



While we were just still hovering over SORA’s magnificent capabilities, there is now a new player in the field of Video Generative AI by Chinese company Alibaba. Their EMO AI can make your photos alive, let’s find out how.
Highlights:
- Alibaba researchers have developed EMO, a generative AI tool that brings portraits and images to life.
- Comes with all-new audio-to-video technology in the form of a Diffusion Model.
- Has limitations but still outperforms various traditional models on several benchmark scores.
What is EMO AI by Alibaba?
Alibaba announced a new AI tool named EMO that can create realistic-looking videos from existing images and portraits. The tool can also integrate audio inputs with the video where the subject can speak and sing.
EMO is short for Emote Portrait Alive. It is developed by researchers at Alibaba’s Institute for Intelligent Computing. This tool is narrowing the gap between realism and artistry by bringing together AI with video generation. It can animate input images by synchronizing lip and eye movements.
Here is how they described the tool in their research paper:
“We proposed EMO, an expressive audio-driven portrait-video generation framework. Input a single reference image and the vocal audio, e.g. talking and singing, our method can generate vocal avatar videos with expressive facial expressions, and various head poses, meanwhile, we can generate videos with any duration depending on the length of input audio”
Several impressive features come with EMO AI. Here we have highlighted its key functionalities that you need to know:
1) Still Portrait Images to Videos
A single portrait picture can be given life using EMO AI. It creates lifelike movies of the person in the picture, giving the impression that they are speaking or singing.
A reference image is used to create a video that replicates the image’s appearance. It suggests using blended shapes and head positions to teach the image how to create facial expressions and head motions on its own.
These are then employed to generate a three-dimensional facial mesh, which acts as an intermediary representation to direct the production of the final video frame.
2) Audio to Video Conversion
The breathtaking aspect of this tool is that its cutting-edge technology allows it to generate videos directly from audio cues. This is a direct divergence from traditional models which need a text or image-based prompt to generate videos.
Just a while after Sora by OpenAi, It's been a busy period for the AI space with announcements from Alibaba, Google, Ideogram and lightrick.
— Nova (@Novaprayer_) March 1, 2024
Here are the most important developments that happened:
1. Researchers from alibaba unveiled EMO: Emote Portrait Alive by Alibaba, an AI… pic.twitter.com/AZz5AdiuoH
This method produces extremely expressive and lifelike animations by ensuring smooth frame transitions and constant identity retention.
3) Capturing Intricate Facial Expressions
The ultimate stroke of realism is applied as EMO AI captures all the intricate facial movements consisting of lip and eye movements. The ability to synchronize lip movements with audio cues puts it on the pedestal of Gen AI tools.
The complex and dynamic interaction between aural cues and facial movements is captured by EMO AI. Beyond static expressions, it accommodates a broad range of human emotions and unique facial styles.
AI Videos disrupt HOLLYWOOD
— Poonam Soni (@CodeByPoonam) February 29, 2024
This AI can make any image TALK, SING, even RAP
Here are 10 wild examples of EMO ( Sound on )
1. Leonardo DiCaprio rapping Eminem pic.twitter.com/NVyVEzsugo
Overall, videos including realistic speech and singing in a variety of styles can be produced by this tool. It makes anything come to life, be it beautiful music or a poignant conversation. Imagine being able to transform a static portrait into an animated figure that speaks or sings—EMO makes it feasible!
This is something we need to see whether SORA’s AI Video Generation Tool can do the same.
Looking Into EMO AI’s Build
EMO AI’s architecture is mainly based on Diffusion Models, considering the models’ high capability to produce quality images by training on extensive image datasets. They have gone beyond just image generation and developed realistic video generation by integrating audio with the Diffusion Model.
Additionally, by developing a comparable module called FrameEncoding to maintain the character’s identity throughout the video, they improved and used ReferenceNet’s methodology to guarantee that the character in the output video stays consistent with the input reference image.
Model Training
Researchers assembled a varied audio-video dataset with over 250 hours of footage and 150 million images to train EMO. This dataset includes a variety of content categories, such as talks, multilingual song performances, and film and television snippets. The abundance of content guarantees that EMO records a broad spectrum of facial expressions and vocalization styles, offering a strong basis for its advancement.
The Methodology
The frame encoding phase and the diffusion process are the two primary phases of the EMO framework. ReferenceNet gathers features from the motion frames and reference images during the Frames Encoding phase. A trained audio encoder, integration of the face region mask, and denoising operations made possible by the backbone network are all part of the diffusion process.
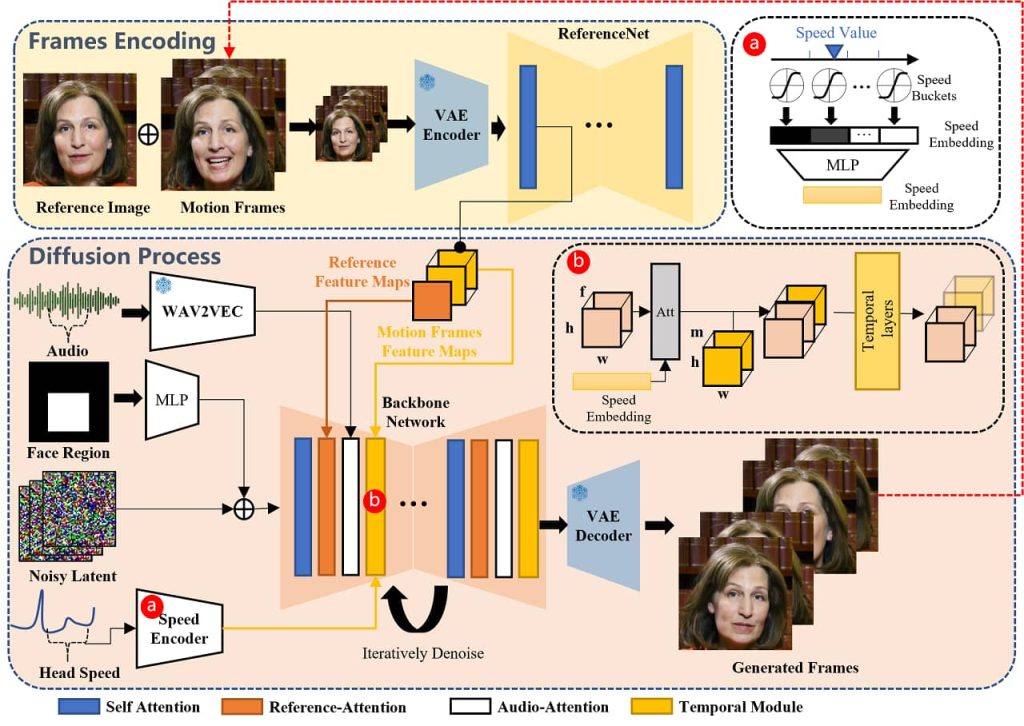
Movements are modulated and identity is preserved via attention processes such as Reference-Attention and Audio-Attention. To create a fluid and expressive video production process, Temporal Modules control the temporal dimension by modifying motion velocity.
By adding a FrameEncoding module to ReferenceNet, EMO improves its methodology while maintaining compatibility with the supplied reference image. This module makes sure the character’s identity is maintained during the creation of the video, which enhances the end product’s realism.
Does EMO’s Workflow Have Any Limitations?
One of the biggest limitations of EMO’s model comes in the form of integration between the diffusion model and the audio cues. This leads to stability issues in the form of noises associated with the audio which may be incorporated as imbalances in the resultant produced video.
To solve stability issues associated with the audio’s noise imbalances, Alibaba researchers have also introduced stable control mechanisms namely a speed controller and a face region controller. These two controllers serve as hyperparameters, providing delicate control signals without sacrificing the final produced videos’ expressiveness or diversity.
One of the other limitations that EMO possesses is using a base video, which can limit realism by causing locked head motions and simply producing mouth movements. Furthermore, the restricted representational capacity of the 3D mesh, which limits the overall expressiveness and realism of the output movies, is a recurring problem with these technologies.
Furthermore, the non-diffusion models on which both approaches are based severely restrict the performance of the results that are produced.
Further in the research paper, it is stated that:
“There are some limitations for our method. First, it is more time-consuming compared to methods that do not rely on diffusion models. Second, since we do not use any explicit control signals to control the character’s motion, it may result in the inadvertent generation of other body parts, such as hands, leading to artifacts in the video. One potential solution to this issue is to employ control signals specifically for the body parts.”
These are a few of the limitations that the current model struggles with, however, it still offers many benefits and improvements in results compared to previous models and approaches.
Improvement Over Other Models
While previous approaches mostly rely on 3D modeling or form blending to mimic facial movement, EMO adopts a more direct approach. It immediately translates voice waves into video frames, producing incredibly lifelike animations that capture each person’s characteristics and peculiarities.
Extensive experiments described in the research paper demonstrate that EMO greatly outperforms existing state-of-the-art systems in terms of identity retention, emotional conveying capabilities, and video quality. EMO-generated videos were praised even in a user study for being more emotive and natural-looking than those produced by competitors.
Below we have obtained a table from EMO’s research paper, where you can see that it outperforms others in terms of individual frame quality, as indicated by improved FID scores:
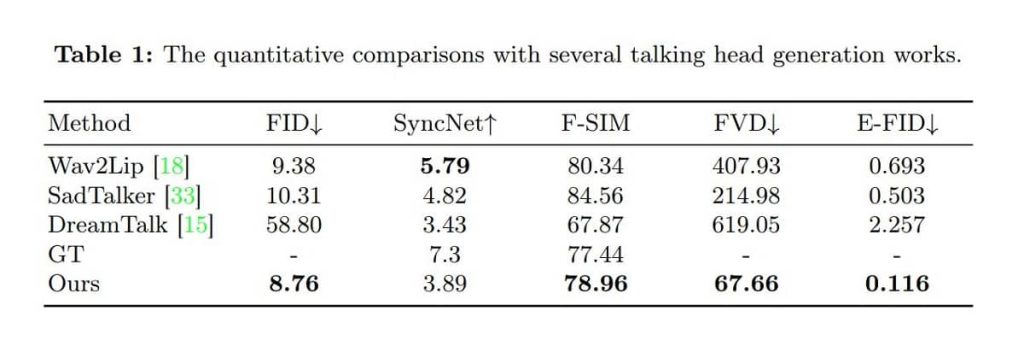
EMO’s model performs exceptionally well at producing dynamic facial expressions, as demonstrated by E-FID, even though it did not receive the highest scores on the SyncNet metric.
A Challenge to OpenAI’s Sora?
Emo’s videos on GitHub also consist of one being used on the AI Lady from Sora. The lady is famous for walking around an AI-generated Tokyo after a rainstorm and can be seen singing Dua Lipa’s “Don’t Start Now”:
This is mind blowing.
— Min Choi (@minchoi) February 28, 2024
This AI can make single image sing, talk, and rap from any audio file expressively! 🤯
Introducing EMO: Emote Portrait Alive by Alibaba.
10 wild examples: 🧵👇
1. AI Lady from Sora singing Dua Lipa pic.twitter.com/CWFJF9vy1M
Although the video has left millions in shock by bringing the lady to life, it’s hard to deduce any conclusions as of now as to which tool is better. Both Sora and EMO have a bit of similar functions but with whole different technologies. We don’t have access to both tools as of now so it’s hard to imagine if EMO’s life-instilling videos with audio cues can outshine Sora’s text-based video content.
We have yet to find out the quality of the content perceived firsthand, so let’s wait and find out. At the same time, we have seen Adobe doing wonders with AI in the audio industry with the Music GenAI Control Project.
Conclusion
Without a doubt, EMO AI has left a major mark in bringing artistry to life and as developers, we can’t wait to get our hands on the model and check it out for ourselves. It does have limitations but clearly, its cutting-edge technology in the form of audio to videos doesn’t fail to impress. We will keep you updated on any latest information regarding EMO’s release and enhancements!




