



Google announced that Gemini 1.5 Pro is getting several improvements in the form of Native Audio Understanding, System Instructions, JSON Mode, and much more. Also introduced a brand-new text-embedding model named Gecko, which beats several other comparable models.
It’s been almost two weeks since Google publicly released the latest and most powerful version of Gemini 1.5 Pro. The AI chatbot is accessible and free to use for everyone in the Google AI Studio.
Several tech enthusiasts, developers, and users worldwide have long awaited its arrival, and now that it is here everyone can’t wait to have their hands on the latest features that come with it. The chatbot has also been released in more than 180+ countries.
What comes with the latest features and what use cases can be achieved with them? Let’s explore all these aspects in-depth from this article.
5 New Features of Gemini 1.5 Pro
Gemini 1.5 Pro is a very powerful multimodal chatbot that comes with several capabilities such as analyzing documents, solving complex code problems, debugging codes, automating tasks, and much more. All of these features can be attributed to its one-million context window that comes with several features:
- Over 700,000 words
- Over 30,000 lines of code
- 11 hours of audio
- 1 hour of video
They are also bringing in a next-generation text-embedding model that can compete with several well-known models such as Mistral-7b and OpenAI’s text-embedding-3- large-256 model.
The brand-new features are putting it on a pedestal of AI chatbots. With the help of these features, several developers and AI enthusiasts can perform optimal solutions in their tasks and functions. Let’s look at all these features and understand the use cases that come with them:
1) Comprehending Audios
With the release of Gemini 1.5 Pro, Google is adding audio (voice) understanding to the list of input modalities available in Google AI Studio and the Gemini API.
Furthermore, for videos uploaded to Google AI Studio, 1.5 Pro can now reason across both picture (frames) and audio (voice), and they plans to release API support for this soon.
This feature holds immense potential as developers can have their audio processed in a more enhanced way. The chatbot can extract valuable information from user audio, and users can ask for this extracted information in several ways as output from Gemini.
In the video below, we can see the Audio modality in action, where a presentation audio of approximately 117,750 tokens was uploaded to Gemini. Later it was asked to generate five MCQs based on the audio and also provide a section with its respective answers.
Gemini 1.5 Pro has been updated – now Google’s neuron can process audio.
— Evinstein 𝕏 (@Evinst3in) April 10, 2024
You can fill a path for up to 11 hours! It turns out that you can upload any training course on Python and turn it into a text-based one, at the same time understandable to a five-year-old child. pic.twitter.com/Y5PexHxEER
Gemini did an amazing job in comprehending the audio and generating the MCQ with the answers. This just shows how amazing and advanced it has become in interpreting large audio token files and analyzing information from them.
Not only can Gemini now understand spoken words, but it can also pick up on the tone and mood in audio and even identify sounds like dogs barking or automobiles driving by.
Learn more about Gemini 1.5 Pro’s audio processing feature here.
2) Analyzing Videos
Gemini 1.5 Pro can also analyze uploaded videos or videos from external links. It can analyze the whole content of the video and generate meaningful information from the video’s content.
Matt Shumer, the CEO of HyperWriteAI, experimented with the open-source Gemini 1.5 Pro. He gave several YouTube video links as inputs and asked the model to summarize the videos and give reviews for each.
Introducing `gemini-youtube-researcher` 📈
— Matt Shumer (@mattshumer_) April 10, 2024
An open-source Gemini 1.5 Pro agent that LISTENS to videos and delivers topical reports.
Just provide a topic, and a chain of AIs with access to YouTube will analyze relevant videos and generate a comprehensive report for you. pic.twitter.com/bd0OZkvCkq
It did an amazing job in analyzing the videos. This is quite a groundbreaking feature as analyzing videos from external links has been a hectic task or impossible task for most LLMs till now, but Gemini’s capabilities prove to be otherwise.
3) System Instructions
Gemini now allows users to guide the model’s responses with system instructions. They can define roles, formats, goals, and rules to steer the model’s behaviour for the specific use case.
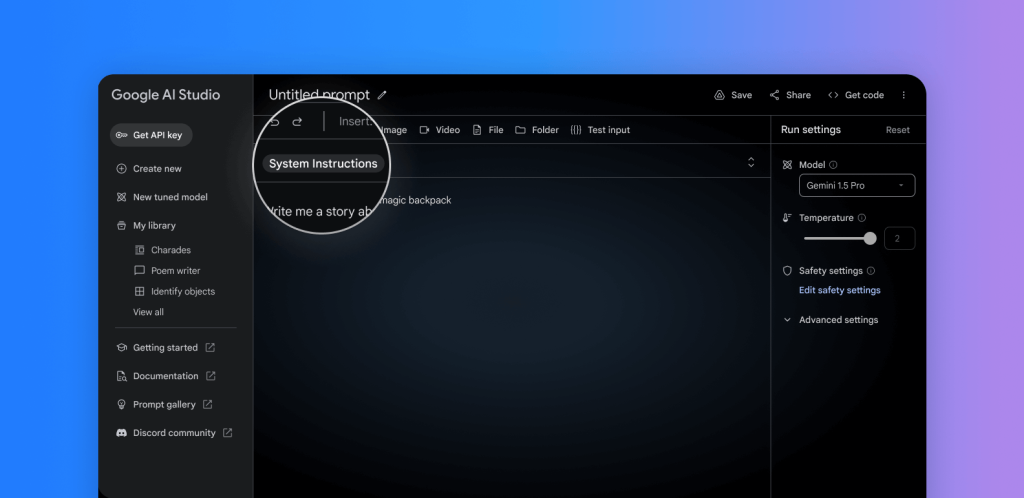
This is an amazing feature as now users can completely control the nature and type of responses that they want from Gemini.
They can have various types of answers generated varying specifically from different preferences and use cases. So do talk to Gemini about the requirements in the system instructions and have the responses adjusted to style required.
4) JSON Mode and Function Calling Enhancements
Users can now instruct the Gemini Model to output JSON objects. This mode makes it possible to extract structured data from pictures or text. Users can upload any image or video and ask Gemini to output the unstructured data objects into JSON objects.
Gemini 1.5 Pro now supports audio inputs, system instructions, and JSON mode pic.twitter.com/VB22IgDzto
— Phil (@phill__1) April 9, 2024
Google stated that for now users can get started with cURL, and also that Python SDK support will be coming soon to the model. So go ahead, and enjoy extracting data with JSON capabilities.
Gemini’s function-calling abilities have also been enhanced by Google. Reliability can now be increased by choosing modes that restrict the model’s outputs. Select the function itself, the text, or the function call.
Recently, OpenAI’s GPT-4 Turbo Vision model introduced similar JSON and Function Calling abilities which highly leverage it for a variety of developer-related tasks and functions.
5) A New Embedding Model with Improved Performance
Google has released their latest text-embedding model named text-embedding-004, (text-embedding-preview-0409 in Vertex AI) aka Gecko. This model has been released via the Gemini API.
The model outperforms several well-known models such as Mistral-7b and OpenAI’s text-embedding-3- large-256 model on the MTEB benchmarks. MTEB stands for Massive Text Embedding Benchmarks and it is a great metric to evaluate text embedding models based on average word embeddings.
It achieves a stronger retrieval performance than most models:
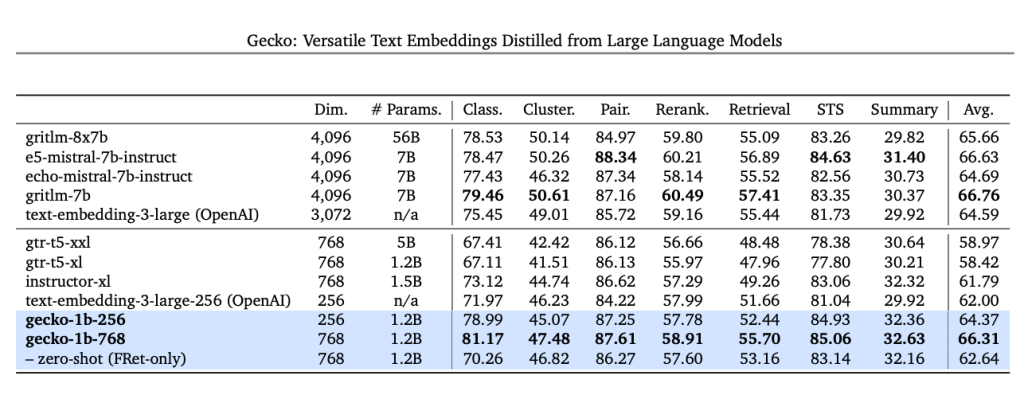
Overall, all of these features are just the beginning of 1.5 Pro’s evolution as a high-quality and efficient LLM. Google has promised more improvements in the days to come.
Conclusion
Gemini’s enhanced feature upgrades have tremendous potential to disrupt the field of Generative AI. Several users worldwide have awaited the arrival of these features and now Gemini stands tall in the AI Market leveraged with these enhancements.




