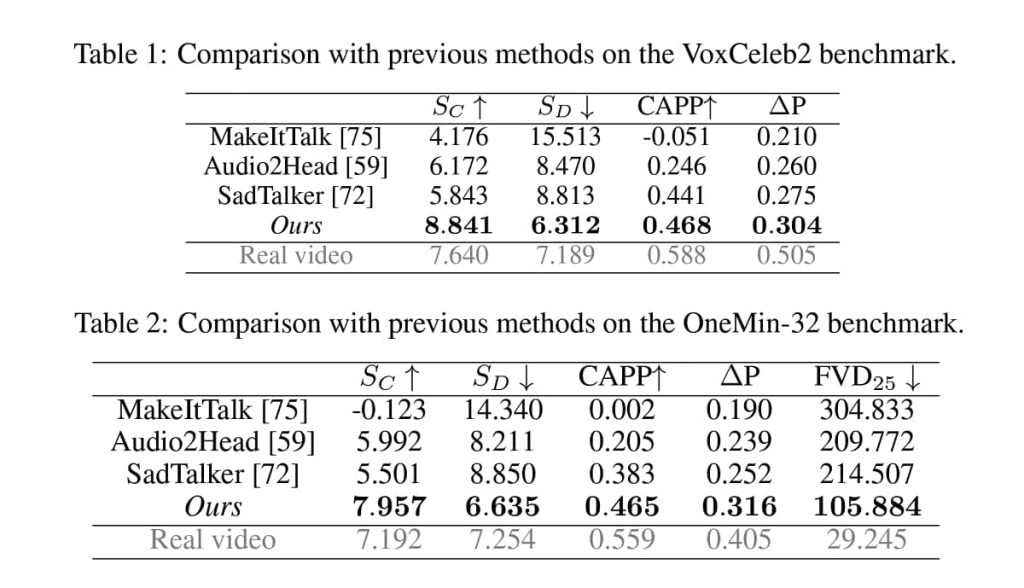
The results show that VASA-1 achieves state-of-the-art performance across all the evaluated metrics, significantly surpassing previous audio-driven talking face generation methods. The authors conclude that VASA-1 represents a major advancement towards realistic and lifelike AI-generated avatars that can engage with humans in a natural and empathetic manner.
SORA is also capable of transforming Images to Videos, but we don’t know how good it will be for doing facial expressions.
Conclusion
VASA is an astounding product that accurately represents not only lip movements but also emotions, facial dynamics, and the perceived gaze of a person. All this is simply based on a single image and audio sample!
While the researchers clarified the purpose of building a framework like VASA-1, we can’t help but wonder about the possible misuse of a technology that lets you effortlessly clone and imitate people’s voices and likenesses. Many X users also noted that the release of this technology so close to the elections could be dangerous.
In general, this technology could be devastating in the wrong hands as a user could make a public figure say or do anything offensive which may threaten the stability of our society.




