



Google keeps levelling up its Generative AI game daily as we progress with AI models and technologies. Recently it released Gemini 1.5 Pro with new features. Now, Google announced two new variant additions to Gemma’s lightweight family of state-of-the-art models.
Highlights:
- Google unveils two latest additions to the Gemma family, CodeGemma and RecurrentGemma.
- Comes with several features such as code completion, improved accuracy, low memory requirements and much more.
- Designed to be safe and available on a wide variety of platforms.
2 New Google’s Gemma Variants
Google has introduced Gemma lightweight models called CodeGemma and RecurrentGemma. These variants are open-source AI large language models that will add coding capabilities and opportunities for experimental research.
“Today, we’re excited to announce our first round of additions to the Gemma family, expanding the possibilities for ML developers to innovate responsibly: CodeGemma for code completion and generation tasks as well as instruction following, and RecurrentGemma, an efficiency-optimized architecture for research experimentation.”
Google announced Gemma earlier this year and they had stated that they would be introducing several lightweight variants to the Gemma family in the days to come. The Gemma models have been built on the same architecture and technical base that was used to build Gemini models.
The response from the technical community of developers who used Gemini for several fine-tuning tasks, Kaggle Notebooks, and much more, highly inspired Google to build upon the first round of Gemma variants.
The Hugging Face model repository, the Vertex AI Model Garden (Google’s cloud service for managed AI development), the Gemma website, Nvidia Corp.’s NIM application programming interfaces, and Kaggle are the ways to access CodeGemma for now.
Google also stated that the same platforms will also support RecurrentGemma in the days to come.
The two new Gemma variants have been designed and developed for both Researchers and Developers to help them across several use cases and provide technical benefits in diverse aspects. Let’s take a look at both of them!
CodeGemma for Developers and Businesses
CodeGemma is a three-size coding model that is lightweight and powerful. The first is a trained 7 billion-parameter variant, the most basic form that any developer would use for regular development tasks, and it is focused on code completion and code generation jobs.
The next is an instruction-tuned variant with 7 billion parameters for code chat and instruction following, which can comprehend developer intentions, suggest code modifications, and supply code blocks. For quick completion, there is a trained 2 billion-parameter model that is sized to fit on a local computer.
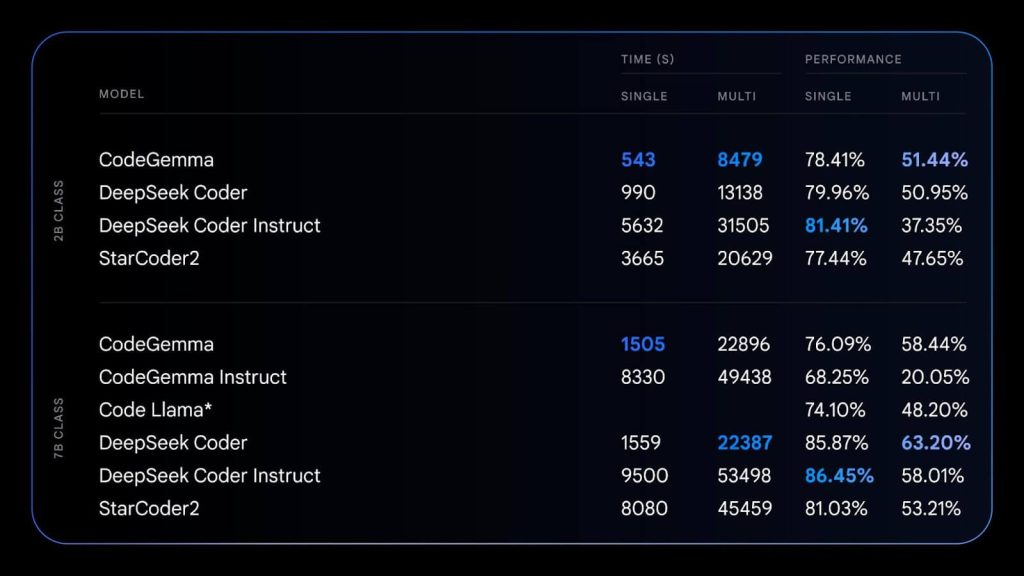
Take a look at this image below where you can see CodeGemma’s both 2B and 7B model variants showing excellent performance benchmarks compared to StarCoder 2, Code Llama, and DeepSeek Coder on both single and multi-line code completion tasks.
Let’s look at the vast features that CodeGemma has to offer:
- Intelligent Generation and Completion of Code: CodeGemma can now produce complete code blocks and even complete code lines using these new model versions, either locally or via cloud resources. This is good news for developers as they can now save their coding progress both online and offline across a wide range of devices and tools.
- Improved Accuracy: 500 billion tokens of mostly English language data from web pages, math, and code were used to train CodeGemma. Both the 2B and 7B models produce code that is more semantically intelligible and syntactically correct, which helps to decrease errors and debugging time. This is highly beneficial in today’s developer community as they are continuously looking for ways to mitigate coding errors and save time from debugging related tasks.
- Proficiency in Multiple Coding Languages: CodeGemma is proficient in several coding languages such as Python, JavaScript, Java, and several other coding languages. So, coding enthusiasts, who chose to work on several coding languages for optimized efficiency and better results, should highly look forward to working with CodeGemma for their projects and deployments. Here they will get more options to work on and improvise their skills.
RecurrentGemma for Researchers
RecurrentGemma is a technically unique model that enhances memory efficiency by utilizing both local attention and recurrent neural networks. The main underlying technology behind RecurrentGemma is a combination of Recurrent Neural Networks leveraged by Large Language Model architecture.
This allows the model to overcome several shortcomings which Recurrent Neural Networks (RNNs) face. Recurrent neural networks (RNNs) have fast inference and scale efficiently on long sequences, but they are difficult to train and hard to scale, this is where LLMs come into the picture to address these shortcomings.
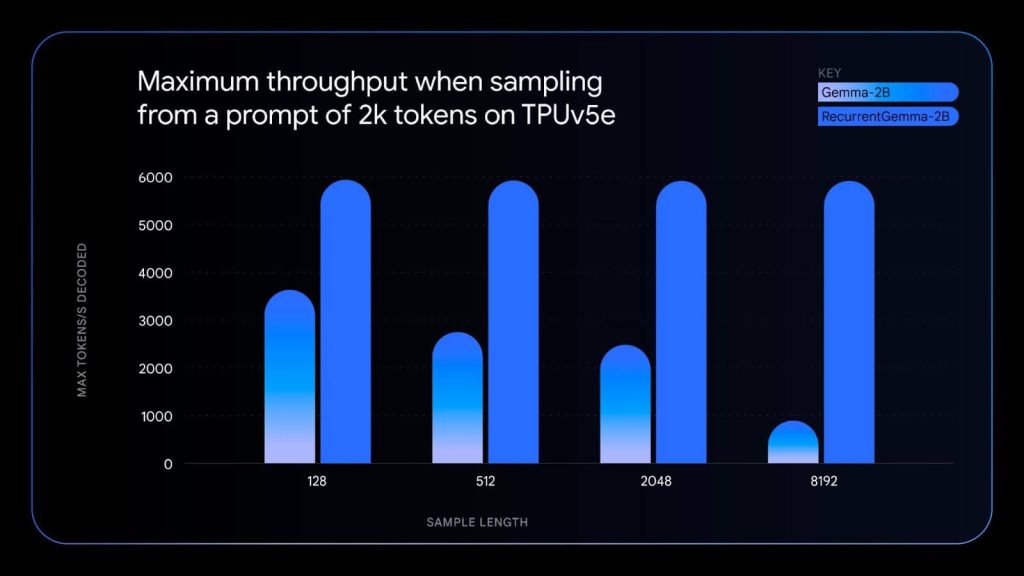
Take a look at this image below where you can see RecurrentGemma producing higher levels of Max Tokens at varying sample lengths compared to the Gemma 2B model.
Let’s look at RecurrentGemma’s groundbreaking features, solely designed to ease work for Researchers:
- Reduced memory usage: RecurrentGemma is a model that aims to increase memory efficiency by utilizing local attention and recurrent neural networks. This enables the model to significantly reduce memory requirements, making it suitable for usage on systems with constrained memory, including central processing units or single graphics processing units. This is very good news for the developer community as developers nowadays are looking for the latest ways to minimize memory requirements and improve processing times for several coding-related tasks and project works. This is highly efficient as most LLM models nowadays require highly powerful GPUs and CPUs to achieve optimality, but not RecurrentGemma.
- Increased throughput: RecurrentGemma can execute inference at much larger batch sizes because of its lower memory utilization, which results in the generation of a huge number of tokens per second—especially when creating extended sequences. In simpler words, when running live data at much larger batch sizes, recurrent neural networks in particular scale well when producing extended sequences, enabling the model to produce more tokens per second even with constrained memory. This is what users want, more output at the expense of lesser resources.
After a long time, we have a Gen AI tool in the market specifically designed to improve innovation opportunities for researchers, thanks to Google. Its widespread low memory capabilities and increased throughput pave the foundation for similar lightweight AI models in the future.
Flexibility and Safety Aspects
Google designed CodeGemma and RecurrentGemma considering the aspects of responsible AI development and safety measures considering the increased use of deep fakes, hallucination, and AI plagiarism in recent months.
Whenever a new Gen AI tool arrives in the market it is normal to be concerned about possible safety implications, but Google has made sure that we as users can be hassle-free about these concerns. The company said that the models are designed to deliver safe and responsible results as well.
Both the Gemma variants are also designed to be optimal and flexible in a widespread variety of platforms. CodeGemma and RecurrentGemma are both JAX-based and compatible with PyTorch, Gemma.cpp, Hugging Face Transformers, and JAX.
On a variety of hardware, such as laptops, desktop computers, NVIDIA GPUs, and Google Cloud TPUs, users can enable cost-effective deployment and local experimentation.
Conclusion
This is just the beginning of Google’s journey with Gemma’s lightweight family of AI large language models. As we look into both CodeGemma and RecurrentGemma, we can’t help but be impressed by its high capabilities at such low requirements. This is what lightweight models can do, and we are already getting a taste of it from Google.




