



Microsoft recently released a research paper on LLMLingua 2, a novel compression model for prompt compression. Let’s look at how it works!
Highlights:
- Microsoft Research released LLMLingua 2, a novel approach for task-agnostic prompt compression.
- It can reduce the lengths of prompts to as small as 20 percent of the original prompt while functioning 3-6x faster than its predecessor LLMLingua
- It is openly available for use on open-source collaboration platforms GitHub and HuggingFace.
Why do we need to Compress Prompts?
Optimizing the length of a prompt is very important. Longer prompts can lead to higher costs and increased latency which will affect the overall performance of a model. This will hurt the LLM in terms of its efficiency.
There are various challenges associated with long prompts:
- Higher Costs: Operating Large Language Models (LLMs), especially when dealing with lengthy prompts, can incur significant computational expenses. Longer prompts need high computational resources to process, thus contributing to higher operational costs.
- Increased Latency: The processing of lengthy prompts consumes a higher amount of time which in turn slows down the response time of LLs. Such delays can rescue the efficiency of AI-generated outputs
To overcome these issues, prompts have to be compressed so that the performance of LLMs can be optimized. The advantages of prompt compression are:
- Improved Efficiency: Compression of prompts reduces the time required by LLMs to process data. This leads to faster response times and improved efficiency.
- Optimised Resource Utilization: Smaller prompts ensure that AI systems function efficiently without any unnecessary overhead. This ensures that computational resources are optimally utilized.
- Cost Reduction: By shortening prompts, computational resources required to operate LLM can be reduced, thus resulting in cost savings.
Compressing a prompt is not just about shortening its length and reducing its words. Rather, it’s about understanding the exact meaning of the prompt and then suitably reducing its length. That’s where LLMLingua2 comes in.
What is LLMLingua 2?
LLMLingua 2 is a compression model developed by Microsoft Research for task-agnostic compression of prompts. This novel task-agnostic method ensures that this technique works across various tasks, thus eliminating the requirement for specific adjustments based on different tasks every time.
LLMLingua 2 employs intelligent compression techniques to shorten lengthy prompts by eliminating redundant words or tokens while preserving important information. Microsoft Research claims that LLMLingua 2 is 3-6 times faster than its predecessor LLMLingua and similar methodologies.
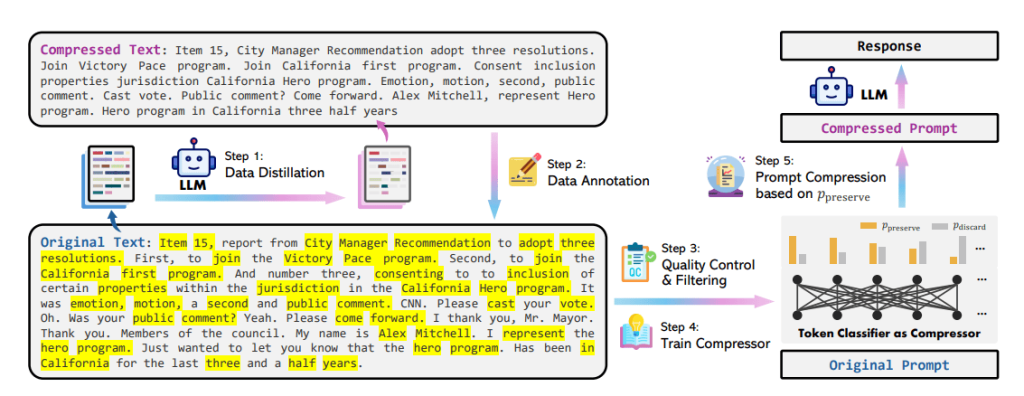
The steps involved in this technique are:
Data Distillation
To extract knowledge from the LLM for effective prompt compression, LLMLingua 2 prompts GPT-4 to generate compressed texts from original texts that satisfy the following criteria:
- Token reduction
- Informativeness
- Faithfulness
However, the team developing LLMLingua 2 found that distilling such data from GPT-4 is a challenging process as it does not consistently follow instructions.
Experiments determined that GPT-4 struggles to retain essential information from texts. GPT-4 tended to modify expressions in the original content and sometimes came up with hallucinated content. So, to overcome this, they came up with a solution for distillation.
To ensure the text remains faithful, they explicitly instructed GPT4 to compress the text by discarding unimportant words in the original texts only and not adding any new words during generation.
To ensure token reduction and informativeness, previous studies had specified either a compression ratio or a target number of compressed tokens in the instructions.
However, GPT-4 often fails to adhere to this. The density of text could vary depending on the genre, and style. Also, within a specific domain, the information density from different people could vary.
These factors suggested that a compression ratio might not be optimal. So, they removed this restriction from the instructions and instead prompted GPT04 to compress the original text as short as possible while retaining as much essential information as feasible.
Given below are the instructions used for compression:

They also evaluated a few other instructions that were proposed in LLMLingua. However, these instructions were not optimal for LLMLingua 2. The instructions are:

Data Annotation
The compressed versions from the previous step are compared to the original versions to create a training dataset for the compression model. In this dataset, every word in the original prompt is labelled indicating whether it is essential for compression.
Quality Control
The two quality metrics to assess the quality of compressed texts and automatically annotated labels are:
- Variation Rate: It measures the proportion of words in the compressed text that are absent in the original text
- Alignment Gap: This is used to measure the quality of the annotated labels
Compressor
They framed prompt compression as a binary token classification problem, distinguishing between preservation and discarding, ensuring fidelity to the original content while maintaining the low latency of the compression model.
A Transformer encoder is utilized as the feature extractor for the token classification model, leveraging bidirectional context information for each token.
Prompt Compression
When a prompt is provided, the compressor trained in the previous step identifies the key data and generates a shortened version while also retaining the essential information that will make the LLM perform effectively.
Training Data
They used an extractive text compression dataset that contained pairs of original texts from the MeetingBank dataset along with their compressed text representations. The compressor has been trained using this dataset.
Prompt Reconstruction
They also attempted prompt reconstruction by conducting experiments of prompting GPT-4 to reconstruct the original prompt from the compressed prompt generated by LLMLingua 2. The results showed that GPT-4 could effectively reconstruct the original prompt. This showed that there was no essential information lost during the compression phase.
LLMLingua 2 Prompt Compression Example
The example below shows compression of about 2x. Such a massive reduction in the prompt size will help reduce costs and latency and thus increase the efficiency of the LLM.

The example has been taken from the research paper.
Another recent development from Microsoft to read about is Orca-Math which can solve big math problems using a small language model.
Conclusion
LLMLingua 2 represents a transformative approach for prompt compression to help cut costs and latency for operating an LLM while retaining essential information. This innovative approach not only facilitates faster and streamlined prompt processing but also enables task-agnostic prompt compression, thereby unleashing the full potential of LLMs across diverse use cases.




