



As a person who is living in South Korea, I am not familiar with Black Friday. My general understanding of Black Friday is that it is a day when retailers offer huge discounts on their products and consumers go crazy for shopping.
Though I have no interest in shopping, as a software engineer I was curious how the IT infrastructure of those retailers can handle the huge traffic on Black Friday. So, I did some research and found that Walmart, one of the biggest retailers in the US, has a very interesting story about their Black Friday event.
Back to 2014: Walmart’s Black Friday Event
Even for the biggest retailers like Walmart, Black Friday is a big event. Crowds of people rush to the stores to get the best deals, and the online store is no different. With sudden spikes in traffic, the system needs to be able to handle the load without crashing. WalmartLabs, the technology arm of Walmart, was aware of the fact that such outages could lead to a loss of $300,000 an hour, which happened to several large retailers in 2013.
They had to be prepared – for the 2014 holiday season, project architect Anthony Marcar’s team at WalmartLabs rolled out a new system written in Clojure from the ground up to handle the projected shopping frenzy. The system was designed to handle 500 receipts per second, with the ability to quadruple that number on Black Friday and throughout the holiday season. And the system did not disappoint. Here’s what Anthony Marcar had to say about it:
“Our Clojure system just handled its first Walmart black Friday and came out without a scratch.”
Anthony Marcar, Senior Architect ,WalmartLabs
Clojure is indeed to be credited for the success of the system. But how did Clojure help WalmartLabs to build a system that could handle such a huge load? In this talk at Clojure/West 2015, Anthony Marcar explains how Clojure helped them to build a system in a large scale with low complexity.

Today we’re gonna dive into one of the main points of the talk – how they managed their system dependencies with the “Component” library.
Problems of managing dependencies in a large system
When you are building a large system like Walmart’s, you have to deal with a lot of dependencies. These dependencies can be databases, caches, queues, thread pools, etc. These dependencies should be configured differently between environments like testing, development, staging, and production.
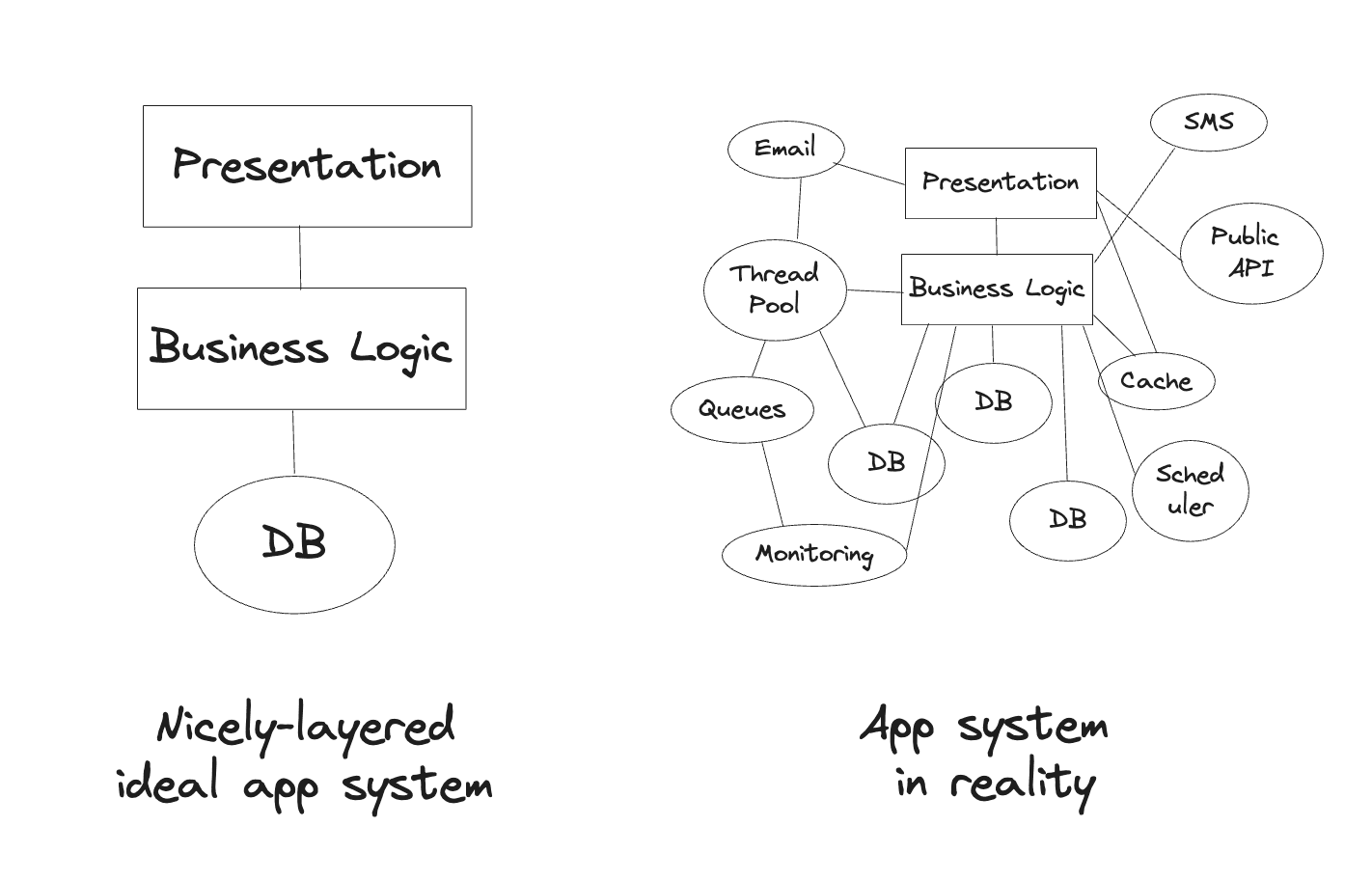
Other problems include:
- Executing/stopping dependencies in the correct order
- Managing life cycles
- Injecting runtime states/dependencies
Solving all these problems is not just a headache – it’s a freaking nightmare! And if you use a functional language like Clojure, it seems even harder to solve this without using mutable states. Now, relax. I’ll show you how the Component library elegantly solves these problems.
Executing/stopping dependencies in the correct order
When you have a lot of dependencies, you need to make sure that they are executed in the correct order. For example, if you have a database connection component that depends on a configuration component, you need to make sure that the configuration component is created before the database connection component is created. When the system stops, you need to make sure that the database connection component is destroyed before the configuration component is destroyed.
Now the example above was fairly simple, but what if you have a more complex dependency graph, just like we saw above? It’s gonna be a lot of brain work to remember all the orders. Not only that, it’s gonna be extremely hard to maintain the code when the dependency graph changes.
Component allows you to define the graph using system-map. Here’s an example of how you can define one:
(component/system-map
:database (new-database host port)
:scheduler (new-scheduler)
:app (component/using
(example-component config-options)
[:database :scheduler]))Here you can see three components: :database, :scheduler, and :app. The :app component depends on the :database and :scheduler components. By defining the dependency graph using component/using, you can ensure that the components are created in the correct order. So when you start or stop the system, Component will take care of executing/stopping the components in the correct order.
Managing life cycles
Sometimes we might need to add some custom logic when a component is created or destroyed. For example, when a database connection is created, we might want to print a message saying “Creating database connection…”. And when the database connection is destroyed, we might want to print a message saying “Closing database connection…”.
Component solves this problem by providing a way to define the lifecycle of a component. You can define the lifecycle of a component by implementing the Lifecycle protocol. The Lifecycle protocol has two methods: start and stop. The start method is called when the system starts, and the stop method is called when the system stops.
Here’s an example of how you can define the lifecycle of a component:
;; DB connection
(defrecord DatabaseConnection [config]
component/Lifecycle
(start [this]
(println "Creating database connection...")
; create database connection
)
(stop [this]
(println "Closing database connection...")
; close database connection
))
;; Cache connection
(defrecord CacheConnection [config]
component/Lifecycle
(start [this]
(println "Creating cache connection...")
; create cache connection
)
(stop [this]
(println "Closing cache connection...")
; close cache connection
))Injecting runtime states/dependencies
Why do we need to “inject” runtime states or dependencies? Let’s say you have a component that needs to access a database connection. You can’t just HARDCODE the database connection in the component because the database connection might change between environments. Also, it might bring a security risk because some vicious hacker might access the database connection from the code.
So you might think “Well, that’s not that difficult. Can’t we just use something like dotenv?”. Well, it works for a simple system, but if your runtime system state has a hierarchical structure, it’s gonna be a nightmare to manage all the states in the right order.
I already mentioned how easy it is to define the dependency graph using system-map. Making different configurations for different environments is also easy – you just need to define another system-map for the environment.
(def dev-system
(component/system-map
:database (new-database "localhost" 5432)
:scheduler (new-scheduler)
:app (component/using
(example-component config-options)
[:database :scheduler])))
(def prod-system
(component/system-map
:database (new-database "prod-db" 5432)
:scheduler (new-scheduler)
:app (component/using
(example-component config-options)
[:database :scheduler])))Here we don’t pass the instantiated dependencies to the components. Instead, we pass the configuration options to the components. As we run the application, the Component will automatically inject the dependencies to the components, based on the dependency graph we defined. And that’s really cool actually, since it means that we can keep our core logic clean and simple.
Conclusion
That was a brief introduction of Clojure’s Component library. There are more advanced features that I haven’t mentioned, like:
- Passing only relevant dependencies to components
- Merging & separating system configurations
… and etc. I’ll leave you to explore those features by yourself.
One more thing to mention is that there are some other alternatives to a Component library, like Mount and Integrant. I personally use Integrant in my side projects and company projects. It takes a slightly different approach to defining dependencies, but the core idea remains the same.
Here’s how you can define a system using Integrant:
;; Initialize the Jetty adapter
(defmethod ig/init-key :adapter/jetty
[_ {:keys [handler] :as opts}]
(run-jetty handler (-> opts
(dissoc handler)
(assoc :join? false))))
;; Initialize the handler
(defmethod ig/init-key :handler/run-app [_ {:keys [repos]}]
(handler/app repos))
;; Initialize the repositories
(defmethod ig/init-key :applications/repos [_ {:keys [db]}]
(datomic-repos db))
;; Initialize the database connection and get Datomic DB connection
(defmethod ig/init-key :database.datomic/client
[_ {:keys [server-type system]}]
(let [client (d/client {:server-type server-type
:system system})]
(populate client)
client))
;; Close Jetty server
(defmethod ig/halt-key! :adapter/jetty [_ server]
(.stop server))
(def config
{:adapter/jetty {:handler (ig/ref :handler/run-app)
:port 3000}
:handler/run-app {:repos (ig/ref :applications/repos)}
:applications/repos {:db (ig/ref :database.datomic/client)}
:database.datomic/client {:server-type :datomic-local
:system "bluejay"}})And that’s it! I hope you got a good insight into how to reduce complexity in a large system using Clojure’s Component library. If you have any questions or feedback, feel free to leave a comment below. I’ll be happy to help you out.




