



Google Researchers introduced a novel approach for scaling Large Language Models (LLMs) to process infinitely long text inputs. They developed Infini-attention, a technique that configures LLMs to extend their context window while keeping memory and computational requirements constant.
Highlights:
- Researchers at Google introduced Infini-attention, a novel approach to give LLMs infinite context length.
- Researchers at Google claim that models using Infini-attention can sustain quality across a context window of one million tokens.
- Results demonstrate that Infini-Transformers can efficiently process extremely long input sequences with bounded memory.
What is a Context Window?
The context window is an important term in the field of LLMs, referring to the number of words or tokens that a model considers at any given time when processing text. It determines the extent of the model’s understanding and influences its ability to generate meaningful responses.
If a conversation exceeds the context length, tokens from earlier parts of the conversation may be disregarded, thus in turn affecting the model’s performance and effectiveness. Every model is designed with a specified context window that represents the optimal operating scope for the model.
In today’s world, expanding context length has emerged as a significant focus for enhancing model performance and gaining a competitive edge. Researchers at Google claim that models equipped with Infini-attention can sustain quality across a context window of one million tokens without necessitating extra memory.
Google’s Infini-attention Methodology
Compressive Memory
Infini-attention incorporates a compressive memory into the standard attention mechanism, combining both masked local attention and long-term linear attention in a single Transformer block. It reuses the key, value, and query states from the dot-product attention computation for long-term memory consolidation and retrieval.
The compressive memory is parameterized with an associative matrix, and the memory update and retrieval process is cast as a linear attention mechanism.
Attention Layer
In Infini-Transformers, the attention layer maintains both global compressive and local fine-grained states. The local attention context is computed within each input segment, while the compressive memory stores and retrieves the entire context history.
The final contextual output is an aggregation of the long-term memory-retrieved values and the local attention contexts.
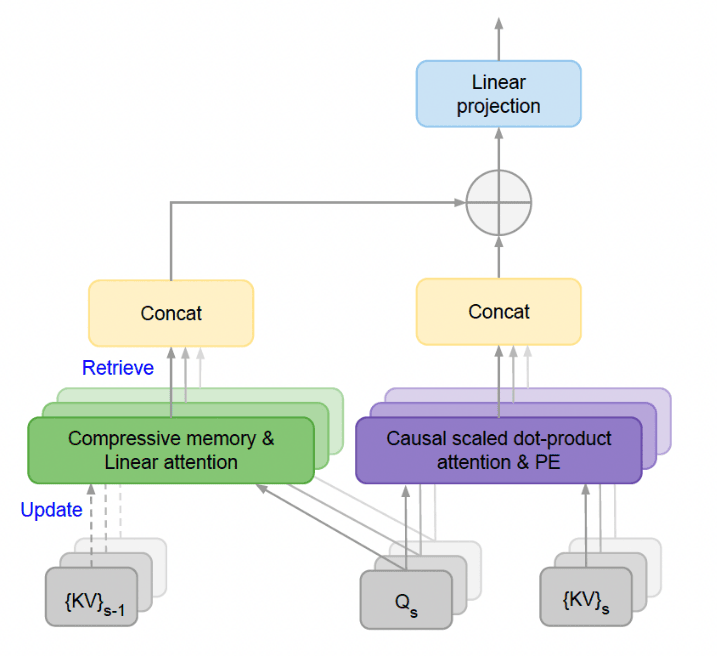
Infini-Transformers process extremely long inputs in a streaming fashion, enabling them to scale to infinitely long contexts with bounded memory and compute resources. The approach introduces minimal changes to the standard scaled dot-product attention and supports plug-and-play continual pre-training and long-context adaptation.
The image below shows a comparison between Google’s Infini-Transformer, and Transformer-XL. Like Transformer-XL, Infini-Transformer functions on a sequence of segments, computing standard causal dot-product attention within each segment.
This attention computation is localized within the segment’s N tokens (where N represents the segment length).
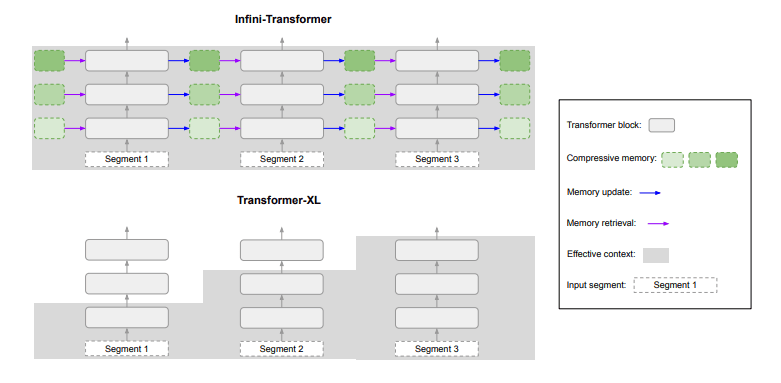
Unlike local attention, which discards previous segment attention states, Infini-Transformers reuse these states to maintain a comprehensive context history, achieved through a compressive memory approach.
Infini-Transformer has an entire context history whereas Transformer-XL discards old contexts since it caches the KV states for the last segment only. Thus, each attention layer in Infini-Transformers integrates both global compressive and local fine-grained states, defining an efficient attention mechanism called Infini-attention.
Experiments Conducted
The effectiveness of Infini-Transformers was demonstrated through experiments on various tasks involving extremely long input sequences. The experiments conducted are as follows:
- Long-context language modeling: Small Infini-Transformer models were trained and evaluated on PG19 and Arxiv-math benchmarks. The models outperformed Transformer-XL and Memorizing Transformers while maintaining significantly fewer memory parameters.
- 1M passkey retrieval benchmark: A 1B LLM with Infini-attention was continually pre-trained on 4K length inputs and fine-tuned on the passkey retrieval task. The model successfully solved the task with up to 1M context length after fine-tuning on only 5K length inputs.
- 500K length book summarization (BookSum): An 8B LLM model with Infini-attention was continuously pre-trained with 8K input length and fine-tuned on the BookSum task. The model outperformed the previous best results and achieved a new state-of-the-art BookSum by processing the entire text from the books.
Results
In the long-context language modelling experiments, Infini-Transformers achieved better perplexity scores than Transformer-XL and Memorizing Transformers while maintaining 114x fewer memory parameters. Further increasing the training sequence length to 100K resulted in even lower perplexity scores.
For the 1M passkey retrieval benchmark, Infini-Transformers solved the task with up to 1M context length after fine-tuning on only 5K length inputs, demonstrating their ability to extrapolate to much longer input lengths than seen during training.
In the 500K length book summarization task, Infini-Transformers outperformed previous state-of-the-art models and achieved better Rouge scores with more text provided as input from the books.
The results demonstrate that Infini-Transformers can efficiently process extremely long input sequences with bounded memory and computation, making them a promising approach for scaling LLMs to infinitely long context windows. Infini-attention allows for easy adaptation of existing LLMs to long-context tasks through continual pre-training and fine-tuning.
Conclusion
Google’s introduction of Infini-attention within Infini-Transformers presents a groundbreaking approach for scaling LLMs to process infinitely long text inputs.




