



LLMs can perform far better on a range of tasks when they are exposed to thousands of examples directly in the prompt, using Many-Shot In-Context Learning, says a new study.
Highlights:
- Researchers introduced Many Shot In-Context Learning, which can help boost an LLM’s performance.
- The study shows if LLMs are given thousands of learning examples directly in the prompt, their performance will improve.
- Researchers used Google’s Gemini 1.5 Pro language model to test many-shot ICL.
Inside Study: Many-Shot In-Context Learning
Over the past few years, since the introduction of LLMs into the scene, almost everyone has tried to improve the quality of responses and content generated by these LLMs. Tech enthusiasts and researchers have come up with several techniques such as Prompt Engineering, Domain Specific Fine-Tuning, and Context Injection.
However, these techniques are somewhat complicated and have some limitations. This new study from the researchers shows a promising aspect for LLM responses. All it takes is several examples in the prompts
In the new study by Google Deepmind researchers and other experts, they looked at how LLMs do better when given a large number of examples to choose from in the prompt, as opposed to a small number. This methodology is referred to as Many-Shot In-Context Learning (ICL).
When examples are provided in the context (prompt) immediately, as opposed to fine-tuning the model parameters, this is known as in-context learning (ICL). The latter requires a lot more money and time.
Because they were unable to analyze and output large amounts of text at once, models were typically only given a small number of instances, such as one shot. Larger “context windows”, a type of short-term memory, allow developers to provide the model to hundreds or thousands of examples i.e. many shots, right through the prompt.
“Large language models (LLMs) excel at few-shot in-context learning (ICL) – learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples – the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks.”
Using only input-output examples, or “shots,” which come before a test input delivered within the LLM context, large language models (LLMs) have proven to be remarkably adept at performing in-context learning (ICL).
The number of shots that may be employed for ICL is limited by an LLM’s context window, which is the quantity of tokenized inputs they can handle for each forward inference. As a result, previous research has been limited to the few-shot learning regime.
Different Types of In-Context Learning Explored
The study mainly explores the many-shot technique in two types of In-Context Learning techniques. Let’s explore them in detail:
1) Scaling In-Context Learning
LLMs can learn new tasks from examples that are only presented at the time of inference thanks to a technique called in-context learning (ICL).
The LLM receives a prompt during ICL that includes a series of input-output examples, or shots, that show the intended task. The researchers added a test input after the prompt, enabling the LM to predict the subsequent tokens auto-regressively based only on prompt conditioning.
Recently, LLM context windows have expanded, allowing for the usage of many more shots for ICL than are usually possible. Many-shot learning can leverage larger fractions of available fine-tuning datasets than few-shot ICL. This may lessen the need for task-specific fine-tuning or maybe eliminate it, enabling LLMs to handle a greater variety of jobs without having to specialize.
The largest publicly available model to date, the Gemini 1.5 Pro model with a context length of one million tokens, was employed by the researchers. They evaluated the model using greedy encoding.
To obtain dependable outcomes, they repeatedly used numerous random seeds to randomly choose in-context examples for every 𝐾-shot challenge. They then presented the average performance across seeds and included some visualization for performance on individual seeds.
2) Reinforced and Unsupervised ICL
The researchers employed model-generated justifications for in-context learning when they introduced Reinforced ICL. They started by sampling various rationales for each training problem using a few-shot or zero-shot chain-of-thought prompt to develop model-generated rationales.
They then compiled the justifications into in-context instances with (issue, reason) pairings, choosing those that yielded the proper final response.
They found model-generated rationales to be at least as effective as human-written rationales.
The Unsupervised ICL prompt consists of 1) a preamble, such as, “You will be provided questions similar to the ones below:”, 2) a list of unsolved inputs or problems, and 3) a zero-shot instruction or a few-shot prompt with outputs for the desired output format.
According to one theory, any information added to the prompt that can help focus on the specific knowledge needed for the task at hand becomes useful when the LLM already has the necessary knowledge to solve it. This is how many-shot unsupervised ICL might outperform few-shot learning with human demonstrations.
What did the Results show?
The Gemini 1.5 Pro language model from Google, which can handle up to one million tokens (about 700,000 words) in context, was used by the researchers to test Many-Shot ICL. Ultimately, many-shot prompts performed noticeably better than few-shot prompts on activities like planning, summarising, translating, and answering inquiries.
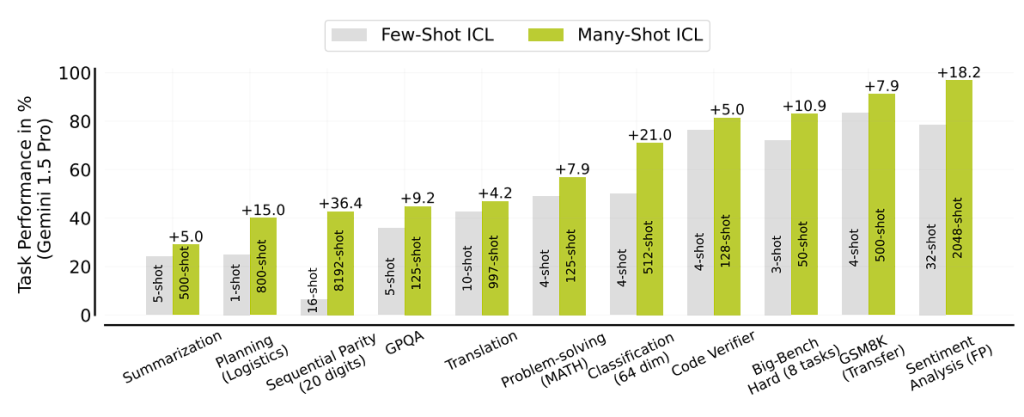
Gemini 1.5 even beat Google Translate in Kurdish and Tamil, the target languages where there is currently the biggest documented discrepancy between LLMs and Google Translate, with over 1000 translation examples.
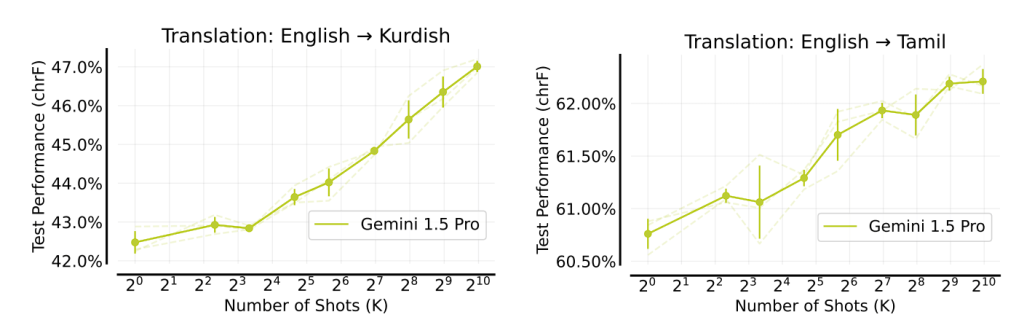
It could nearly match specialized programs when summarising news, but it sometimes experienced hallucinations, including inaccurate facts and timeframes that weren’t present in the learning examples. Furthermore, after more than 50 instances, performance decreased for an unexplained reason.
Either way, the findings demonstrate that language models can accurately learn from a large number of the prompt’s examples. This could eventually eliminate the need for time-consuming training for particular activities.
Self-Generating LLMs
The “Reinforced ICL” method proved to be more dependable than the answers developed by humans. The researchers let the model come up with its answers for challenging logical tasks, like scientific or mathematical puzzles, and then used those answers as further teaching instances.
Only problems without solutions (“Unsupervised ICL”) were provided to the model in one experiment. Still, this was more effective than a few full examples for several logical tasks. The self-generated solutions using “Reinforced ICL” were typically not exactly matched, though.
Additionally, the model “unlearned” pre-training faults through examples, and with sufficient instances, it was even able to identify abstract mathematical patterns.
“We found that, for problem-solving domains where human-generated rationales are expensive to obtain, Reinforced and Unsupervised ICL can obtain strong performance when compared to ICL with human data. We concluded with a set of analysis experiments showing that many-shot learning can overcome pre-training biases, allows learning non-natural language tasks typically difficult for LLMs with few-shot learning, and explored negative log-likelihood trends with respect to context length in the many-shot setting.”
Are there any Limitations?
Although the study results are quite impressive which shows that LLMs are capable of generating their examples and content when they are provided with several examples in the prompts, it comes with quite an eyebrow-raising limitation.
The prompt became more complicated, nevertheless, depending on what order the examples were supplied to the model. The reason why performance occasionally drops with more examples is likewise up for debate. More investigation is required to make this clear.
Whenever new technical research arrives, it is bound to leave certain portions of the developer community in doubt of its complete functionality and potential.
However, we get another possible implication of this limitation, i.e. it also means that prompt writers have extra work to complete, they have to locate or create excellent examples that match the prompt.
Conclusion
The idea of Many Shot In-Context Learning shows significant potential to revolutionize the way LLMs respond to certain prompts and queries. In the future, many-shot ICL can also eliminate the need for time-consuming training for specific tasks. Let’s hope to see this technique evolve in the upcoming days.




