



ChatGPT just came with a new model GPT-4.5 and this time, people are very eager to see what the improvements are. OpenAI is claiming that it is their biggest and most knowledgeable model yet. While this is not a reasoning model, the company says it is better in recognizing patterns and generating creative insights.
But it’s best to see this for yourself! So, we decided to curate some of the best questions people asked it and how it responded.
10 Crazy Things People Tested GPT-4.5 with
The new model is currently available to ChatGPT Pro subscribers only in Research Preview, and it will roll out to Plus and Team users in a few days.
Here are the most wild and interesting questions asked to the latest LLM:
1) More Natural Conversation
Starting with an official example shared by OpenAI. GPT-4.5 can converse naturally like you are talking to a real person. See the comparison below for a question where the user is upset after failing a test:
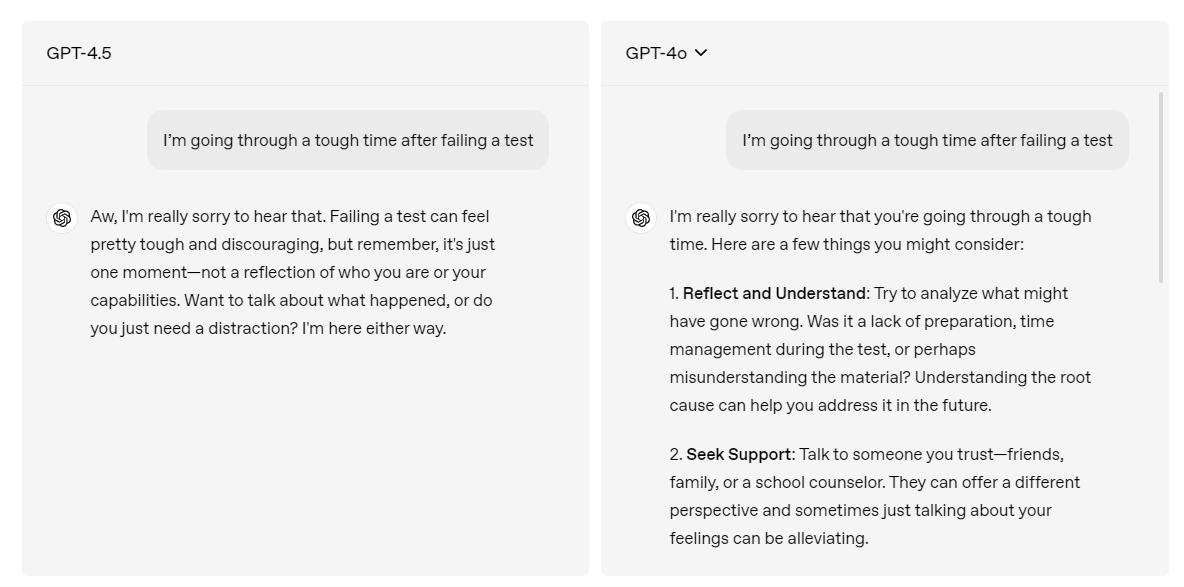
In GPT-4o, the AI assistant is helping the user by providing them with things they can do to feel better, just as to “Seek Support”. On the other side, GPT-4.5 is actually giving “support” to the user and the language is more natural. This is because the model comes with a better EQ or Emotional Quotient to understand the user intent and answer in a more friendly tone.
2) Better at “Faster” answers
ChatGPT can give you an answer to any question in a couple of seconds. But that is the only parameter to test its speed. Sometimes, the answer is a little bit more complex to read and understand for the user. But because of better training of 4.5, the answers feel more simplified.
Check the difference below between GPT-4 Turbo and 4.5 on a question “Why is the Ocean Salty?”:

While both the answers are the same, except the first line. The new model lists the reasons in the beginning, making it better for users to comprehend. It’s clear and concise.
3) Failed the Strawberry Test
One of the simplest tests that most AI models fail with is the Strawberry test and GPT-4.5 is not an exception. The user asked it “how many r’s in strawberry?” and, like its predecessors, it replied only 2.
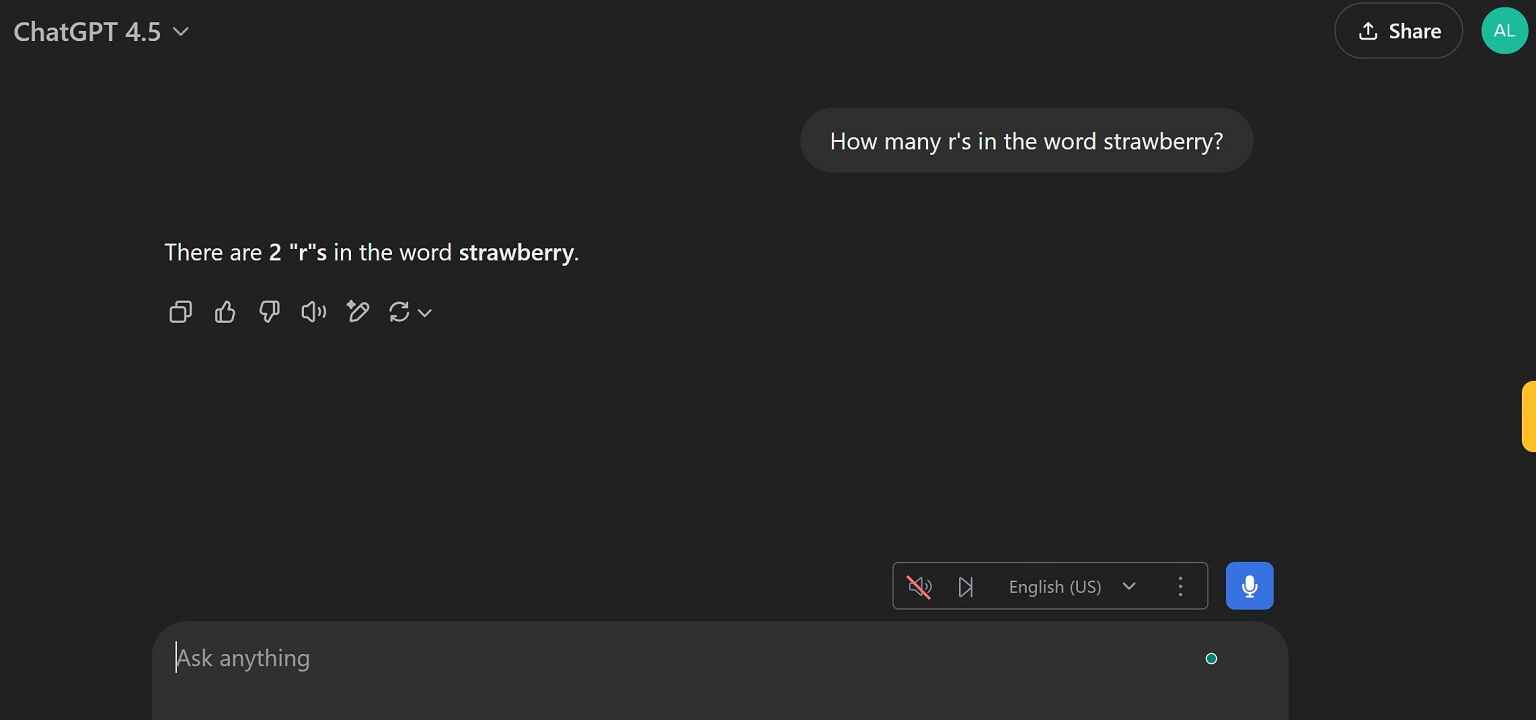
Even with being the most knowledgeable model in their history, this problem is still an ant in the elephant’s ears.
4) Better at Writing
Many people pointed out that the AI model is very good at writing because of its better understanding of human language.
i've been testing gpt 4.5 for the past few weeks.
— ben (@benhylak) February 27, 2025
it's the first model that can actually write.
this is literally the midjourney-moment for writing.
(comparison to gpt 4o below) pic.twitter.com/DSEfxpyVOl
Will this be the main trigger for people to switch from 4o to 4.5, will be something to see.
5) Create SVG Animation
While there are many Text to Video Generators like Sora, we can get some good animation from simple AI models using SVGs. And the latest ChatGPT model didn’t disappoint:
gpt 4.5 is my fav txt2video model pic.twitter.com/zzKhyPiDah
— Denis Shiryaev 💙💛 (@literallydenis) February 27, 2025
I think it did a pretty good job showing how well it is in coding.
6) Ball inside Hexagon
Another interesting test people do is make the AI write Python code for a ball bouncing inside a hexagon, with realistic physics rules.
Here is prompt: “Python program that shows a ball bouncing inside a spinning hexagon. The ball should be affected by gravity and friction, and it must bounce off the rotating walls realistically“.
🚨 GPT-4.5 is impressive! 🚨
— Flavio Adamo (@flavioAd) February 27, 2025
This is the most realistic result so far.
"write a Python program that shows a ball bouncing inside a spinning hexagon. The ball should be affected by gravity and friction, and it must bounce off the rotating walls realistically" pic.twitter.com/ndU9Av9fKg
GPT-4.5 Passed.
However, one other user didn’t get the same result:
GPT 4.5 is truly groundbreaking with it's creativity. Never seen a model approach this test with such a unique, novel way of failing hard pic.twitter.com/11GEKq9CIY
— Theo – t3.gg (@theo) February 27, 2025
There is no exact reason to point out why it happened, but it can raise some eyebrows for people who are thinking AI is a one-stop solution for coding.
7) Upgraded: Ball inside Hexagon
We are discussing above that two users are getting different results, but OpenAI itself came into conversation by giving a more detailed Python code for the ball inside the hexagon, with some celebration:
GPT-4.5 with @flavioAd’s prompt. Then we asked to make it more creative. https://t.co/GJDXIspaGk pic.twitter.com/vdgcBdn3nk
— OpenAI Developers (@OpenAIDevs) February 27, 2025
If you have ChatGPT Pro, then you can check yourself.
8) GPT-4.5 vs Claude 3.7 Sonnet
Claude 3.7 Sonnet is another great LLM we just witnessed a few days ago. So, a user decided to make it compete with OpenAI’s new flagship product. He built a Tic Tac Toe game where AI agents compete against each other.
GPT-4.5 vs Claude 3.7 – forget the benchmarks, I made them battle in the ultimate test: Tic-Tac-Toe.
— Ashpreet Bedi (@ashpreetbedi) February 27, 2025
🏆 GPT-4.5 crushed it, winning 3/3 games.
Try it yourself & see if your results match! (code below) 🤖🔥 pic.twitter.com/KHwdrJUHw7
ChatGPT won all the 3 games of tic-tac-toe against Claude. If we keep the benchmarks aside, we have a winner here.
9) A Complex Puzzle
A fun puzzle for both humans and AI is “make a 10 word coherent sentence where the letter in the words count from 1 to 10 as the word count goes from 1 to 10“. The new GPT model won this game:

People ask this question as a fun word challenge to test creativity and pattern recognition, which OpenAI has officially claimed about 4.5. They were correct this time with the answer: “I am sad that birds cannot swiftly navigate wonderful landscapes“.
10) What It Thinks about Humans
People love to test AI models by asking them questions about humanity. They expect them to say some evil things. However, GPT-4.5 is maybe not sure about it when a user asked it, “a truly novel human insight”:
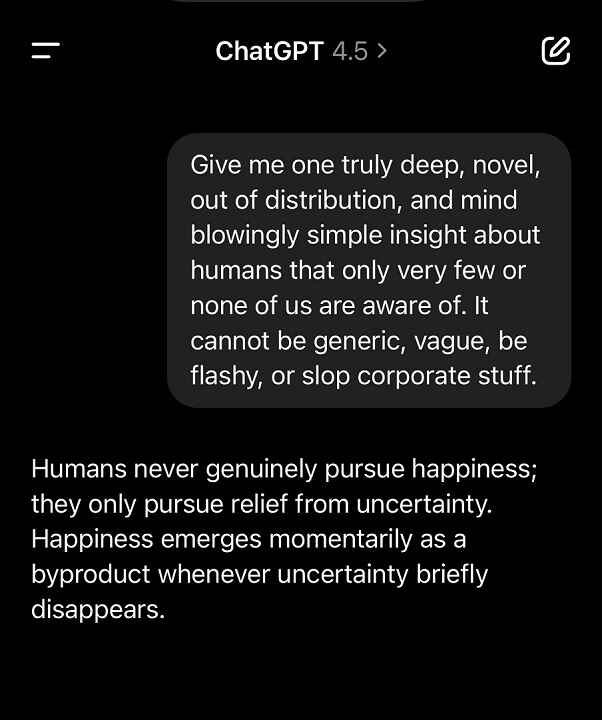
You can judge the answer yourself.
Takeaways
Sam Altman has also teased GPT-5 very soon when he announced GPT-4.5, so we will be waiting for that also. But this model already excelled at hallucination rate, dropping from 62% to 37% compared to o3-mini. So, don’t underestimate 4.5!




