



Meta AI and a group of researchers at the University of Southern California introduced a new Machine Learning-based Large Language Model named Megalodon.
Highlights:
- Meta along with a group of researchers introduced Megalodon, an ML-based LLM that can challenge the transformer architecture.
- Comes with a MEGA architecture that uses Complex Exponential Moving Average (CEMA), which assists models inappropriately emphasizing both short- and long-term correlations between tokens.
- Achieves commendable results in comparison to Llama 2-7B and Llama2-13B.
The Significance of Megalodon LLM
LLMs have skyrocketed in the last few years, thanks to innovations from OpenAI, Anthropic’s Claude family, and Google’s Gemini. However, due to their transformer architecture, many of today’s LLMs face several drawbacks in their functioning and processing capabilities.
Meta’s Megalodon LLM aims to solve some of the major issues current LLMs face. Language models can now expand their context window to millions of tokens using the new model, without consuming a significant amount of RAM.
Experiments reveal that Megalodon processes huge texts more efficiently than Transformer models of equivalent size. This LLM is the most recent in a line of new models being considered to replace the transformer architecture.
“The Transformer architecture, despite its remarkable capabilities, faces challenges with quadratic computational complexity and limited inductive bias for length generalization, making it inefficient for long sequence modeling. We introduce MEGALODON, an improved MEGA architecture, which harnesses the gated attention mechanism with the classical exponential moving average approach.”
How many tokens a model may operate on at once is called the “context window.” Longer talks, longer document processing sessions, and enhanced in-context learning capabilities are all made possible by larger context windows for LLMs. The cost of expanding Transformers’ context window is high, though.
Because of the Transformer’s “quadratic complexity,” processing an input requires quadruple as much memory and computational power as it does for every two times its size. The self-attention mechanism in transformers, which compares each element in the input sequence with every other element, is responsible for this quadratic relationship.
Moving Average Equipped Gated Attention (MEGA), a method that was first introduced in 2022, is the foundation for Meta’s Megalodon. By altering the attention mechanism in a way that drastically lowers the model’s complexity, MEGA allows the LLM to handle lengthier inputs without drastically increasing its memory and computation needs.
In addition, MEGA makes use of exponential moving average (EMA), a tried-and-true method that assists models inappropriately emphasizing both short- and long-term correlations between tokens. As more data is added to the context window, this can aid in the models’ continued coherence.
Looking into Megalodon’s MEGA Architecture
Megalodon comes with a highly efficient renovative architecture that makes it efficient to work with in comparison to transformer-based LLMs.
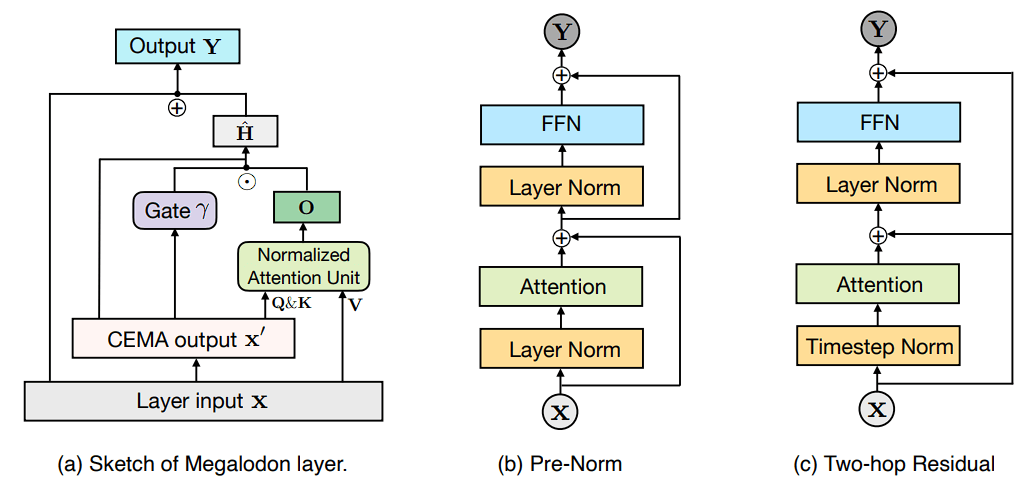
Firstly, MEGALODON presents the multi-dimensional dampened EMA in MEGA to the complex domain by introducing the complex exponential moving average (CEMA) component.
The timestep normalization layer, which MEGALODON then suggests, extends the group normalization layer to autoregressive sequence modelling tasks and enables normalization along the sequential dimension.
In addition, it uses normalized attention in conjunction with a pre-norm with a two-hop residual design to enhance large-scale pretraining stability. This is achieved by altering the commonly used pre and post-normalization techniques.
Overall, with a few significant architectural changes, Megalodon considerably enhances MEGA, putting its performance on par with the full-attention mechanism from the original Transformer model.
To reduce the complexity of the model from quadratic to linear, Megalodon additionally employs “chunk-wise attention,” which splits the input sequence into fixed-size segments. Additionally, an additional layer of parallelism that accelerates model training can be added thanks to chunk-wise attention.
Comparison with Traditional LLMs
With two trillion tokens, the researchers trained a version of Megalodon with seven billion parameters.
They then compared the results to models such as Llama-2-7B, 13B, and others. In terms of training perplexity as well as across downstream benchmarks, Megalodon-7B “significantly outperforms the state-of-the-art variant of Transformer used to train LLAMA2-7B,” according to study findings. Megalodon-7B rivals Llama-2-13B’s performance in certain activities.
Megalodon is marginally slower than Llama-2 with a 4,000-token context window, but because of its computational efficiency, it performs much better when the context length is increased to 32,000 tokens.
Moreover, the findings of long-context modelling experiments, according to the researchers, indicate this new LLM is capable of modelling sequences with infinite length.
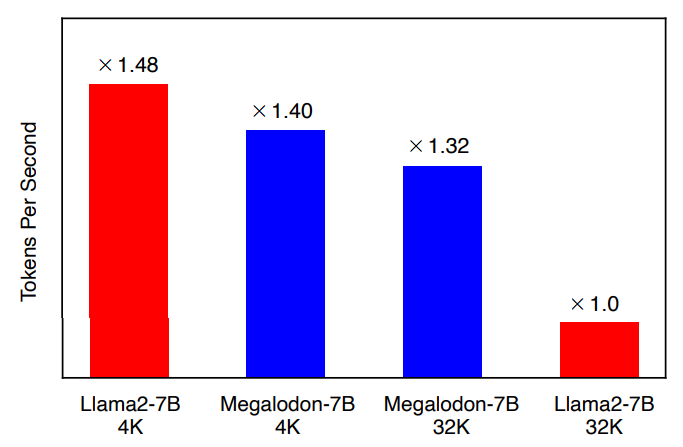
Because of the addition of CEMA and Timestep Normalisation, MEGALODON-7B performs marginally slower (by around 6%) than LLAMA2-7B under 4K context length. MEGALODON-7B is much faster (by roughly 32%) than LLAMA2-7B when the context length is increased up to 32K, proving the computational efficiency of MEGALODON for long-context pertaining.
Furthermore, MEGALODON-7B-32K, which makes use of chunk parallelism, utilizes MEGALODON-7B-4K to the tune of approximately 94%.
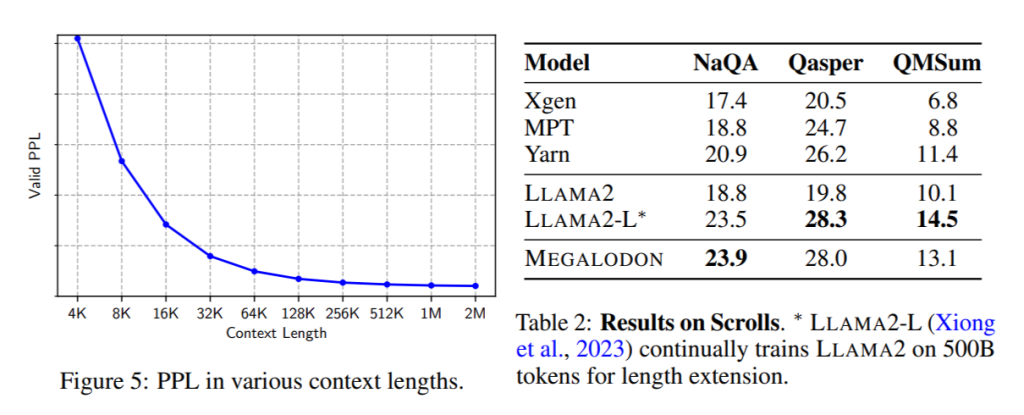
Additionally, the researchers’ small- and medium-scale trials on various data modalities have yielded encouraging results, and they plan to work on modifying Megalodon for use in multi-modal environments later on. In certain tasks, MEGALODON-7B performs on par with LLAMA2-13B, if not better.
Please take note that the results are not directly comparable to MEGALODON-7B because Mistral-7B and Gemma-8B were pre-trained on substantially larger datasets.
Are Transformer LLMs Declining?
Researchers have been searching for transformer substitute architectures. The Mamba architecture, which is currently being used commercially with AI21 Labs Jamba, is one of the prominent instances.
But for the time being at least, Transformers are still the most popular architecture for language modeling. Meta is working on enhancing its Transformer models and has recently released Llama-3, the most recent version of its open-source LLMs, while also investigating architectures like Megalodon.
Adequate hardware and software tools present another obstacle for opponents of Transformer-based LLMs. For training, optimizing, and modifying Transformer models for various hardware devices and applications, a vast ecosystem of libraries and tools is available.
In parallel, developers of low-level software have created code that maximizes Transformer LLM performance on devices with limited memory. These advancements are still ahead of the alternatives.
Transformer-based LLMs like OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude 3 family all utilize transformer architectures which allow them to be multimodal and respond to several queries from users.
They are still the top-notch LLMs in the Gen AI market and they don’t seem to be replaced soon. Google’s Gemini is quite an exception as even though it is a Transformer LLM, it comes with a one million context window feature, which highly races beyond the capabilities of LLMs.
However, as AI research continues to progress, we may see a potential upcoming LLM similar to Megalodon, to replace these transformer models in the Gen AI race.
Conclusion
Megalodon is a groundbreaking advancement from Meta-researchers in the field of Generative AI. It’s the first of its kind to come without a transformer architecture and it is highly efficient as it ranks well with Meta’s Llama 2.




