



At its Next 2024 event, Google announced major updates for its Gemini 1.5 Pro model, but the new listening capabilities stand out!
Highlights:
- Google Gemini 1.5 Pro can now listen to uploaded audio files and interpret them without referring to written transcripts.
- The new feature can be used to process information from recorded interviews, videos and earning calls.
- The model is now available in public preview through its Vertex AI platform to build applications.
Gemini 1.5 Pro Can Now Process Audio Streams
Google now allows users to prompt audio files to the Gemini 1.5 Pro model. The model then extracts relevant information from the audio inputs, including music and speech, to generate a response based on the prompt.
This feature lets users feed large audio files without the need to provide transcripts for them. Users can also record audio clips instead of typing long prompts.
Gemini excels at interpreting very large audio files within a matter of seconds. When an audio file is uploaded, it automatically counts the number of tokens and displays it on the interface. It then gives the required response in a structured format.
It can summarize the audio, extract necessary information, answer direct questions, provide reasoning, and explain concepts. Thus, with Gemini being given ‘ears,’ it enhances the user experience and makes it extremely convenient for users when they need to upload audio files or speak out lengthy questions.
The announcement came with many new updates at Next ’24 event, including making it available in public preview, inpainting in Imagen 2.0, and new prompt management capabilities for their large models. Here is how they described the new feature:
“In addition, we are announcing that Gemini 1.5 Pro on Vertex AI now supports the ability to process audio streams including speech, and even the audio portion of videos. This enables seamless cross-modal analysis that provides insights across text, images, videos, and audio — such as using the model to transcribe, search, analyze, and answer questions across earnings calls or investor meetings.”
Now, users can upload their lectures, recorded interviews, conferences, earning calls, music samples, conversations with friends, podcasts or even audio from videos, and get them analyzed through Gemini. After its initial launch, developers found many interesting features in Gemini 1.5 Pro after testing.
How to Access It?
The new audio processing capabilities to Gemini 1.5 Pro model through their Vertex AI platform.
Anyone can access the model available for free through Google DeepMind’s official website. Click on ‘Try Gemini 1.5.’ You will have to sign in before being redirected to the Google AI studio through which the model can be tested for free. The interface for the model is shown below:
Now, to upload audio files, the user will have to first connect your Google Drive. After this, they can record an audio, upload an audio from Drive, or upload an audio from your local machine.
What You Can Do with this new Listening feature?
We tested the audio feature for various use cases. They are as follows:
Example 1: Conversation
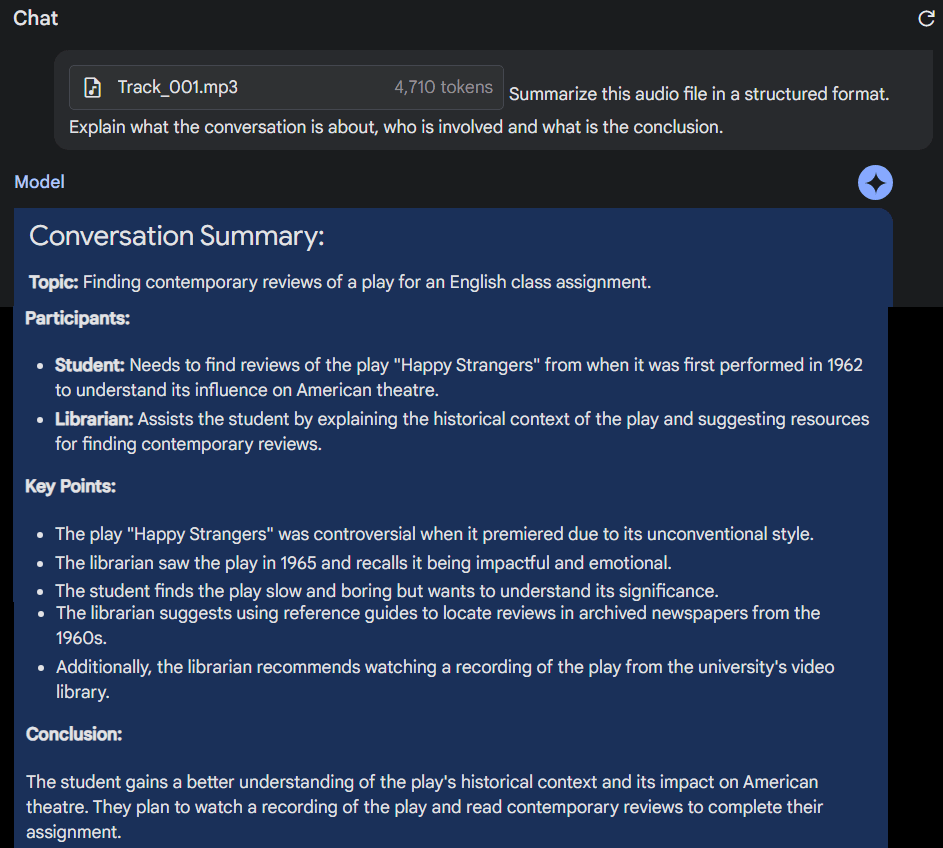
We provided Gemini with an audio of a conversation between a college student and a librarian. We asked it to summarize the audio in a structured format. The audio is of 2 minutes and 36 seconds.
1) I provided Gemini with an audio of a conversation between a college student and a librarian. I asked Gemini to summarize the audio in a structured format that included all the important information mentioned in the audio. I also asked a follow-up question. pic.twitter.com/gNCIOTnPsR
— Dhruv (@dhruvvvvvvvvv_) April 9, 2024
Gemini was able to respond within 20 seconds thus highlighting the speed of interpreting audio as mentioned above. It generated an accurate response that included all the important information mentioned in the audio.
We then provided Gemini with a small part of the audio we previously provided. We asked it to listen to the audio and give an interpretation of what exactly the dialogue means. It provided an accurate explanation of what the dialogue meant in the context of the conversation.
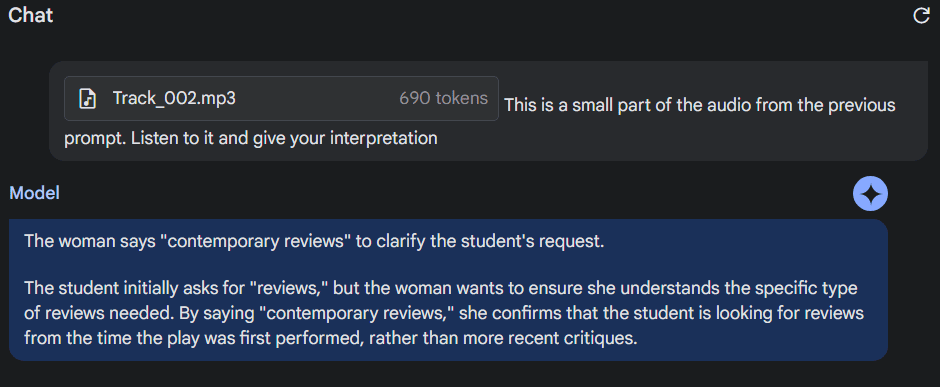
Thus, it can also accurately answer follow-up questions based on specific parts of the audio.
Example 2: Summarization
We provided Gemini with an audio from a geography lecture and asked it to summarize the lecture in short.
2) I provided Gemini with an audio from a geography lecture and asked it to summarize the lecture in short. This was a very lengthy video of precisely 5 minutes and 38 seconds. Gemini was able to provide a short and simple summary within 20 seconds which is really impressive. pic.twitter.com/ZmHxa6BAtW
— Dhruv (@dhruvvvvvvvvv_) April 9, 2024
This was a very lengthy video of precisely 5 minutes and 38 seconds.
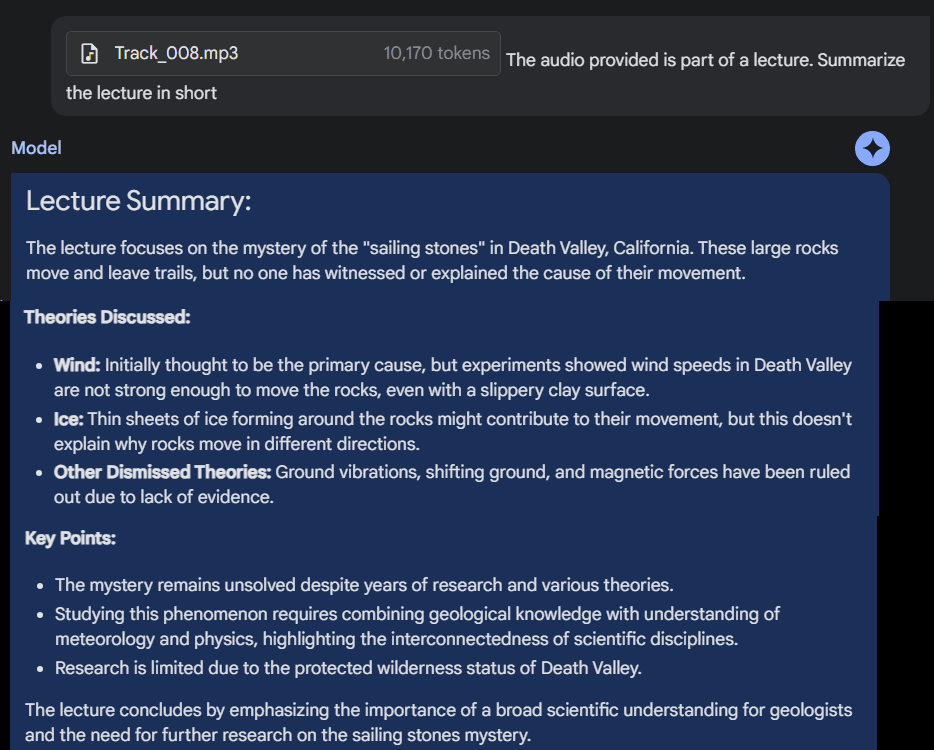
It was able to provide a short and simple summary within 20 seconds which is impressive considering the length of the audio clip.
Example 3: Record Own Audio
Here, we asked Gemini a question using the ‘record an audio’ option. In the audio, we requested it to explain the different evaluation metrics for a Machine Learning model. We also asked it to explain how a confusion matrix is built along with the different formulae that can be derived from it.
3) I asked Gemini a question using the ‘record an audio’ option. I requested Gemini to explain the different evaluation metrics for a Machine Learning model. I also asked it to explain how a confusion matrix is built along with the different formulae that can be derived from it. pic.twitter.com/l15NFKB2Wz
— Dhruv (@dhruvvvvvvvvv_) April 9, 2024
Gemini provided an answer for every question accurately. It also provided additional evaluation metrics other than the ones derived from the confusion matrix.
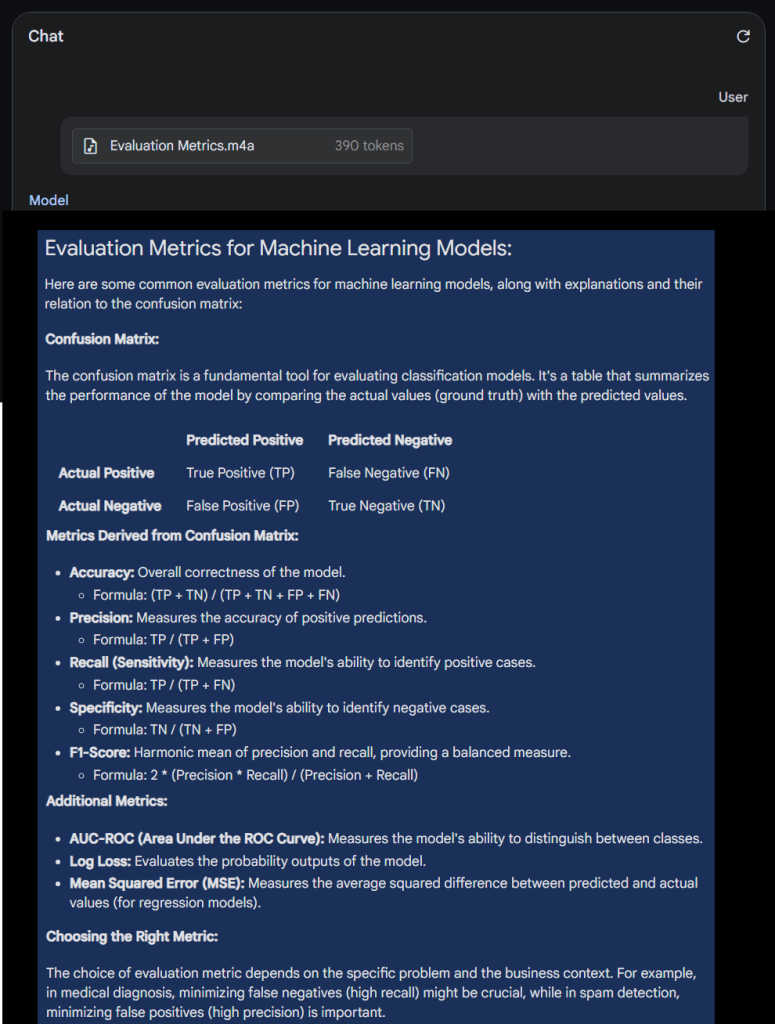
This is quite impressive as users now don’t need to type out long questions. Instead, they can just speak out their questions in a few seconds and the model will understand the question and provide the correct response.
Similar capabilities are available in OpenAI’s ChatGPT, so now there is good competition between Gemini 1.5 and GPT-4.
Conclusion
Google’s Gemini 1.5 Pro model’s new feature for audio interpretation without transcripts marks a significant advancement in the ever-improving field of LLMs. With its ability to swiftly summarize lengthy audio files and accurately respond to spoken queries, Gemini promises to improve user interaction and enhance the overall user experience.




