



Every great idea starts small, and so does every great software project. I’ve built many web projects from scratch, and most of them started with a simple stack – a web server (commonly separated into frontend and backend) and a database. It’s mostly enough for the beginning – maybe even for a long time if the project isn’t needed to scale.
But today we’re going to talk about the moment when the project grows, I mean like it grows to serve millions and billions of users. At some point, using only a database for serving requests can slow down the whole system. We’ll learn how big companies like Facebook adopt cache to scale to serve billions of requests by cleverly assisting the database.
What is cache? And why do we need it?
The definition of cache is simple: it’s a component that stores data so that future requests for that data can be served faster. Sorry, I think it was too simple. We’ll have to dive deeper into at least these two points to properly understand the cache:

It “expects” the future requests
The real power of cache comes from the fact that it expects future requests and stores the data in advance that it thinks will be requested. A good example of this is how feed updates work on social media platforms.
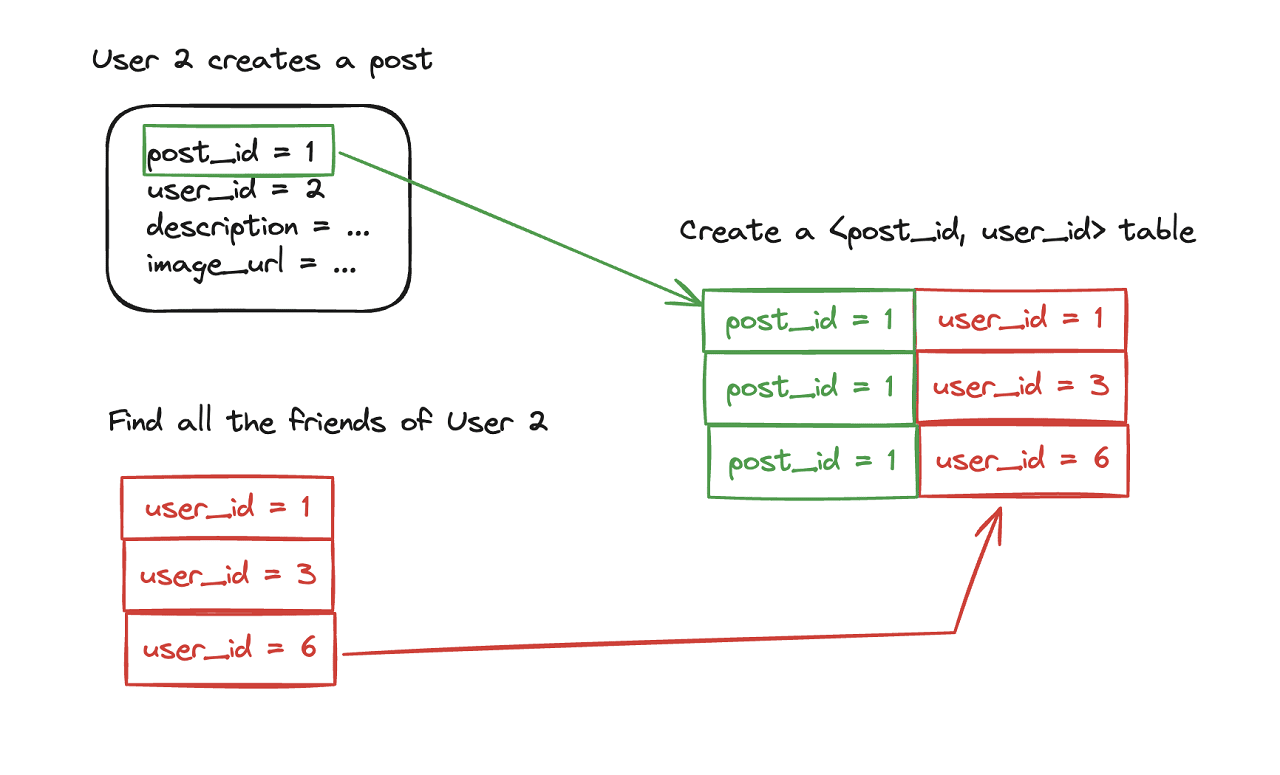
When one of your friends posts (or shares) a new post, it is “expected” that you will see this new post in your feed. Not only you but also other friends of your friends will see this post in their feeds. So the platform can store a pair in the news feed table in a cache storage so that it can easily retrieve the posts that should be shown in the feed of a user.
Data can be served “faster”
You might be wondering, “Well, can’t we just query the database to get the posts that should be shown in the feed of a user?”. Of course, we can – but it won’t be fast enough. The database is more like a warehouse, where the data is stored in a structured way. It’s optimized for storing and retrieving data, but not for serving data fast.
The cache is more like a shelf, where the data is stored in a way that it can be retrieved quickly.
Not only the cache storage is optimized for serving data fast, but also it can be “placed” closer to the user. For example, the cache storage can be placed in the same server where the web server is running, or even in the same server where the user is connecting to. This can reduce the latency of the data retrieval, and make the data serving even faster.
It’s very common to have a cluster of cache storages, while the database is usually a single server within a region.
So, we don’t need a database anymore?
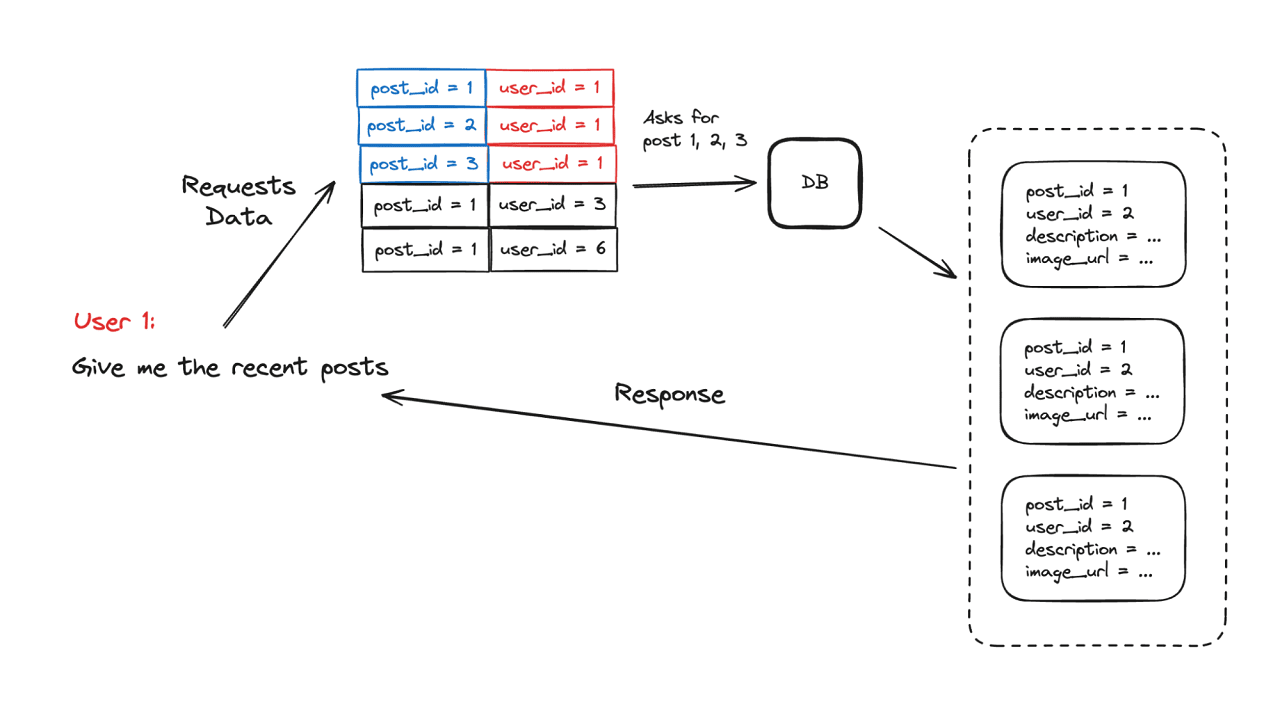
No, we still need a database – it’s our single source of truth. The cache is just a helper that makes the data serving faster. From the example above, we stored only the pair in the cache storage. We’ve reduced the total time by skipping the “user->friend->recent posts” query, but we still need to query the database to get the actual post data. Remember, the shelf is of no use without the warehouse.
Now we know what cache is, and why we need it. Let’s see how big companies like Facebook use cache to scale to serve billions of requests.
Memcache: Facebook’s caching system
To understand what Memcache is, let me briefly introduce “Memcached” (it has an extra “d” at the end). So to be extremely brief, Memcached is a high-performance caching system. That’s all you need to know about it. It does what a cache storage should do, and it does it well.
However, Facebook wanted to have a cache storage that is more flexible and scalable in distributed systems. So they built a distributed caching framework called “Memcache”, that runs Memcached instances in a distributed way.
To summarize(with metaphors), Memcached is a player and Memcache is a coach.

Now let’s look at the features of Memcache that enable Facebook to scale to serve billions of requests.
1) Parallel requests with DAG
Even for the cache storage, retrieving data can be slow if it responds to every request sequentially. If logically independent, the data can be retrieved in parallel. The question is, how can we know which data is logically dependent or independent?
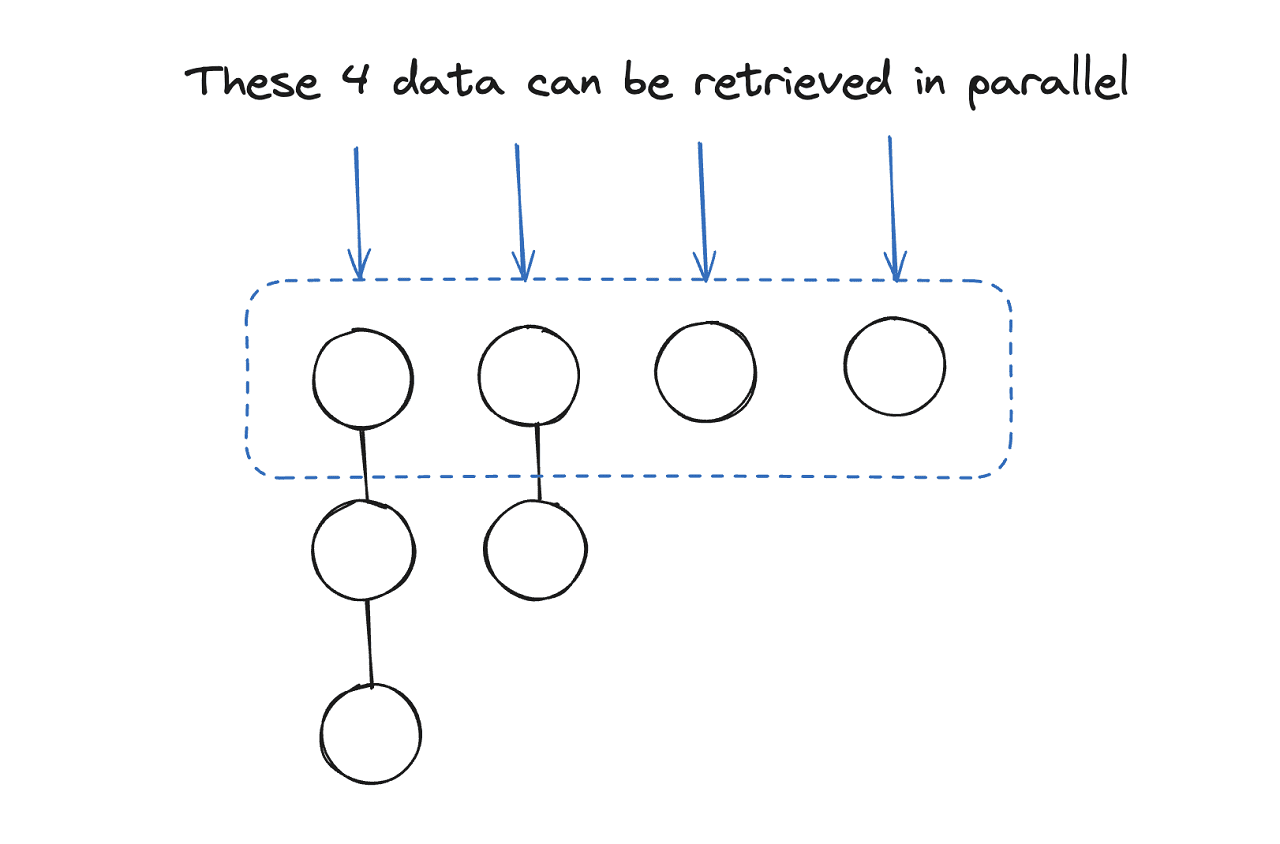
To solve this, Facebook constructs a DAG (Directed Acyclic Graph) of the dependencies between the data. By looking at this graph, the Memcache can know which data can be retrieved in parallel, and which data should be retrieved sequentially. This reduces the latency of the data retrieval and makes the data serving faster.
2) Batching the requests
The cache storage can be slow if it responds to every request individually. Think about buying groceries – it’s faster to buy all the groceries at once than to buy them day by day. The same goes for the cache storage.
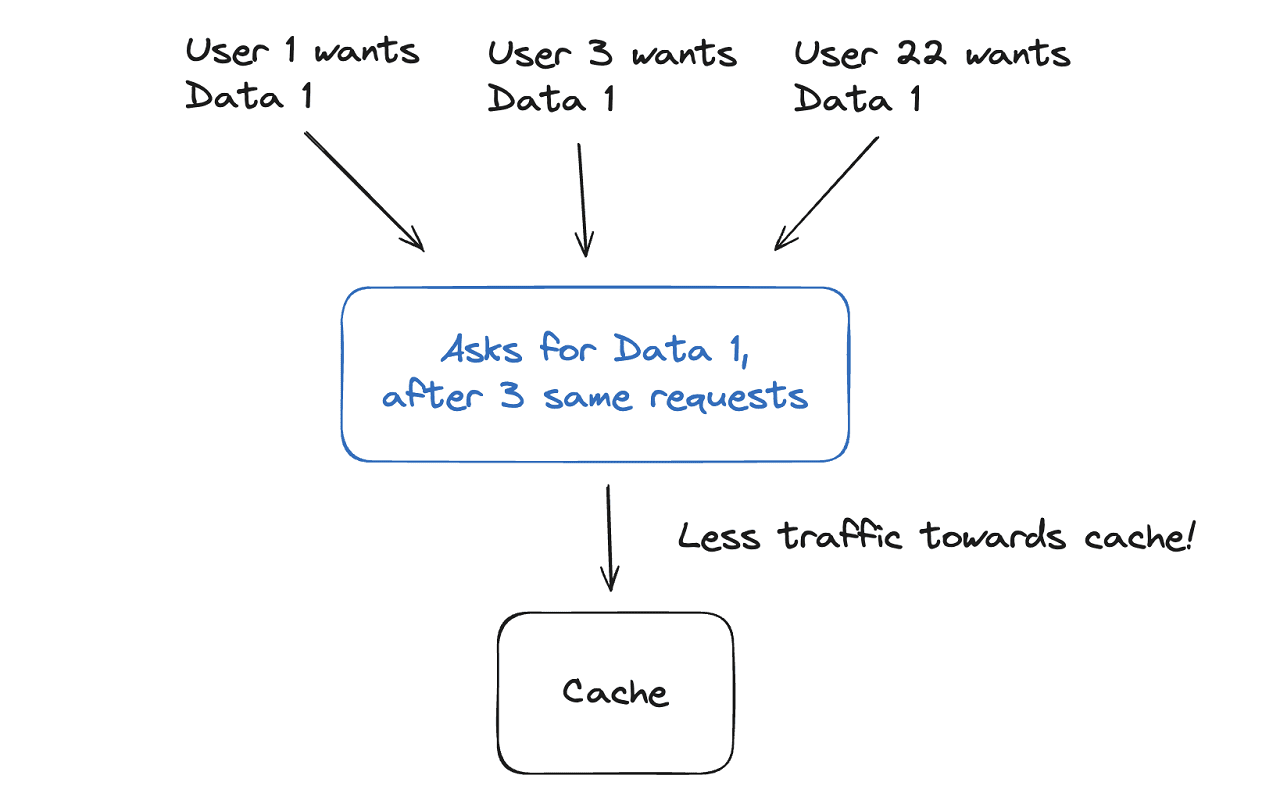
Memcache batches the requests to the cache storage. It collects the requests that can be served together and sends them to the cache storage at once. This technique is called “batching”, and it’s one of the most commonly used techniques to reduce the latency in data-intensive applications.
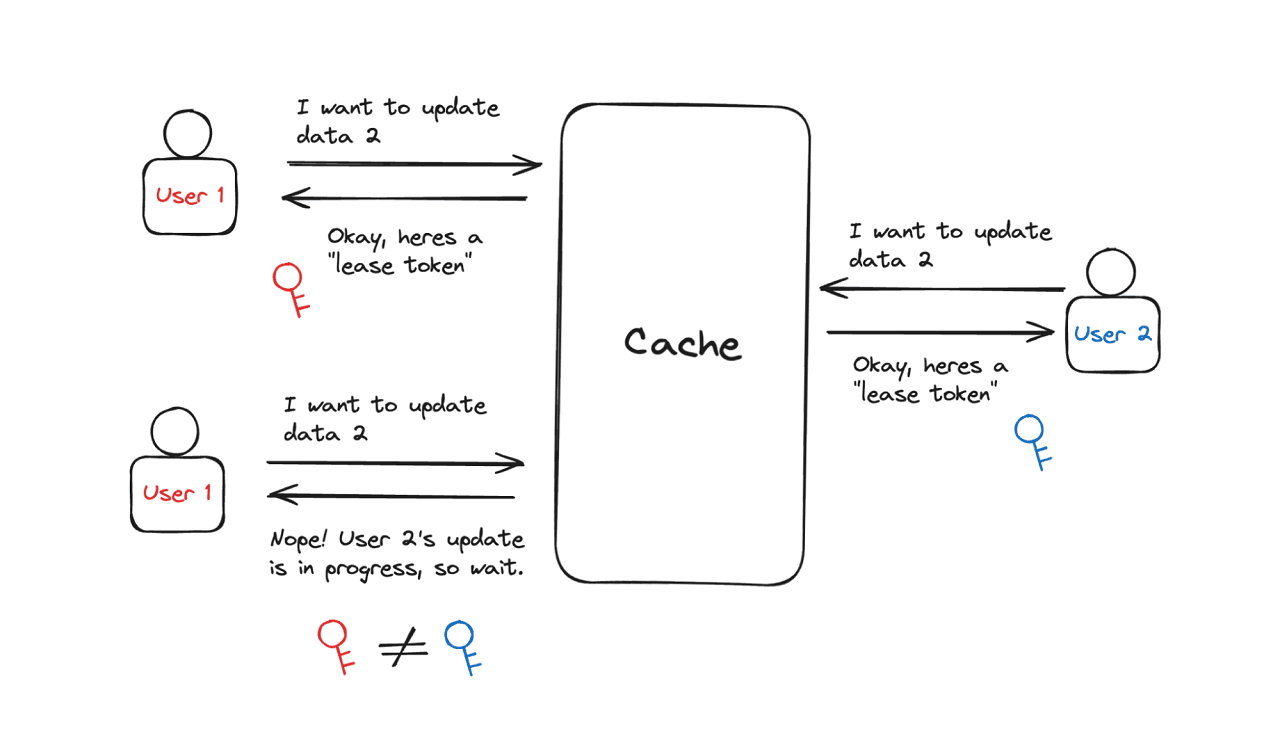
3) Leasing
The last feature that I’d like to introduce is “leasing”. It solves two specific problems:
- Stale sets: It happens when the new data being written is already invalidated by the time it’s written.
- Thundering herds: It happens when there’s a big amount of cache misses, consequently leading to a big amount of read requests in the database before data is written to the cache.
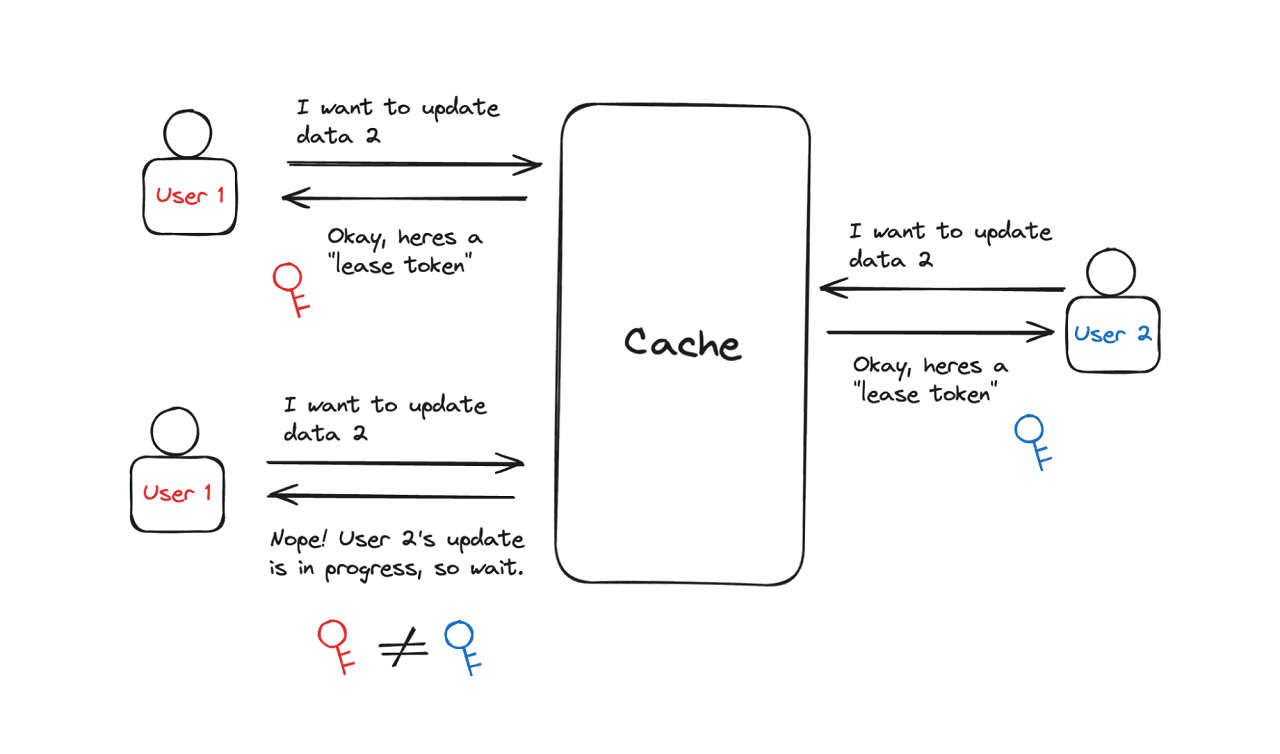
Leasing solves these problems by giving a “lease” to the client to set the data. The client is authorized to set the data by verifying the write requests with the provided 64-bit token key. The client will be rejected if the token key has been invalidated when the client tries to set the data.
This way, the stale sets and thundering herds can be prevented since the system can focus on the most recent data. What a neat trick!
Conclusion
Today we learned about what “cache” is, and how Facebook utilizes their caching system “Memcache” to handle billions of requests. The key features were:
- Parallel requests with DAG, to make full use of concurrency
- Batching the requests, to reduce the number of requests
- Leasing, to prevent stale sets and thundering herds
One simple advice – cache seems like a nice, shiny tool that can solve many problems from your projects. But remember, it should be only used when there’s an actual problem that needs to be solved with cache. Adopting new cache storage is also adding a new layer of complexity to the project. And due to its nature of being volatile, it might lead to inconsistency in the data if carelessly used.
Also, you should find out if your system already includes a caching system. For example, if you’re building a web application with Elixir Phoenix, you can use ETS (Erlang Term Storage) as a key-value cache storage. It’s built-in, and it’s fast (believe me, Discord has been using ETS for years).
So, choose the right cache storage for your project, or else you’re just adding needless complexity to the project.
You can now read also about another Meta’s business on how WhatsApp handles Millions of Concurrent Users.
That’s all for today. I hope you enjoyed reading this article, and let me know if you have any questions or feedback. Thank you for reading!




