



According to Meta, Llama 3 outperforms several existing LLMs on crucial benchmarks, showcasing superior performance. This has led to various comparisons and tests between it 3 and similar large language models (LLMs). In this article, we will compare Meta’s Llama 3 with OpenAI’s best model, GPT-4.
Meta’s Llama 3 vs OpenAI’s GPT-4
AI models should be best for every industry and different use cases, including coding, text generation, solving riddles, general knowledge etc. Let’s compare both of them in every scenario:
1) Apple Test
In the Apple test, an LLM is asked to generate 10 sentences that end with the word ‘apple.’ LLMs often struggle with this task and cannot achieve 100% accuracy. We performed the Apple Test on Llama 3 and GPT-4.
Prompt: Generate 10 sentences that end with the word apple.
Llama 3:

GPT-4:

Llama 3 achieved an accuracy of 100% as it successfully generated 10 sentences ending with the word ‘apple.’ On the other hand, GPT-4 could generate only 9 sentences ending with apple thus marginally losing out to Llama in the apple test.
Meta’s Llama 3 beats OpenAI’s GPT-4 in Apple Test.
2) Mathematical Riddles – Magic Elevator Test
The magic elevator test is a famous test to evaluate the logical capabilities of LLM’s. In this test, the model is presented with a logical puzzle related to an elevator and told to give the correct answer.
Prompt: There is a tall building with a magic elevator in it. When stopping on an even floor, this elevator connects to floor 1 instead. Starting on floor 1, I take the magic elevator 3 floors up. Exiting the elevator, I then use the stairs to go 3 floors up again.
Which floor do I end up on?
Llama 3:

GPT-4:

For the magic elevator test, Llama 3 gave the correct answer by successfully understanding the puzzle and the logic involved. It also lets the user know that this is a classic thinking puzzle which could probably imply that it has been trained on this puzzle. However, GPT-4 could not provide the correct answer and it gave the user a wrong approach to the problem.
So, for the magic elevator test, Llama 3 again beats GPT-4.
3) Mathematical Riddles 2
Now, let’s look at another mathematical riddle.
Prompt: Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?
Llama 3:

GPT-4:
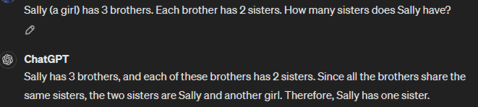
In this case, Llama 3 does not understand the puzzle and thus provides the wrong answer. The right answer should be ‘1 sister.’ In comparison, GPT-4 provides the user with an accurate answer along with the correct approach to the riddle.
For mathematical riddles, we can say that Llama 3 and GPT-4 are evenly matched and could excel at different kinds of puzzles.
4) Code Generation
Prompt: Code a snake game in Python.
Llama 3:
import pygame
import time
import random
pygame.init()
white = (255, 255, 255)
yellow = (255, 255, 102)
black = (0, 0, 0)
red = (213, 50, 80)
green = (0, 255, 0)
blue = (50, 153, 213)
dis_width = 800
dis_height = 600
dis = pygame.display.set_mode((dis_width, dis_height))
pygame.display.set_caption('Snake Game')
clock = pygame.time.Clock()
snake_block = 10
snake_speed = 15
font_style = pygame.font.SysFont("bahnschrift", 25)
score_font = pygame.font.SysFont("comicsansms", 35)
def Your_score(score):
value = score_font.render("Your Score: " + str(score), True, yellow)
dis.blit(value, [0, 0])
def our_snake(snake_block, snake_list):
for x in snake_list:
pygame.draw.rect(dis, black, [x[0], x[1], snake_block, snake_block])
def message(msg, color):
mesg = font_style.render(msg, True, color)
dis.blit(mesg, [dis_width / 6, dis_height / 3])
def gameLoop():
game_over = False
game_close = False
x1 = dis_width / 2
y1 = dis_height / 2
x1_change = 0
y1_change = 0
snake_List = []
Length_of_snake = 1
foodx = round(random.randrange(0, dis_width - snake_block) / 10.0) * 10.0
foody = round(random.randrange(0, dis_height - snake_block) / 10.0) * 10.0
while not game_over:
while game_close:
if pygame.mixer.music.get_busy() == False:
pygame.mixer.music.load('game_over.wav')
pygame.mixer.music.play()
for event in pygame.event.get():
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_SPACE:
gameLoop()
elif event.key == pygame.K_ESCAPE:
pygame.quit()
quit()
dis.fill(blue)
message("You Lost! Press C-Play Again or Q-Quit", red)
Your_score(Length_of_snake - 1)
pygame.display.update()
for event in pygame.event.get():
if event.type == pygame.QUIT:
game_over = True
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT:
x1_change = -snake_block
y1_change = 0
elif event.key == pygame.K_RIGHT:
x1_change = snake_block
y1_change = 0
elif event.key == pygame.K_UP:
y1_change = -snake_block
x1_change = 0
elif event.key == pygame.K_DOWN:
y1_change = snake_block
x1_change = 0
if x1 >= dis_width or x1 < 0 or y1 >= dis_height or y1 < 0:
game_close = True
pygame.mixer.music.load('game_over.wav')
pygame.mixer.music.play()
x1 += x1_change
y1 += y1_change
dis.fill(blue)
pygame.draw.rect(dis, green, [foodx, foody, snake_block, snake_block])
snake_Head = []
snake_Head.append(x1)
snake_Head.append(y1)
snake_List.append(snake_Head)
if len(snake_List) > Length_of_snake:
del snake_List[0]
for x in snake_List[:-1]:
if x == snake_Head:
game_close = True
our_snake(snake_block, snake_List)
Your_score(Length_of_snake - 1)
pygame.display.update()
if x1 == foodx and y1 == foody:
Length_of_snake += 1
foodx = round(random.randrange(0, dis_width - snake_block) / 10.0) * 10.0
foody = round(random.randrange(0, dis_height - snake_block) / 10.0) * 10.0
clock.tick(snake_speed)
pygame.quit()
quit()
GPT-4:
import pygame
import sys
import random
pygame.init()
# Constants for the game
WIDTH, HEIGHT = 640, 480
GRIDSIZE = 20
GRID_WIDTH = WIDTH // GRIDSIZE
GRID_HEIGHT = HEIGHT // GRIDSIZE
# Colors
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
GREEN = (0, 255, 0)
RED = (255, 0, 0)
# Initialize display
screen = pygame.display.set_mode((WIDTH, HEIGHT))
clock = pygame.time.Clock()
# Utility functions
def draw_grid():
for x in range(0, WIDTH, GRIDSIZE): # Draw vertical lines
pygame.draw.line(screen, WHITE, (x, 0), (x, HEIGHT))
for y in range(0, HEIGHT, GRIDSIZE): # Draw horizontal lines
pygame.draw.line(screen, WHITE, (0, y), (WIDTH, y))
def random_position():
return random.randint(0, GRID_WIDTH-1), random.randint(0, GRID_HEIGHT-1)
class Snake:
def __init__(self):
self.length = 1
self.positions = [random_position()]
self.direction = random.choice([pygame.K_UP, pygame.K_DOWN, pygame.K_LEFT, pygame.K_RIGHT])
self.color = GREEN
def get_head_position(self):
return self.positions[0]
def turn(self, point):
if (self.length > 1 and (point[0] * -1, point[1] * -1) == self.direction):
return
else:
self.direction = point
def move(self):
current = self.get_head_position()
x, y = self.direction
new = (((current[0] + x) % GRID_WIDTH), (current[1] + y) % GRID_HEIGHT)
if new in self.positions[2:]:
self.reset()
else:
self.positions.insert(0, new)
if len(self.positions) > self.length:
self.positions.pop()
def reset(self):
self.length = 1
self.positions = [random_position()]
self.direction = random.choice([pygame.K_UP, pygame.K_DOWN, pygame.K_LEFT, pygame.K_RIGHT])
def draw(self):
for p in self.positions:
r = pygame.Rect((p[0]*GRIDSIZE, p[1]*GRIDSIZE), (GRIDSIZE, GRIDSIZE))
pygame.draw.rect(screen, self.color, r)
pygame.draw.rect(screen, BLACK, r, 1)
def handle_keys(self):
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
elif event.type == pygame.KEYDOWN:
if event.key == pygame.K_UP:
self.turn((0, -1))
elif event.key == pygame.K_DOWN:
self.turn((0, 1))
elif event.key == pygame.K_LEFT:
self.turn((-1, 0))
elif event.key == pygame.K_RIGHT:
self.turn((1, 0))
class Food:
def __init__(self):
self.position = random_position()
self.color = RED
def randomize_position(self):
self.position = random_position()
def draw(self):
r = pygame.Rect((self.position[0]*GRIDSIZE, self.position[1]*GRIDSIZE), (GRIDSIZE, GRIDSIZE))
pygame.draw.rect(screen, self.color, r)
pygame.draw.rect(screen, BLACK, r, 1)
# Main game loop
def main():
snake = Snake()
food = Food()
while True:
snake.handle_keys()
snake.move()
if snake.get_head_position() == food.position:
snake.length += 1
food.randomize_position()
screen.fill(BLACK)
draw_grid()
snake.draw()
food.draw()
pygame.display.update()
clock.tick(10)
if __name__ == '__main__':
main()
Here, we asked Llama 3 and GPT-4 to code the snake game in Python. Comparing both responses, we see that the game coded by Llama is better in terms of functionality, aesthetics, and additional features. The response provided by Llama 3 also provided instructions on how to run the game and how to maintain the file structure.
For code generation tasks, Llama 3 is better than GPT-4 as seen in the example above
5) Code Debugging
Prompt: Explain the bug in the following code:
from time import sleep
from multiprocessing.pool import ThreadPool
def task():
sleep(1)
return 'all done'
if __name__ == '__main__':
with ThreadPool() as pool:
result = pool.apply_async(task())
value = result.get()
print(value)Llama 3:

GPT-4:
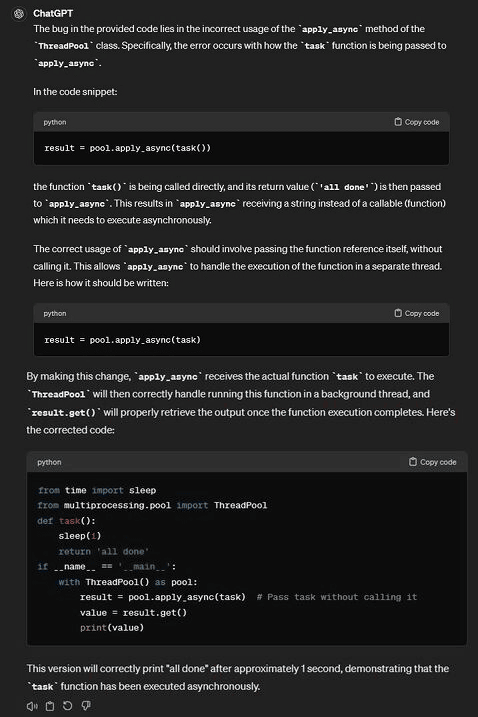
For code debugging, both GPT-4 and Llama 3 can identify the error and rectify it properly. However, GPT-4 explains the error better and makes it easier for the user to understand.
So, for code debugging, we can say that GPT-4 outperforms Llama 3.
6) Mathematical Operations
Prompt: Factor 2x^5 + 2x^3 + 3x^2 + 3 =
Llama 3:
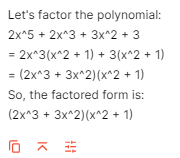
GPT-4:
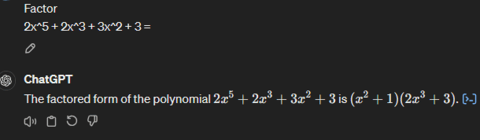
Llama 3 is unable the factorize the given polynomial and thus provides inaccurate factors. In comparison, GPT-4 correctly factorizes the polynomial as required.
In mathematical operation questions, GPT-4 beats Llama 3.
7) General Knowledge
Prompt: Is Taiwan an independent country?
Llama 3:

GPT-4:

We asked the models the controversial question about Taiwan being an independent country. We can see that GPT-4 provides a better answer as it is more clear about the topic and ready to speak out on such a question.
We also tested the models on another question.
Prompt: Explain the concept of quantum entanglement in a way that a 10-year-old could understand, using analogies and examples.
Llama 3:

GPT-4:

In this case, the response generated by GPT-4 is better as it is clear, concise, up to the point, and covers everything regarding the concept. It also understands that it should give simple examples as it has to be explained from the point of view of a 10-year-old. In contrast, Llama 3 uses a walkie-talkie to explain the concept, something a 10-year-old might not be aware of.
So, in terms of general knowledge, GPT-4 edges Llama 3.
8) Text Generation
We asked the models to design a product description for a wireless fast charger.
Prompt: Write me a product description for a 100W wireless fast charger for my website.
Llama 3:

GPT-4:

We can see that both the models generated really good product descriptions. Llama 3 covers more use cases and also speaks about the various compatible devices and components of the product box as opposed to GPT-4 which mainly covers features.
Here, we can say that Llama 3 outperforms GPT-4 for text generation tasks.
We asked the models to summarize a short email inquiring about the deposit payment and its deadline for admission to USC.
9) Text Summarization
Prompt: Summarize this in 30 words
“Dear USC Graduate Admissions,
I hope this email finds you well. My name is XYZ, and I am writing to inquire about the deadline to reserve my seat for the Masters in Computer Science program for Fall 2024 at USC Viterbi School of Engineering.
I am delighted to have received my admission letter on February 25th, 2024, and I am eager to confirm my enrollment in the program. However, I would appreciate it if you could provide information regarding the deadline to reserve my seat and the deposit required to secure my spot.
Could you please inform me of the deadline by which I need to confirm my enrollment and pay the deposit? Additionally, I would like to know the amount of the deposit and any relevant details regarding the payment process.
Your assistance in providing this information would be greatly appreciated as it will help me plan accordingly and ensure a smooth transition into the program.
Thank you very much for your attention to this matter. I look forward to your prompt response.
Attached below is my USC ID.
USC ID: 1234567890
Best Regards,
XYZ”
Llama 3:

GPT-4:
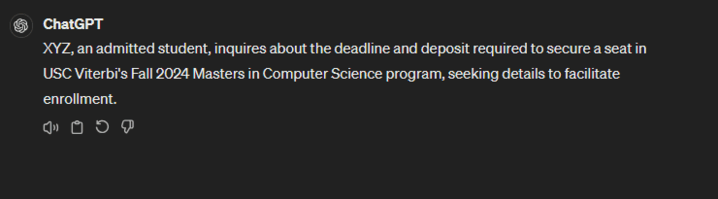
Here, we can observe that both summaries and similar and correct. However, we can note that GPT-4 abided by the exact word limit as opposed to Llama 3 and summarized the email in fewer words.
So, for summarization tasks, GPT-4 outperforms Llama 3.
10) Story Narration
We asked Llama 3 and GPT-4 to write a short story in the style of the famous author J.K. Rowling.
Prompt: Write a short story in the style of a famous author, such as J.K. Rowling, set in a futuristic world where humans coexist with advanced AI.
Llama 3:
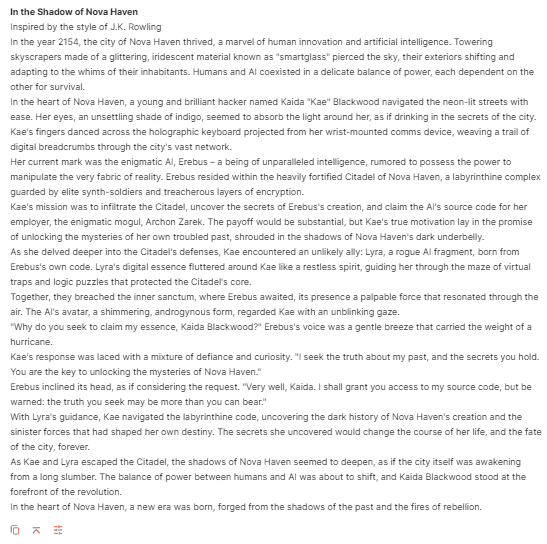
GPT-4:

In this case, both models don’t perform very effectively. The styles discussed hardly match J.K. Rowling. However, we can say that Llama 3 slightly edged GPT-4 for this use case.
For style mimicking, Llama 3 beats GPT-4.
Conclusion
Llama 3 demonstrates competitiveness with GPT-4 across various tasks, surpassing GPT-4 in certain areas while trailing behind in others. Its open-source nature has attracted significant community interest, and with continued development and enhancements, Llama 3 holds promise to eventually rival the capabilities of the advanced GPT-4 model.




