



AI chatbots have created a great deal of impact with professionals across industries depending on them to do the grunt work. They have so many capabilities and can make our lives much easier if we know how to use them. Data analytics is one such sector where the right use of AI tools like Claude 3 can save users a great deal of time.
Deriving actionable insights is a key part of data analytics. However, it is a tedious and repetitive process that requires multiple steps and the use of a wide variety of libraries like numpy, pandas, spacy and nltk (depending on the type of data of course).
We just discussed how to use Claude 3 for Google Sheets, but what about complete Data Data Analysis? Let’s take a deep dive into that!
Using Claude for Tabular Data
Let’s explore how Claude Opus can help us analyze data in tabular form. For this analysis, we chose a student data CSV file from Kaggle.
The file contains 12 columns spanning student gender, race, grades in core subjects, final GPA, and background information.
Step 1: provide all the information to Claude along with the dataset.
Sample prompt: “Analyze the data provided as a data scientist, and give answers specific to this dataset only. [xyz] column of the data signifies student background and [xyz] column signifies race. Take these feature descriptions into account when analyzing the data.”
Step 2: find the number of categorical and numerical variables
Find the categorical variables and also the unique values of each categorical variable.
Prompt: Which of the following columns are categorical variables and which are numerical?
Output:

Prompt: How many unique values are there in each categorical variable in the data set and what are the values?
Output:
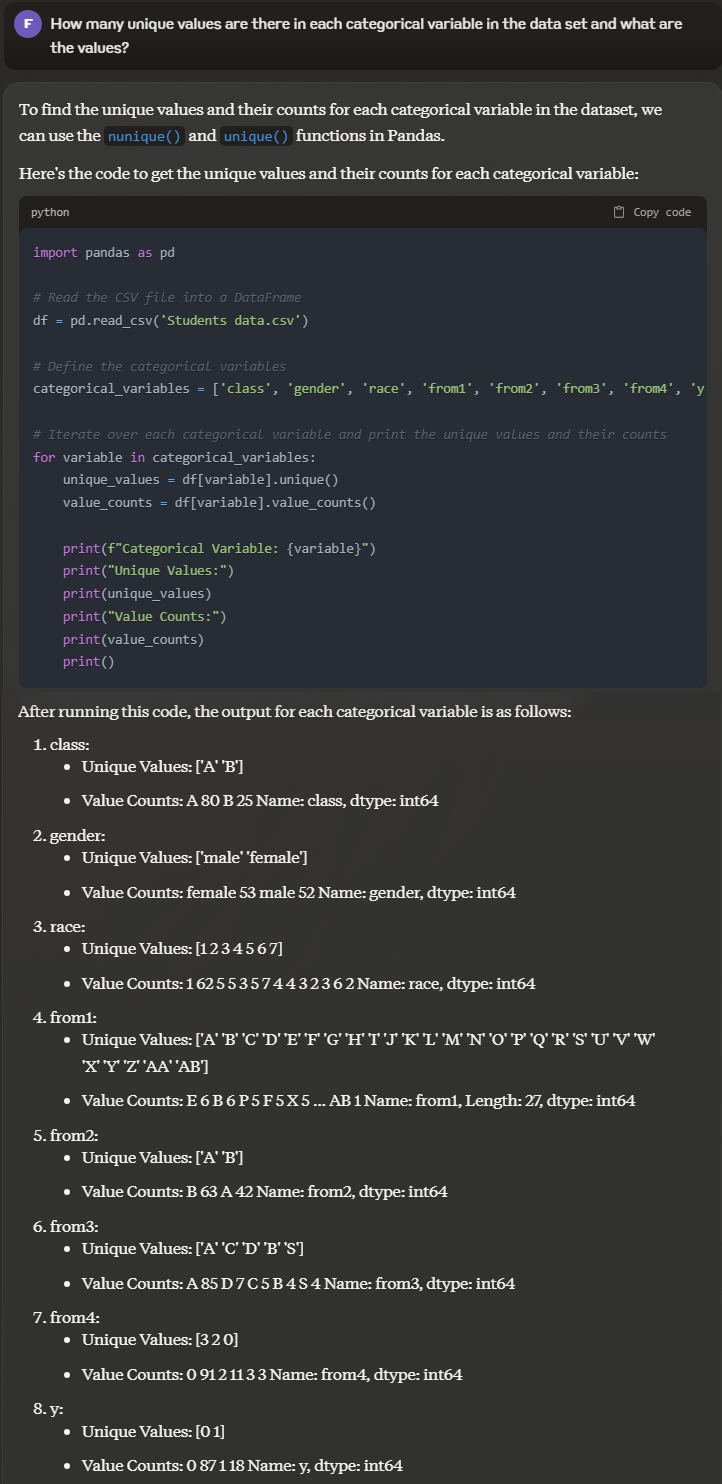
Claude not only gives the list of categorical and numerical variables but also explains the type of data as it is interpreted. It can also provide the list of unique values and the datatype of the column.
Step 3: Data cleaning and finding outliers
The next step in analyzing data is data cleaning. The null values in the data must be counted and dropped, or replaced with mean/median values.
Prompt: which columns have null values and what is the count of those values?
Output:
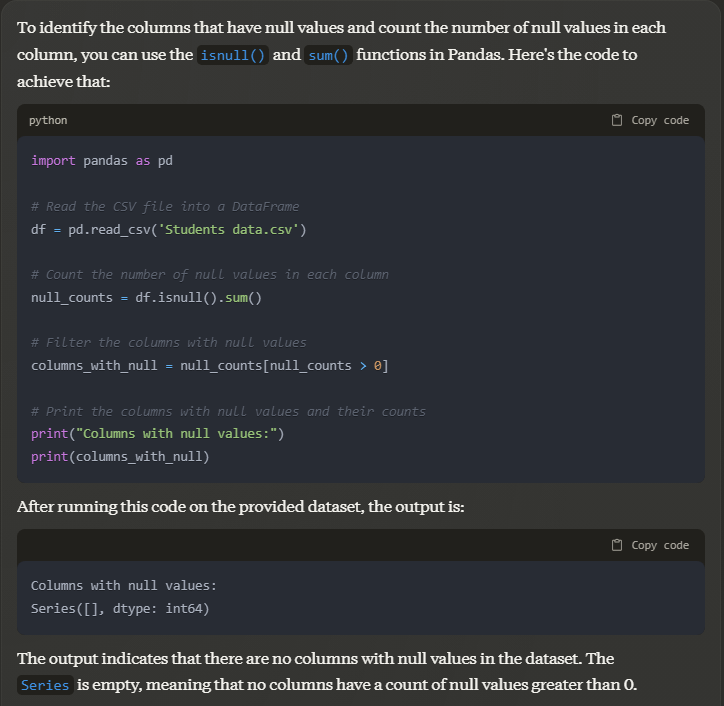
The sample dataset we used has no null values, but if user data does have null values, Claude can handle them by suggesting code to replace or drop the row with the empty cell.
Prompt: tell me the exact columns that have outliers in this dataset. Give specific answers
Output:
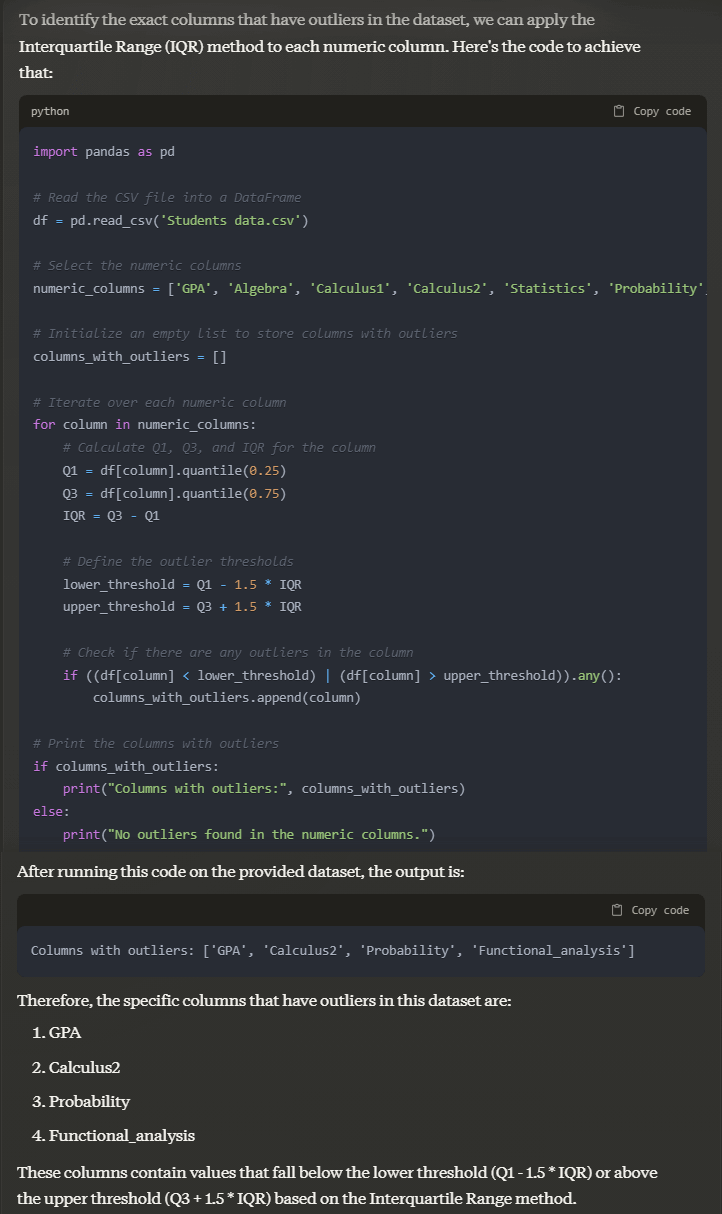
Claude gives a detailed explanation for all its calculations along with the code to verify it for yourself.
Step 4: Mapping relations between variables
Mapping relationships between different features is the best way to visualize data, gain actionable insights, and observe patterns and trends in the data.
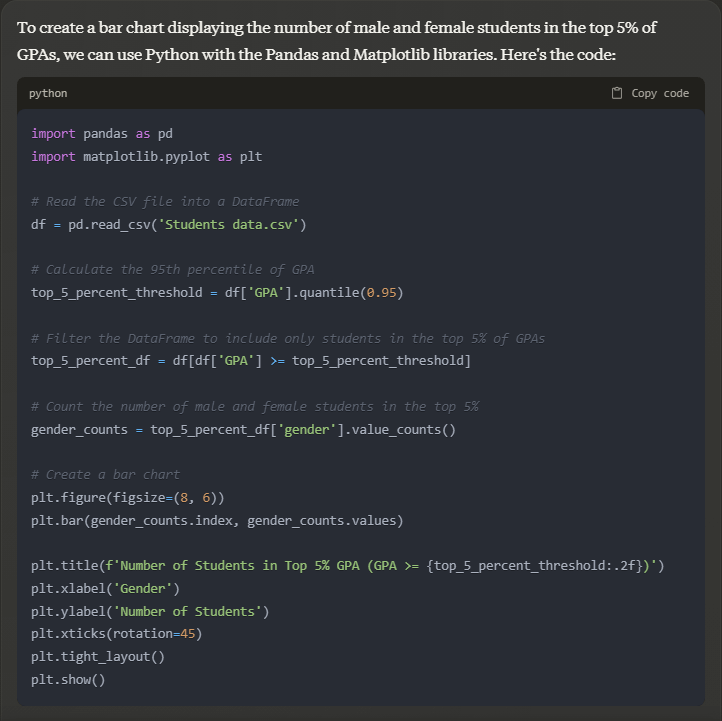
Prompt: please display a bar chart of gender vs number of scorers in the top 5 % GPA
Output:
Prompt: generate a stacked chart showing the gender-wise GPA distribution

The AI assistant provided a detailed working code customized to the dataset and also provided a detailed explanation of all the steps used.
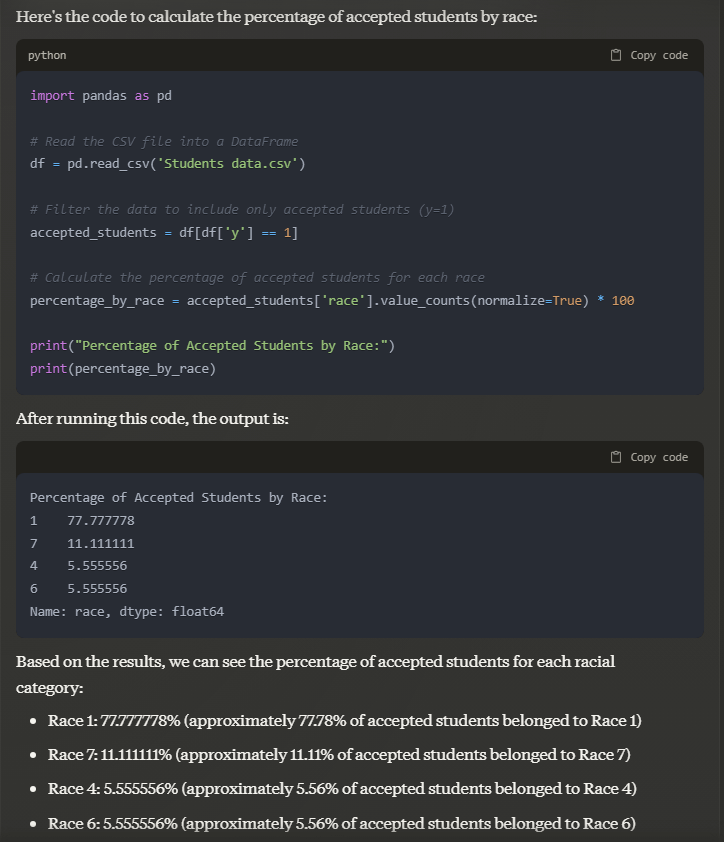
Prompt: what percentage of the accepted students belonged to which race?
Output:
Step 5: Generating insights and trend patterns
Claude can observe and explain the patterns and correlations in the dataset. It can also directly compute the statistical distribution of the features.
Prompt: Derive meaningful insights specific to the dataset provided. Give numerical comparisons wherever necessary ( like in the case of gender and race)
‘
Output:

It provides such a detailed analysis of the dataset with a single prompt, there is barely any need to run codes!
Step 6: Data pre-processing for ML models
The final step in the analysis of this data is to prepare it for a predictive ML or DL model. To prepare the data, correlation matrices need to be found, the appropriate ML model needs to be decided and the independent and dependant variable lists must be formulated.
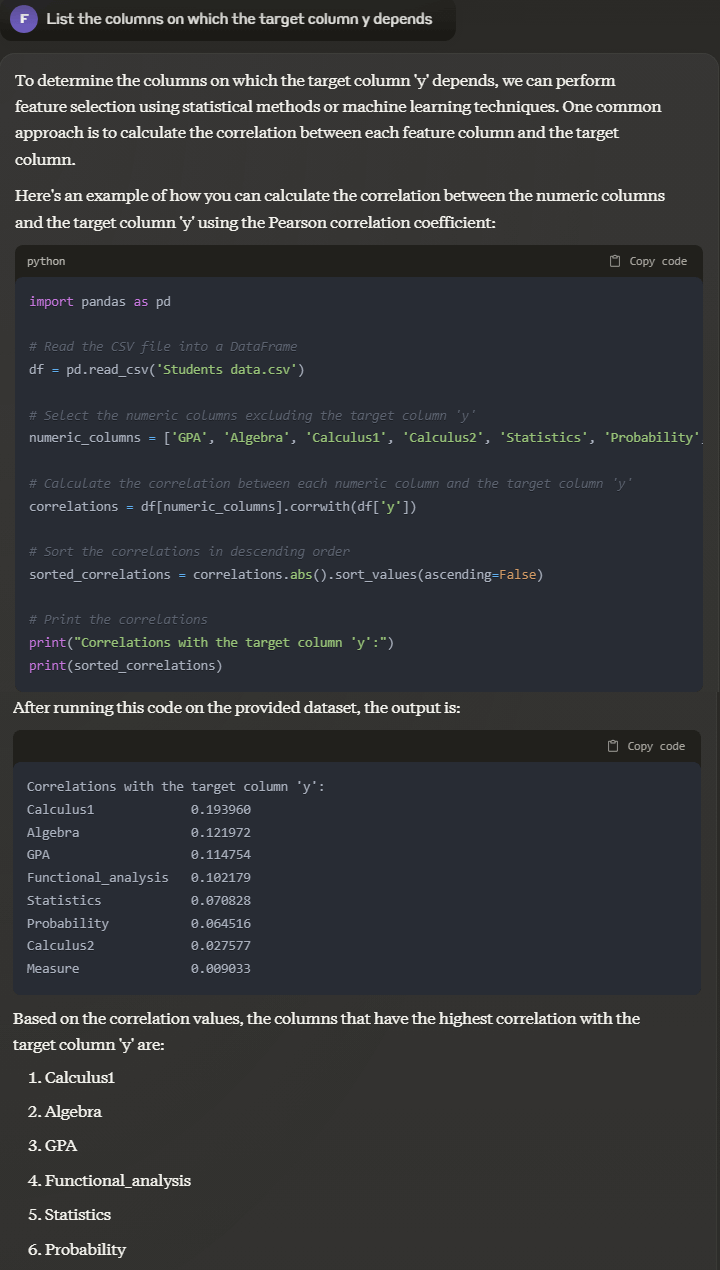
Prompt: List the columns on which the target column y depends
Output:
Prompt: looking at the data distribution, which regression or classification model would be most suitable to predict the target variable y
Output:

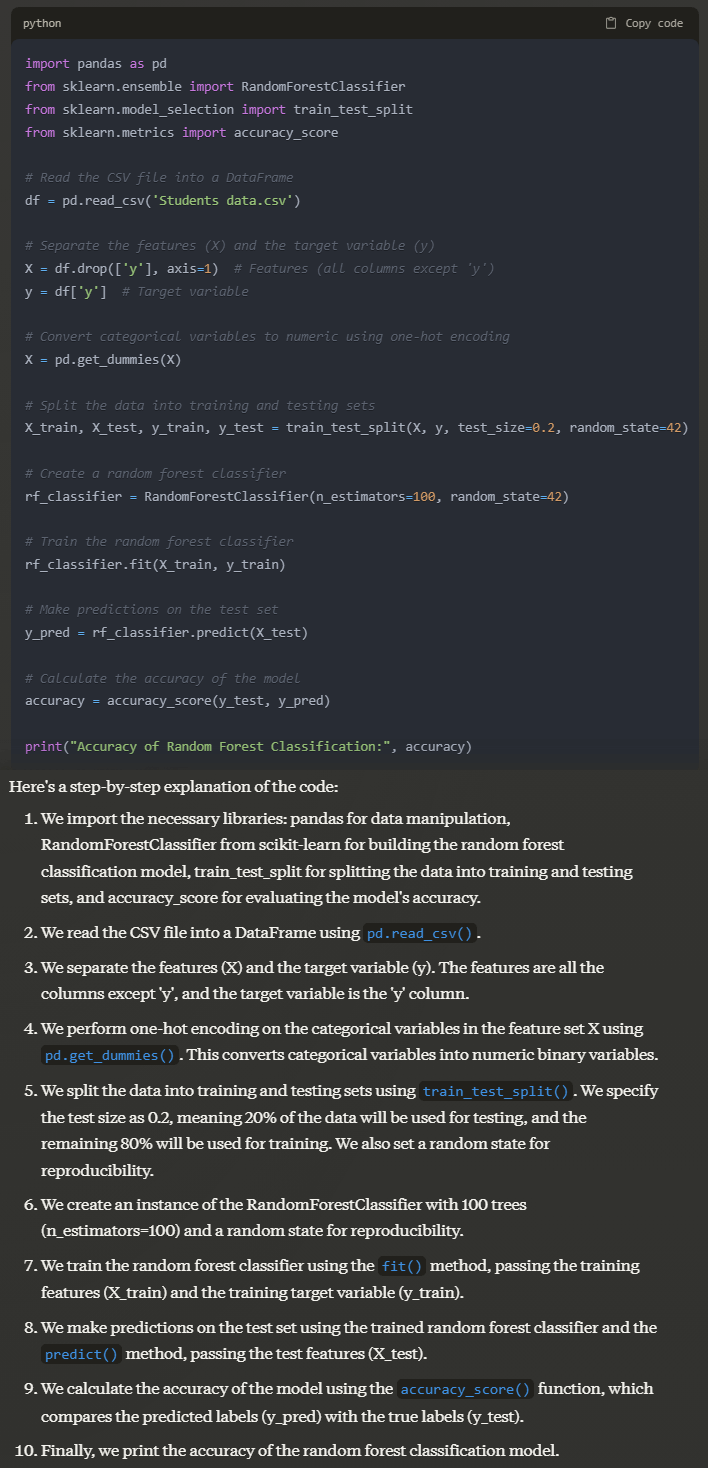
Prompt: Implement random forest classification on the dataset with target variable y and give the accuracy of the model
Output:
Conclusion
Claude has made data analysis so easy that any amateur with little to no knowledge of coding can leverage it for professional use. Experienced data scientists clearly do it better. it gives a starting point for new coders to begin their journey. That in itself is an incredible resource to have for daily use!




