


Unveiled at the 2024 Google I/O event, it is a combined multimodal model based on two other Google research models: SigLIP, a vision model, and Gemma, a large language model.
Highlights:
- Google recently released PaliGemma, an open-source vision language model (VLM) with multimodal capabilities.
- Its capabilities include image captioning, visual question answering, entity detection, and document understanding.
- It is a relatively small 3 billion parameter model and can fine-tune for specific tasks.
PaliGemma unveiled by Google
PaliGemma is a new vision-language multimodal model from Google’s lightweight open-source Gemma family. It is designed for tasks like image captioning, visual question answering, and image retrieval.
Unlike other Gemma models like CodeGemma and RecurrentGemma, PaliGemma is specifically built to translate visual information into written language. It is a composition of a Transformer decoder and a Vision Transformer image encoder, capable of taking both image and text as input and generating text as output, supporting multiple languages.
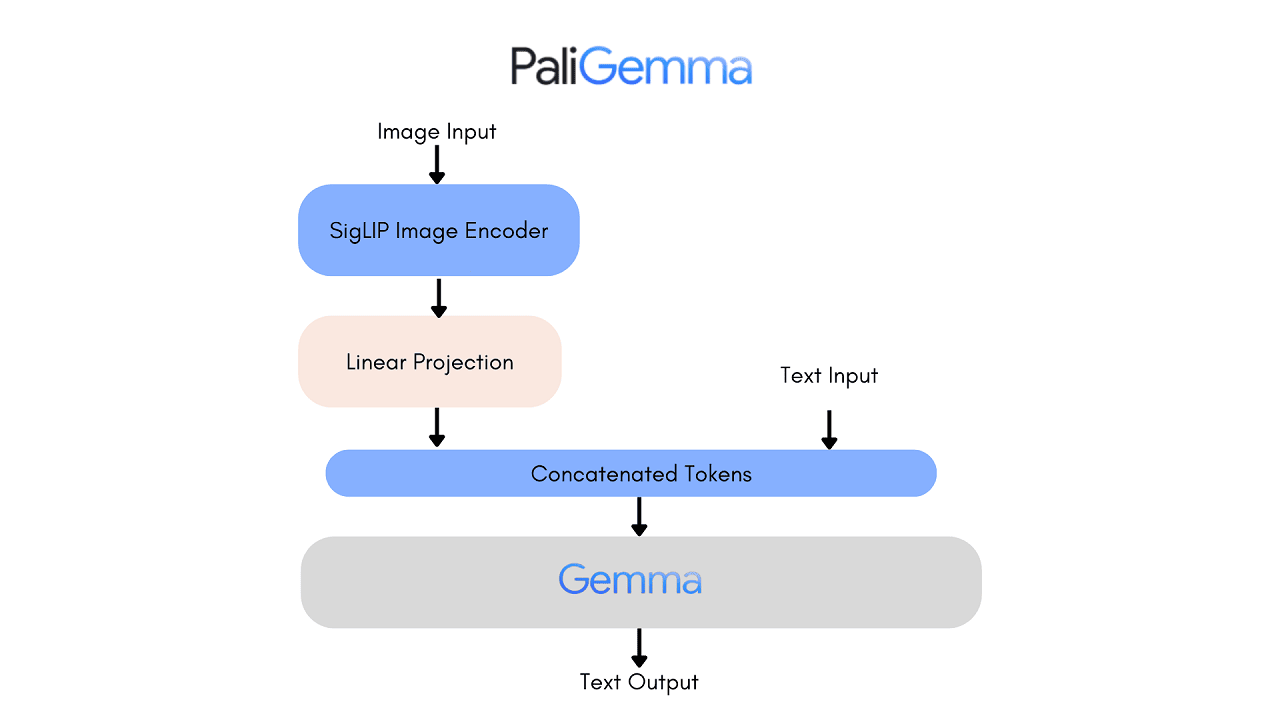
PaliGemma is a relatively small 3 billion combined parameter model, making it efficient and accessible. It comes with permissible commercial use terms, allowing for broad adoption and monetization opportunities.
It also offers the ability to fine-tune for a wide range of tasks, including image and short video captioning, visual question answering, text reading, object detection, and object segmentation, enabling users to customize the model to their specific needs.
PaliGemma includes three types of models:
- Pretrained (PT) checkpoints: These are base models that can be fine-tuned for specific downstream tasks.
- Mix checkpoints: These are pre-trained models that have been fine-tuned on a mix of tasks. They are suitable for general-purpose use with free-text prompts and research purposes.
- Fine-tuned (FT) checkpoints: These are a set of models that have been fine-tuned for specific academic benchmarks. They are available in various resolutions and are intended for research purposes only.
As a small language model (SLM), it operates efficiently without requiring extensive resources, making it suitable for use on devices with limited memory and processing power, such as smartphones, IoT devices, and personal computers.
Web and mobile apps are the more conventional use cases for PaliGemma, but it could also be incorporated into wearables, smart glasses, robots, and other devices that operate within homes and offices.
Features of PaliGemma
PaliGemma is a single-turn vision language model, meaning it works best when fine-tuned to a specific use case. Users can input an image and text string, such as a prompt to caption the image or a question, and it will output text in response, such as a caption, an answer, or a list of object bounding box coordinates.
Unlike other VLMs like Google’s Gemini and Anthropic’s Claude 3, which have struggled with tasks such as object detection and segmentation, PaliGemma boasts a wide range of abilities paired with the ability to fine-tune for better performance on specific tasks.
PaliGemma is well-suited for tasks related to image question answering, captioning, video question answering, captioning, and segmentation. It is useful for straightforward and specific questions related to visual data.
Here are a few examples of the use cases of PaliGemma:
Image Captioning:
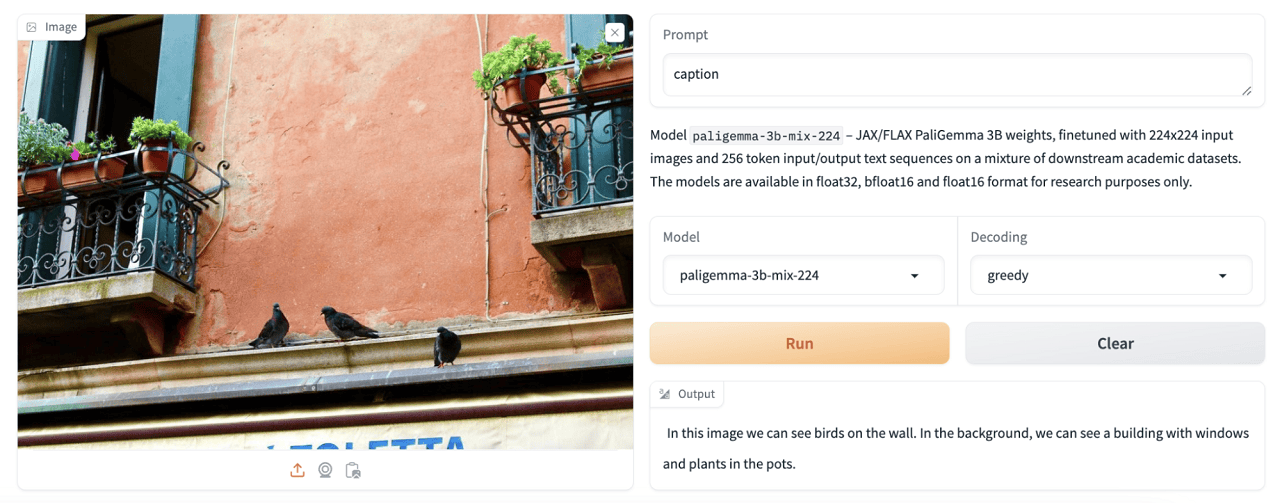
Visual Question Answering:
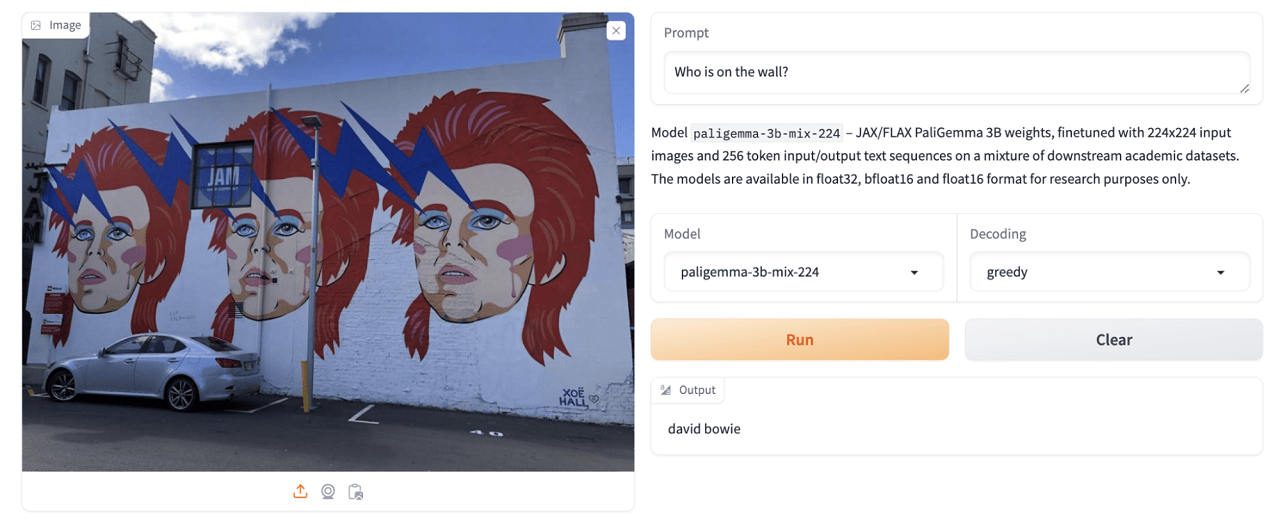
Detection:
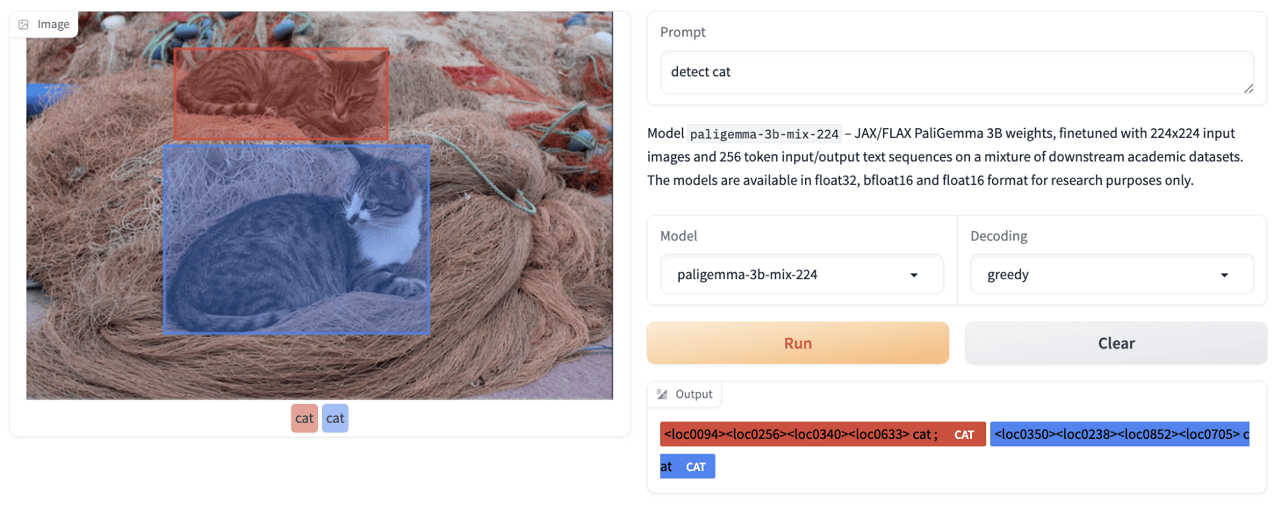
Referring Expression Segmentation:
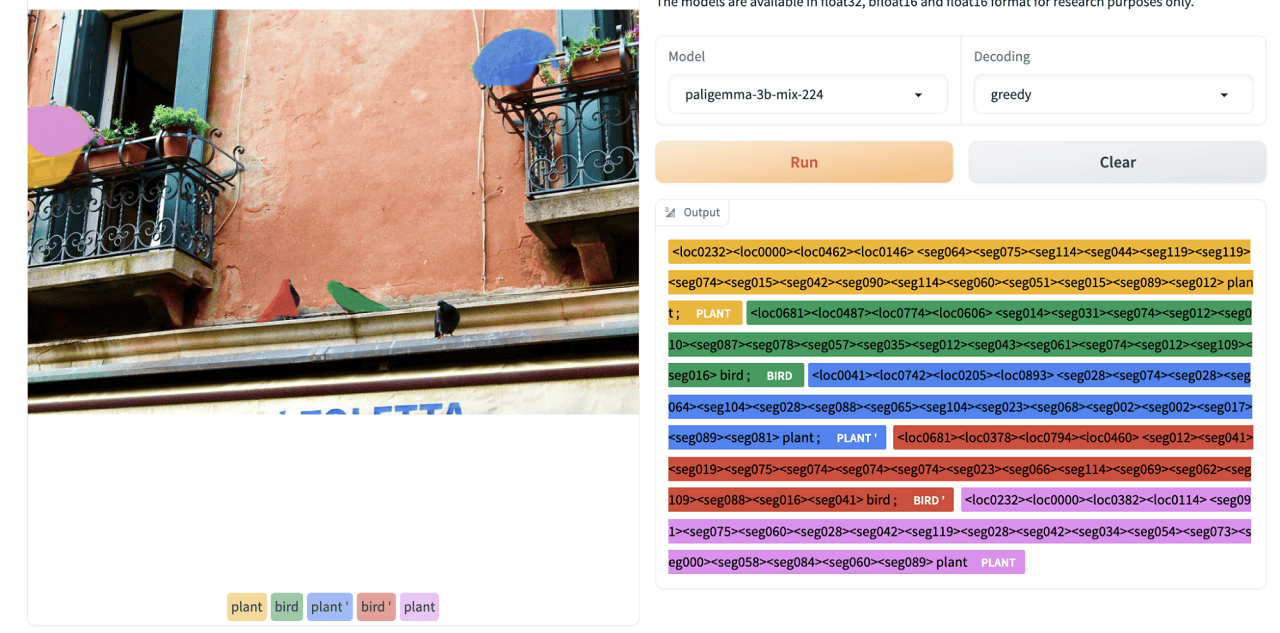
Document Understanding:
Developers may be drawn to the model because it opens up a host of new potentials for their applications. PaliGemma could help app users generate content, offer more search capabilities, or help the visually impaired better understand the world around them.
PaliGemma is built to be fine-tuned, while other models are closed-source.
While PaliGemma is useful without fine-tuning, Google suggests that it is “not designed to be used directly, but to be transferred (by fine-tuning) to specific tasks using a similar prompt structure.” This means that the baseline performance observed with the model weights is just the beginning, and the true potential of the LM lies in fine-tuning it for specific use cases.
Advantages of PaliGemma being Open Source
PaliGemma represents a significant breakthrough in the field of open-source AI. Unlike many other VLMs that are closed-source and proprietary, It is freely available for developers and researchers to explore and build upon.
Additionally, by releasing PaliGemma, Google has democratized access to a highly capable multimodal model, empowering individuals and organizations with limited resources to leverage advanced AI capabilities that were previously limited to tech giants.
The release of it is in line with the principles of open source and promotes the democratization of AI, potentially accelerating research and innovation in the field.
Conclusion
With its wide range of capabilities and the ability to fine-tune for specific use cases, Google’s PaliGemma presents a significant opportunity for developers and researchers to explore and push the boundaries of vision-language models.




