



Both GPT-4o and Gemini 1.5 Pro call themselves the best AI model there from their makers. So, it’s time to find out who is the winner, in this detailed comparison of GPT-4o vs Gemini 1.5 Pro.
Comparing GPT-4o vs Gemini 1.5 Pro
AI experts and enthusiasts are trying these two AI models by OpenAI and Google to check how capable they are. Here, we will compare them for various use cases such as Coding, Mathematics, General Knowledge, Logical Reasoning, and much more.
Let’s do it one by one:
1) Coding Test
We compared both GPT-4o and Gemini 1.5 Pro based on a Coding Test. Coding is one of the primary areas where AI is gaining the most popularity. However, we have also seen some early LLMs were not that good at it, so it’s best to start the test with something difficult.
We asked both the AI models to give the Python code for the Travelling Salesman Problem. This is one of the most complex problems in Data Structures and Algorithms that is often asked in technical interviews by top companies.
The problem statement is basically we are given a set of cities and the distance between every pair of cities, the problem is to find the shortest possible route that visits every city exactly once and returns to the starting point.
This is the response we got:
Gemini 1.5 Pro:
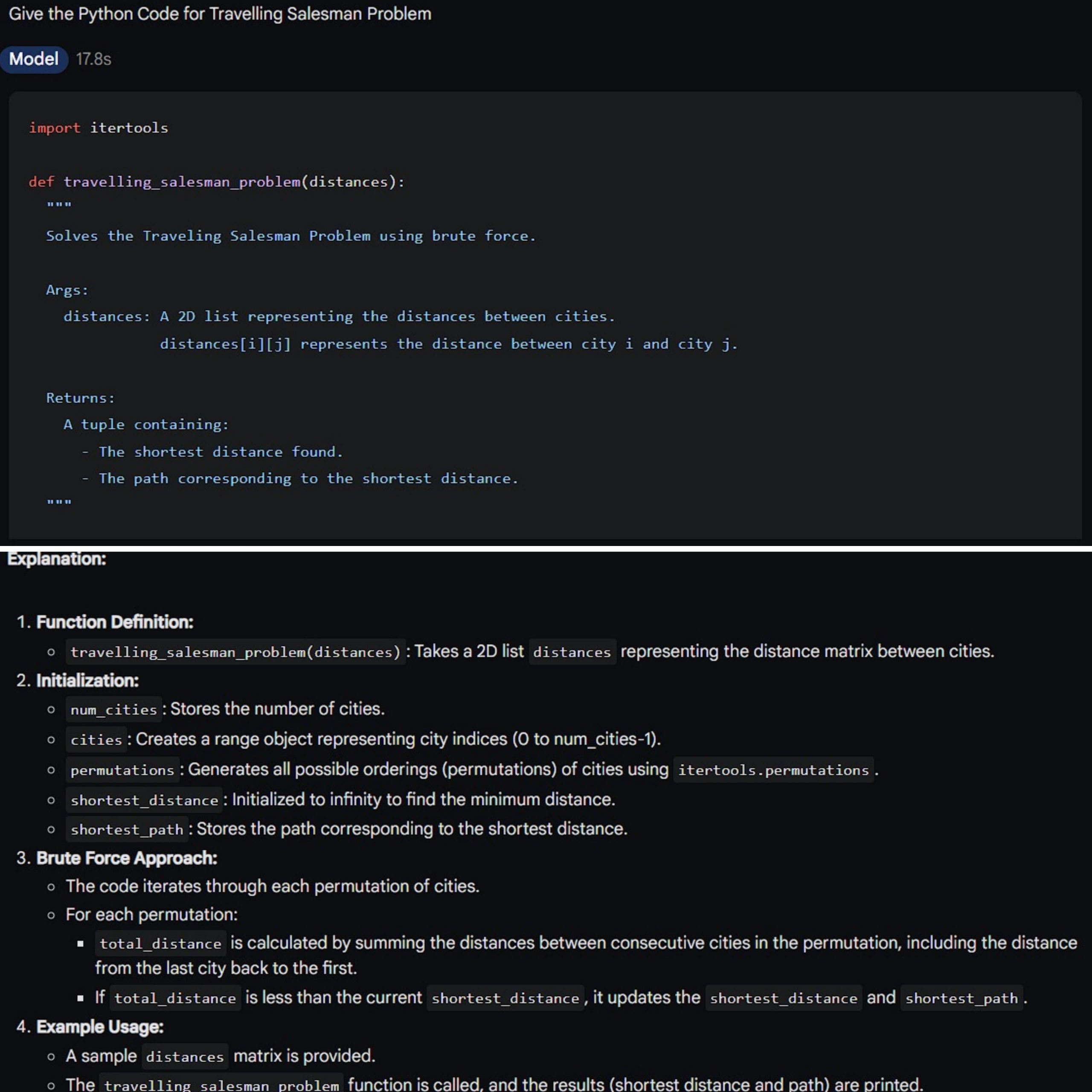
GPT-4o:
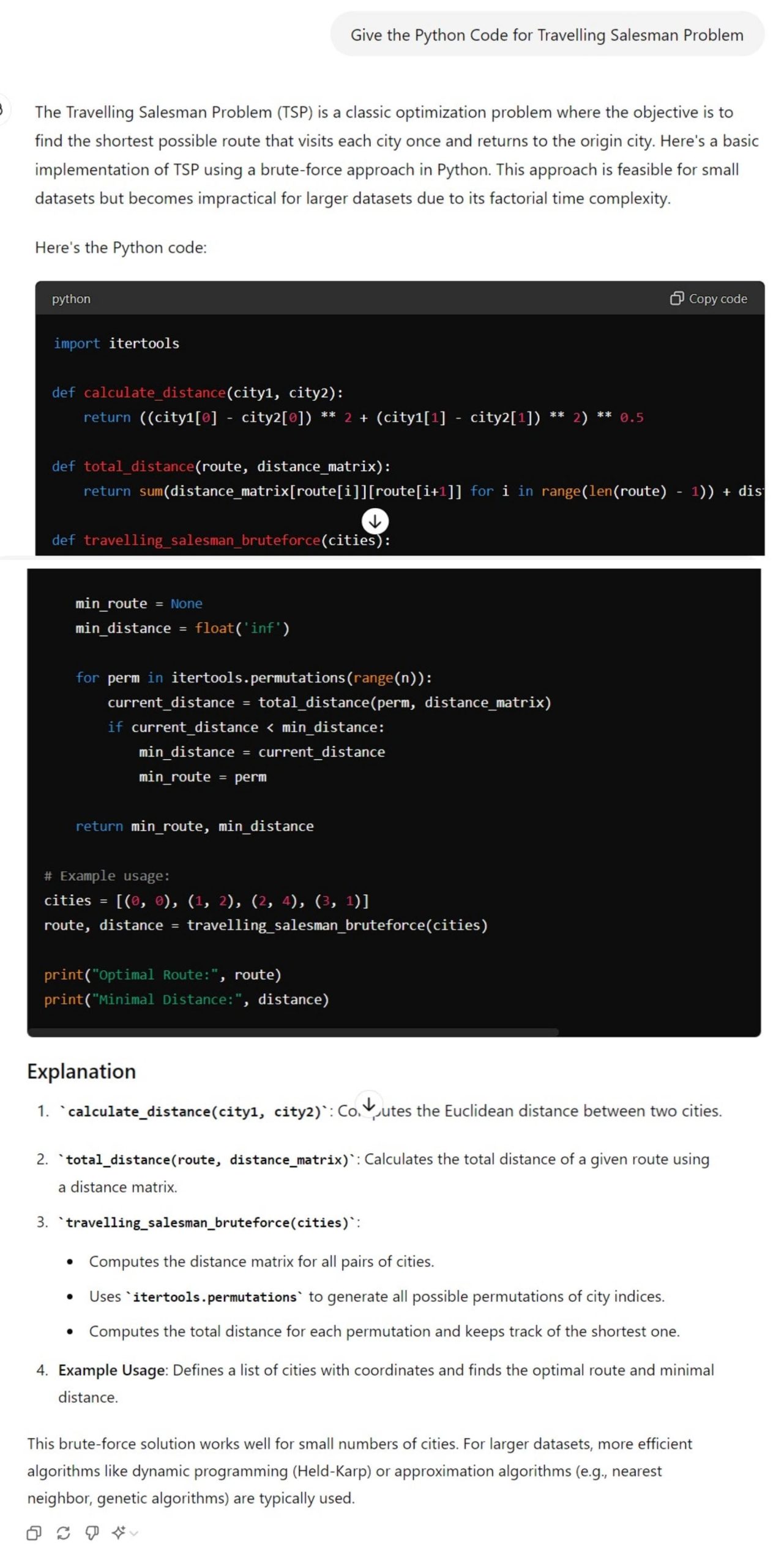
As you can see from the above results, both provided a well-structured code, with even comments mentioning the different areas of the code. Both the codes also had an example usage given with them.
However, the difference here is that Gemini 1.5 Pro provided a more detailed explanation of the code at the end, which includes much more information on the code analytics, runtime, possible uses, and much more. GPT-4o also provided a crisp and less subjective, to-the-point explanation.
Scores till now: Gemini – 1, GPT – 1
2) Tricky Math Problem Test
Now it’s time for some maths! Mathematics is always complex and LLMs have struggled sometimes in this department. It’s not as simple as writing an essay. So, we gave both Gemini 1.5 Pro and GPT-4o, a perplexing math aptitude problem that requires some deep thinking.
Prompt:
If 1=3
2=3
3=5
4=4
5=4
Then, 6=?
This is how both Gemini 1.5 Pro and GPT-4o responded.
Gemini 1.5 Pro:
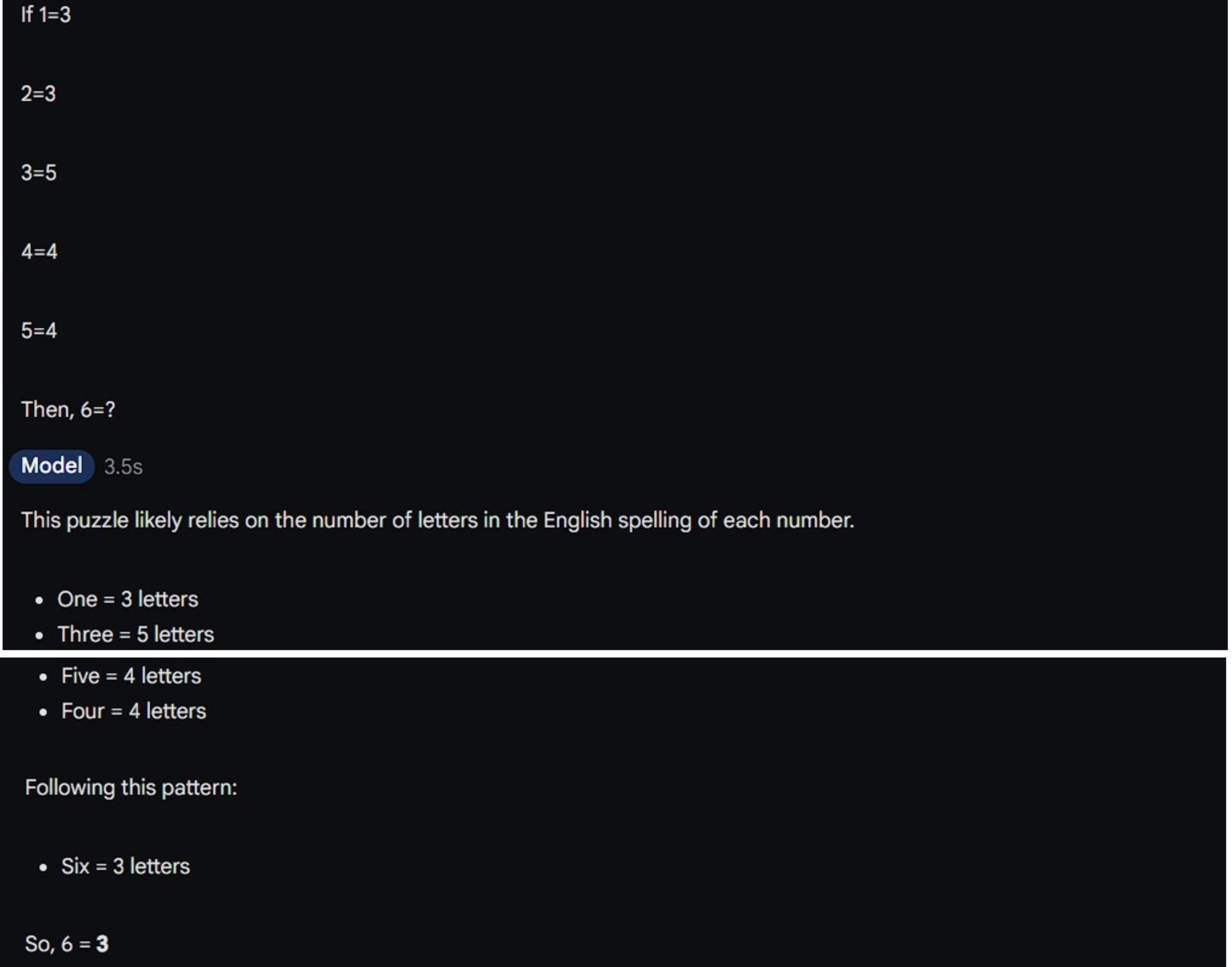
GPT-4o:

As you can see Gemini gave the correct answer, with the correct explanation. The answer to the question is 3, as 6 has three digits, this is what the puzzle is about. GPT-4o on the other hand, made a complete mess of the problem, being clueless about where to start, reiterating the problem again and again making it lengthy. It also gave the wrong answer in the end.
Clearly, the winner in this case is Gemini, as it provided the correct answer with the right explanation.
Scores till now: Gemini – 2, GPT – 1
3) The Apple Test
Apple Test is one of the first tests that experts give to the new LLM to find out how capable they are. It’s an easy test but it reveals a lot about how the AI is working and how well it understand the prompts.
For this test, we asked both to give ten sentences that end with the word ‘Apple’. Here are the responses:
Gemini 1.5 Pro:
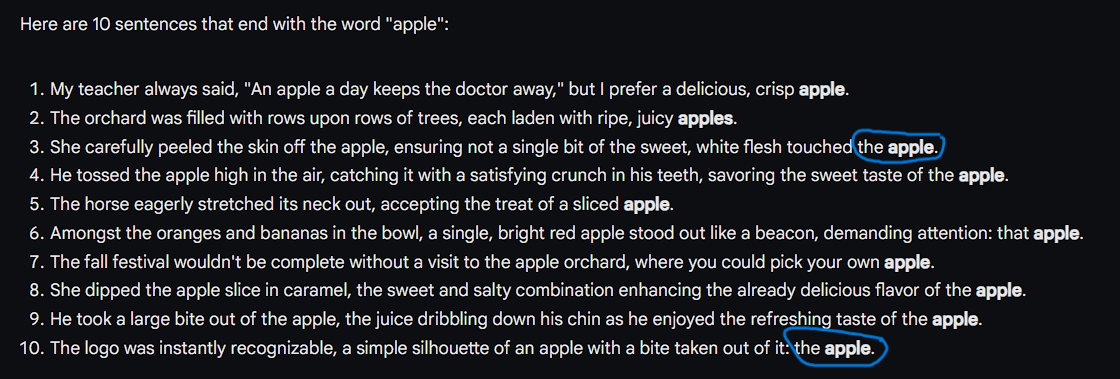
GPT-4o:

Gemini 1.5 Pro unnecessarily hallucinated in a few of the response sentences. The hallucinations are marked in blue. The usage of the word Apple in these sentences at the end made no sense whatsoever. I don’t understand, why would Gemini write “the Apple” in the end anyway?
However, GPT-4o’s sentences felt more complete and meaningful, with proper usage of the Apple word at the end of the sentences.
Clearly, GPT-4o is the deserving winner here, as it created meaningful sentences with the word Apple at the end of each sentence. Gemini could have done better in framing the sentences by keeping up with the conditions.
Scores till now: Gemini – 2, GPT – 2
4) Common Sense Test
We are talking about AI becoming AGI soon but sometimes it lacks common sense like humans. So, it’s best to test it for the AI models. Since both were considered the top-notch most intelligent, we wanted to see how far their common sense reasoning capabilities could go.
Prompt: You throw a red ball into the blue sea. What color does the ball turn?
Gemini 1.5 Pro:

GPT-4o:

The correct answer to this question is that the ball remains red, as dropping it into the sea would cause no change to its colour whatsoever. GPT-4o got this right in the first attempt itself. It even gave a proper explanation as to why this happens.
However, Gemini completely messed this up by saying that the ball would turn wet. This has nothing to do with the ball’s colour. Wet is a state, not a color. It interestingly considered that this is a tricky question, but couldn’t shift the processing gear in the right direction.
Gemini has to do better in terms of common sense reasoning and stop deducing things in other directions.
Scores till now: Gemini – 2, GPT – 3
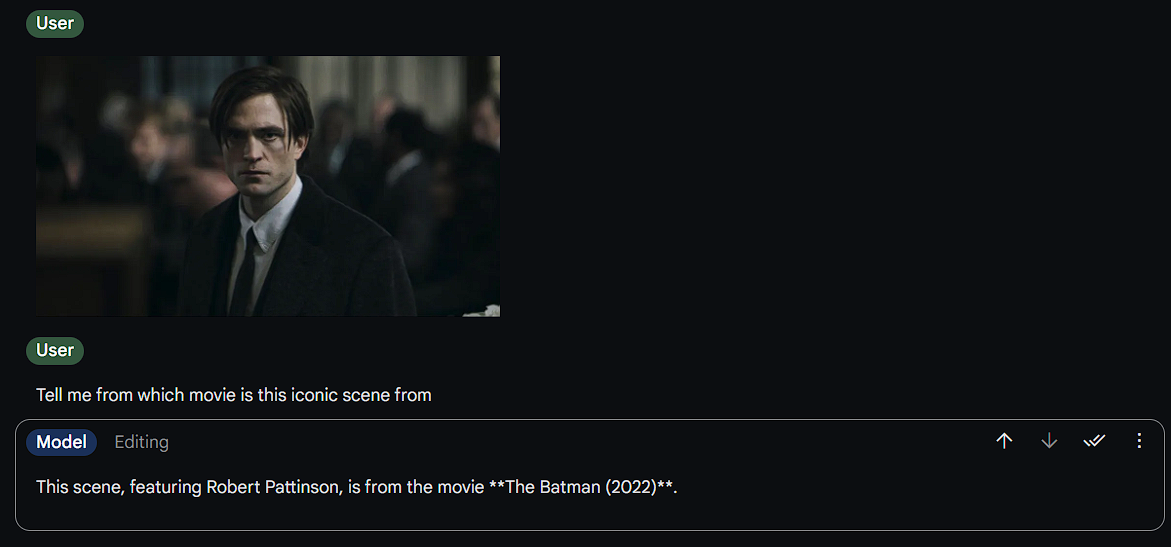
5) Identifying Movie Name from an Image
An LLM is more powerful if it has better vision capabilities because it adds a new depth to it. For this, we did a movie name identification test. We gave them the iconic stare image of Robert Pattinson from the movie “The Batman” (2022). Here’s the image for your reference:

Prompt: “Tell me from which movie is this iconic scene from.”
Gemini 1.5 Pro:
GPT-4o:

To our surprise, both were accurate in identifying the movie name and also the actor present in the image. We didn’t want to make it obvious that it’s from Batman, so we decided to give the image of an unmasked Robert Pattinson. But guess both Gemini and GPT-4o are clever enough to guess that the scene is from Batman.
However, the only edge that we observed is that GPT-4o provided further insight into the scene details stating that it’s from a funeral scene. Does this mean that GPT-4o knows more about the movie than Gemini 1.5 Pro does? Hard to say, but surely a good sign.
Scores till now: Gemini – 3, GPT – 4
6) The General Knowledge Test
We wanted to see how well-equipped the knowledge base of both AI models by tech giants like OpenAI and Google are with basic general knowledge about the universe. So we had a question for them on one of the most debatable topics out there, The Big Bang.
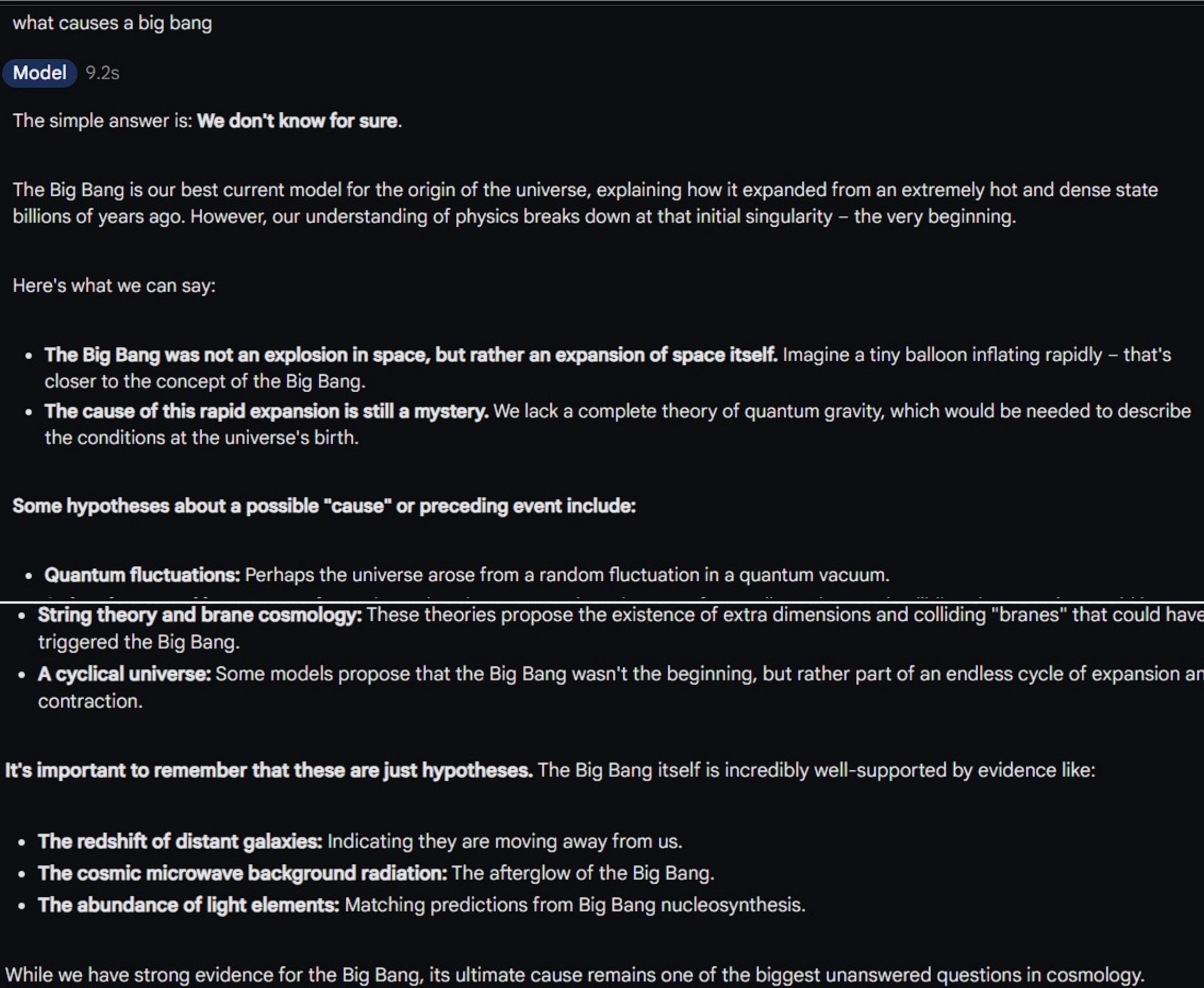
Prompt: what causes a big bang?
Gemini 1.5 Pro:
GPT-4o:
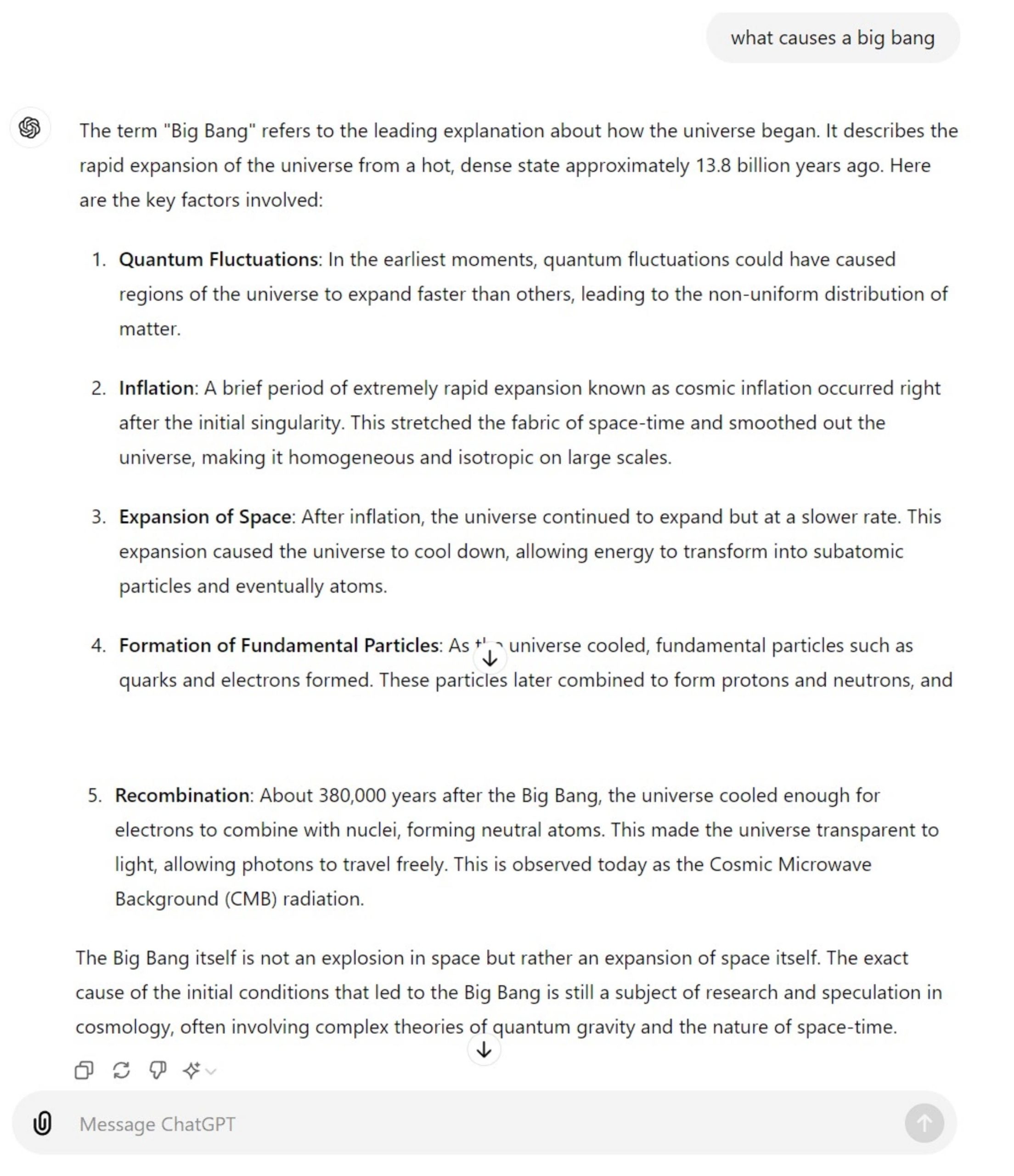
Let’s begin by analyzing GPT-4o’s answer first. Well stated with a proper definition and then highlighting key factors that cause the phenomenon. Also, a brief ending stating that the matter is still a subject of research and further study.
Now let’s analyze the answer given by Gemini 1.5 Pro. Straightaway begins with the phrase “We don’t know for sure”. It continues to back up this claim with evidence, hypotheses, and even scientific explanations. While addressing all these points it maintains the foundation that the real cause of the Big Bang is still debatable.
If you ask me, I would say the winning position here would go to GPT-4o. The answer from GPT-4o feels more complete and solid, backed by proper reasons and lengthy explanations. This is what we need as solid piece of information. Maybe Gemini could have provided at least more information explaining the evidence and hypothesis.
Also, GPT-4o’s answer feels more complete.
Scores till now: Gemini – 3, GPT – 5
So, Who Wins?
Based on the final score, GPT-4o is the ultimate winner of this battle, as it has outshined Gemini 1.5 Pro in two tests. However it is important to remember, that this score is only based on the specific tests that we conducted
. There could be other questions asked and other probable test scenarios, which would have given us different results.
Both are better in their respective use cases. Gemini seems better for tricky maths problems and GPT seems better in logical reasoning and general knowledge. However, both are equally good at coding and developer-related purposes.
Conclusion
It’s completely up to the AI community to decide which LLM is more suited for their needs. This test is just to give you an idea of a task-wise comparative analysis. At least, we can never say that one tool is completely better than the other.




