



Researchers have proposed that training AI large language models (LLMs) to predict many tokens at once can increase their speed and accuracy.
Highlights:
- Researchers conducted a study that shows Multi Token Prediction can speed up AI Models to predict many tokens at once.
- The study shows impressive results compared to the traditional next-token prediction, as it speeds up AI models up to 3 times.
- Has various research potentials such as block optimization strategies and vocabulary sizes.
Meta’s Multi Token Prediction Explained
Meta has been coming up with several advancements in the field of Generative AI over the last few weeks. Just days ago, it released its AI Assistant named Meta AI on WhatsApp, Instagram and Messenger. They also released Llama 3, which is one of the most powerful LLMs out there.
Now they are offering a new insight into how AI Models can be sped up to three times their original efficiency. This new study focuses on Meta’s Multi Token Prediction.
Researchers demonstrate in this study that improving the sample efficiency of LLMs may be achieved by training them to predict multi tokens simultaneously.
With multi token prediction, the LLM is instructed to simultaneously predict several future tokens from each position in the training data. A straightforward multi token prediction architecture that doesn’t require additional training time or memory overhead is proposed by the researchers.
“Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency.”
Fabian Gloeckle, primary author, in Meta’s research paper.
The technique retains its usefulness when training for numerous epochs and becomes more beneficial for larger model sizes. Multi token prediction is an inexpensive and simple method to train transformer models that are faster and more powerful.
With treble speeds and improved performance on generative tasks, multi-token prediction offers significant advantages in certain areas even though it is not a universal solution for every kind of model and language activity. Although there is still much to be improved upon, the method has the potential to be an effective tool for some LLM applications.
An Improvement Over Next-Token Prediction
“Next-token prediction,” a self-supervised learning strategy where the model is given a sequence of tokens and must predict the next one, is the traditional method of training LLMs.
One token at a time, it then repeats the operation after adding the anticipated token to the input. By repeatedly applying this to big text corpora, the model picks up broad patterns that enable it to produce cohesive text passages.
However, even with the recent wave of outstanding advancements, next-token prediction is still an ineffective method for developing language, general knowledge, and reasoning skills. The limitations of next-token prediction in language acquisition, general knowledge acquisition, and reasoning skills have been examined and reported by researchers.
More specifically, when using next-token prediction, teachers tend to ignore “hard” decisions in favour of local trends. Thus, it continues to be true that in order for state-of-the-art next-token predictors to reach the same level of fluency as human children, orders of magnitude more data are required.
Concentrating solely on a single token causes the model to become overly susceptible to local trends and ignore predictions that necessitate longer-term thinking. Massive volumes of data are also needed for models trained on next-token prediction to achieve fluency levels that people achieve with significantly less material.
How was the Study Conducted?
A straightforward multi-token prediction architecture without any train time or memory expense was suggested by the researchers. The model borrows the Transformer’s general structure, but it contains many independent output heads—one for each token it wishes to predict—instead of a single output.
For each prediction head during inference, the model employs the fundamental next-token prediction strategy; the additional output heads are used to expedite the decoding process. The model leverages other related works in the field.
More precisely, the model was trained on a shared model trunk and instructed to predict the next n tokens at each place in the training corpus using n separate output heads.
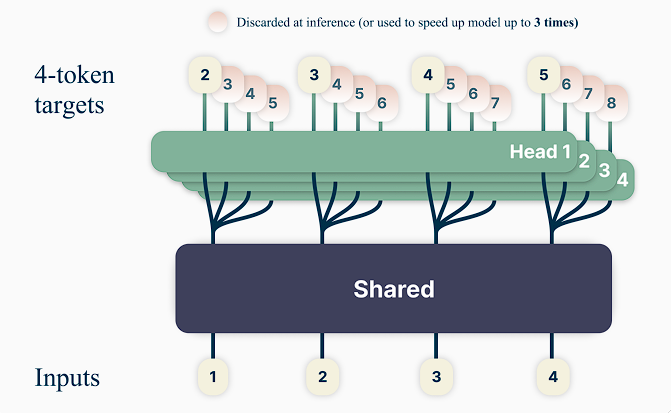
Through a range of tasks using models with 300 million to 13 billion parameters, the researchers evaluated the new multi-token prediction approach. They trained models of six sizes from scratch on at least 91B tokens of code.
What did the Results show?
The findings from the researchers were quite impressive. Among their findings are a number of noteworthy observations. Multi-token prediction, for instance, produces poorer results on smaller models but gains utility with increasing model size.
Models with 6.7 billion and 13 billion parameters outperformed the baseline single-token prediction on the MBPP coding benchmark by several percentage points when trained for 4-token prediction.
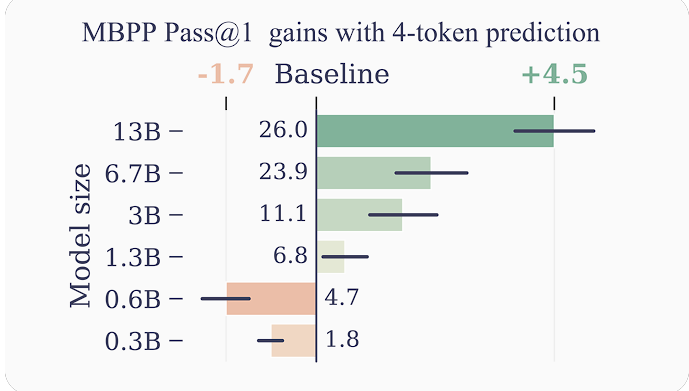
The researcher’s models were able to fully realize the potential of self-speculative decoding because pretraining with multi-token prediction makes the additional heads far more accurate than just fine-tuning a next-token prediction model.
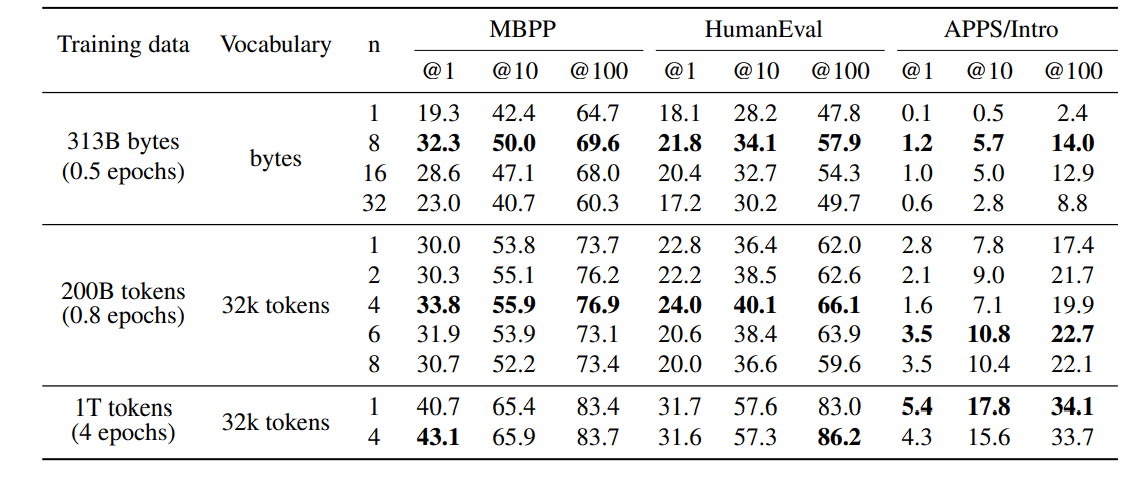
The researchers used the most extreme example of byte-level tokenization to demonstrate how the next-token prediction job latches to local patterns. To do this, they trained a 7B parameter byte-level transformer on 314B bytes or around 116B tokens.
When compared to next-byte prediction, the 8-byte prediction model performs remarkably better, answering 67% more issues on MBPP pass@1 and 20% more problems on HumanEval pass@1.
Therefore, multi-byte prediction is a very promising way to enable effective byte-level model training. For the 8-byte prediction model, self-speculative decoding can reach speedups of 6 times, which would enable it to fully offset the cost of longer byte-level sequences at inference time and even outperform a next-token prediction model by almost 2 times.
Additionally, across a wide range of batch sizes, multi-token prediction speeds up models at inference time by up to three times.
The Impact on Research and Development
Scientists are thinking about a variety of potential research avenues in the future, such as methods for automatically determining the ideal amount of tokens to predict and examining the relationship between vocabulary sizes and multi-token predictions.
There is still potential for improvement in multi-token prediction. For instance, the type of task and size of the model determines the ideal quantity of tokens to predict.
The promise for faster inference and improved accuracy at little or no additional cost for generative tasks like code completion is what might make this research and its subsequent iterations valuable for enterprise applications. It can work with other Transformer block optimization strategies because it preserves the majority of the LLM design.
Conclusion
The study successfully proposes multi-token prediction as an improvement over next-token prediction in training language models for generative or reasoning tasks. This is a new insight towards speeding up AI models as compared to before.




