



Groq AI has recently become the world’s fastest AI model, leaving several AI giants in the dust, one of them being ChatGPT. With its unmatched speed of almost 500T/s and incredibly low latency, it has taken the internet by storm.
This is a huge breakthrough in the field of AI as Groq offers the fastest inference for computationally intensive applications compared to any other AI model observed before.
Let’s take a look at its different model approach compared to ChatGPT, which helps it to achieve such a highly fast and efficient computational power.
Groq’s LPU Approach
Groq AI does not use the traditional GPU model used by all traditional generative AI software until now. Instead, they developed their hardware known as Linear Processing Unit (LPU).
Unlike the traditional GPU integrated with the LLM approach, LPUs are architected to deliver high-end performance computing for generating AI content. These LPUs are made of hundreds of parallel processors for streamlined processing. This allows them to be more suited to work with LLMs, the model traditionally used by AI models such as ChatGPT.
Groq achieves its remarkable performance benchmarks thanks to its foundational LLM, Llama 2 70B which is created by Meta. It runs on the Groq LPUs inference engine. It also achieves its ultra-low latency performance with its Mixtral 8x7B-32k and Mixtral 7B-8k models.
This is huge news for the developer community, as they can expect optimized and accurately generated content in lightning-fast amounts of time. LPUs also improve model flexibility and robustness by simplifying the hardware demand of large-scale AI models. This removes the need for developers to redesign their applications in real-time.
The Edge Over ChatGPT
Clearly, with its remarkable innovation, Groq AI leads the race in being the fastest large language model. It completely outshines all traditional AI models in terms of response time and analyzing data.
Take a look at the bottom two videos, in which we asked both Groq AI and ChatGPT a similar question.
ChatGPT:
Groq AI:
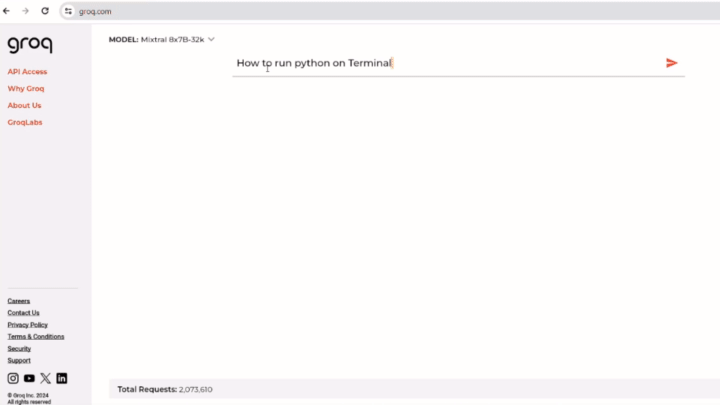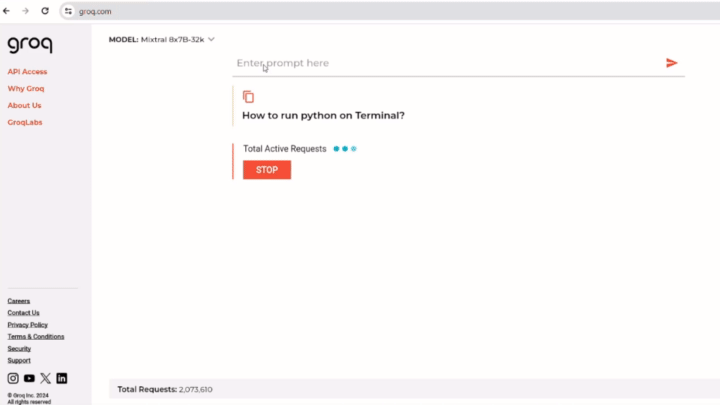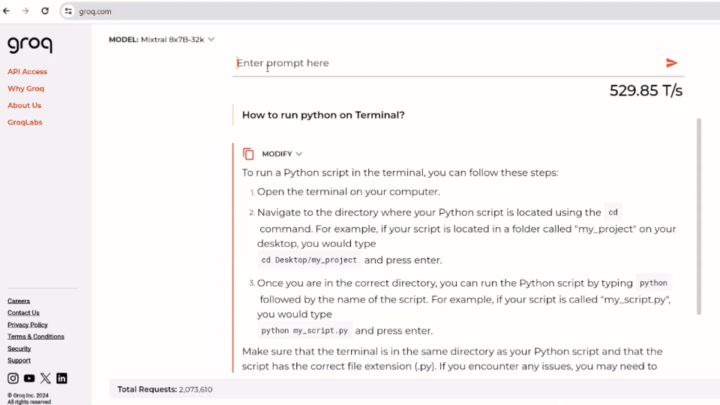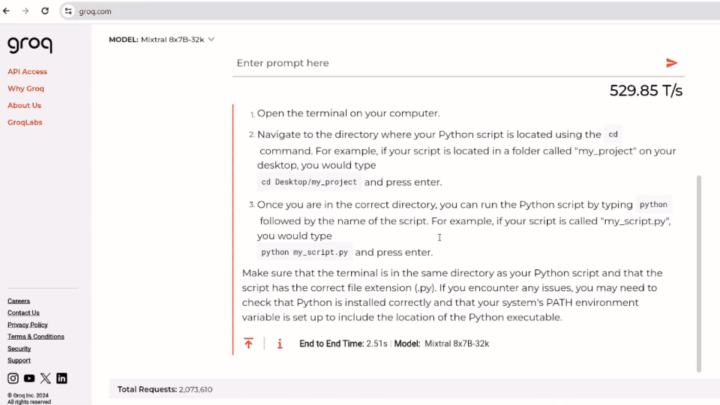
You can see the lightning-fast response generated by GroqAI, which gives the full description of the solution in one go. Whereas ChatGPT takes its time in elaborating each step line by line, making users wait for variable amounts of time. The response time of Groq AI in the video remains impressive nearing almost 530T/s.
The high-speed generation of large content can be attributed to the LPUs which are designed to deal with sequences of Data. This provides us with a large content at one go in unbelievable amounts of time. The company is even working on increasing the response time ten times faster than traditional AI models by trying out different APIs with its engine and running LLMs.
Groq AI also paves the way for a better future of AI models by highly reducing efficiency and maintenance costs. It completely removes the high expenses associated with high-end GPU hardware such as NVIDIA’s A100 and H100 Tensor Core and provides a cheaper, smoother, and faster alternative.
Groq is serving the fastest responses I've ever seen. We're talking almost 500 T/s!
— Jay Scambler (@JayScambler) February 19, 2024
I did some research on how they're able to do it. Turns out they developed their own hardware that utilize LPUs instead of GPUs. Here's the skinny:
Groq created a novel processing unit known as… pic.twitter.com/mgGK2YGeFp
This will also allow future AI firms to be financially independent and invest their capital in completely research-related areas beneficial to the development of Generative AI. Reportedly OpenAI has been struggling to develop its model chip and has been seeking trillions of dollars from the Government.
Conclusion
Groq AI definitely might now be called the world’s fastest AI model. However, we must not completely disregard the other traditional AI models as they are each unique in their ways of contributing to the field of Generative AI. Groq has made an innovation that is of high significance and at the end of the day it motivates everyone, and lays down the foundation for improved AI efficiency.




