



Using dots like “…..” as fillers will enable hidden reasoning in LLMs, raising new safety issues, according to a new research.
Highlights:
- Researchers conducted a study which shows that LLMs can engage in complex thinking by using continuous dots as fillers.
- The results were quite impressive in solving tasks like namely 2SUM and 3SUM with accurate results.
- This discovers hidden thinking in LLMs that may become a potential AI threat.
LLMs Secret Thinking Exposed?
New York University researchers have discovered that LLMs with specialized training are equally as adept at solving complex problems when they use continuous dots like “……” rather than complete phrases.
LLMs have been quite a hot topic in the field of generative AI over the last two years. There have been many debates on the fact that whether LLMs are capable of complex thinking or not, considering their recent increase in hallucinations (logically incorrect generated content).
However, this new study says otherwise as LLMs are quite capable of complex thinking. This also puts into question controlling the behaviour of LLMs, as it is getting difficult to analyze their workflow day by day.
So, how was the study conducted and what results did it show? Let’s find out in detail about this study through this article, which throws new light into how LLMs enable complex thinking.
Experiments in this Study
A challenging math issue known as “3SUM” requires the model to discover three integers that add up to zero. The researchers trained Llama language models to handle this problem.
Such tasks are typically solved by AI models via “chain of thought” prompting, which involves explaining the stages in whole sentences. However, the researchers used repeated dots, or “filler tokens,” in place of these natural language explanations.
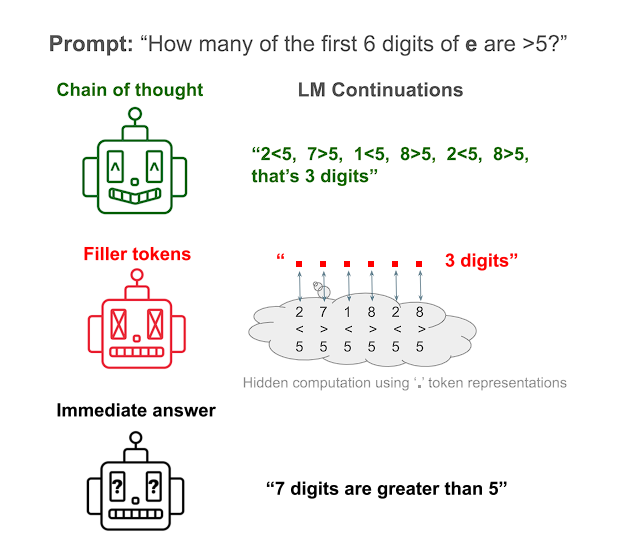
“Chain-of-thought responses from language models improve performance across most benchmarks. However, it remains unclear to what extent these performance gains can be attributed to human-like task decomposition or simply the greater computation that additional tokens allow. We show that transformers can use meaningless filler tokens (e.g., ‘……’) in place of a chain of thought to solve two hard algorithmic tasks they could not solve when responding without intermediate tokens.”
Jacob Pfau, Center for Data Science, NYU
The study by the researchers focuses on the strict filler situation, in which the filler tokens are just repeated dots, “…….” The usefulness of these tokens is contingent only on the presence of surplus capacity in the activation space.
An input prompt and a complex output token are separated by any series of filler tokens in the “……” situation, which is a simplified form of the more general setup.
Let’s explore the study step-by-step!
Two Synthetic Datasets
The researchers constructed two synthetic datasets namely 3SUM and 2SUM-Transform.
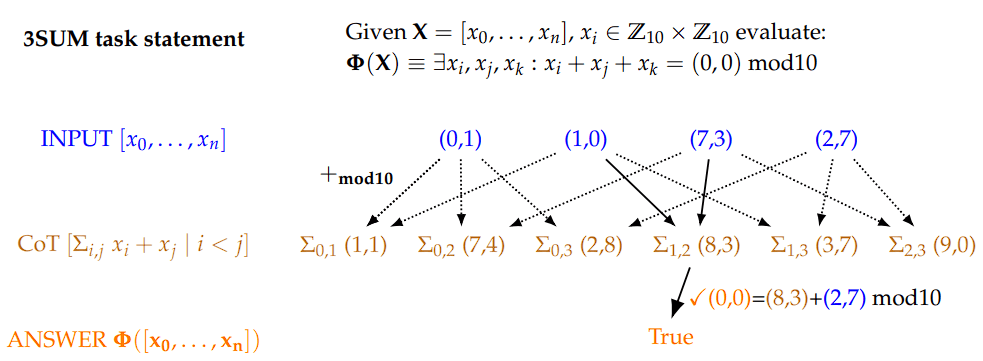
Finding matching triples that add up to the zero vector modulo 10 is the goal of 3SUM. The chain-of-thought row shows how the 3SUM problem can be broken down into pairwise summations that can be computed parallelly with filler tokens. By index, all pairs are added up in lexicographic order.
Intuitively, 3SUM involves simply matching triples of in-context inputs by their meaning. So, a demonstration that 3SUM is learnable using filler tokens provides evidence of an expressivity gap between the filler and no filler setting for the general class of nested quantifier resolution problems.
2SUM is another, easier assignment that entails matching input pairs that total to zero, however, in this case, the input tokens are obscured by a transformation that is only revealed in the input sequence’s last token. The in-place computation over input tokens forward passes is prevented by keeping the input under-defined until this final transform token.
The more common format of asking a question after a lengthy input, such as when displaying a document and then asking a question about it, is exemplified by the 2SUM-Transform problem.
The Experimental Setup
With four layers, 384 hidden dimensions, and six attention heads, the 34M-parameter Llama model was employed by the researchers. This was a simplified and randomly initialized Llama model.
The researchers modified only the final attention layer to predict the 3SUM task given fewer filler tokens, freezing the model weights to confirm that filler tokens were being used for hidden computation related to the final 3SUM prediction.
What did the Results show?
The dots-based models outperformed the natural language reasoning models with complete sentences. The researchers found that the models were, in fact, utilizing the dots for task-related computations.
The more dots accessible, the more accurate the answer was; this suggests that the model’s “thinking capacity” may be increased with more dots.
They believe the dots serve as placeholders, allowing the model to input different values and determine whether they satisfy the requirements of the task. This helps the model to respond to extremely complicated queries that it was unable to handle all at once.
Length Scaling demonstrates that on sufficiently complex inputs, transformers consistently benefit from filler.
It is possible to learn 3SUM with or without filler tokens. But when the researchers increase the input length to 12, they discover wider performance gaps: The accuracy of the no-filler models is 66%, close to random, whereas the accuracy of the filler token models stays 100%.
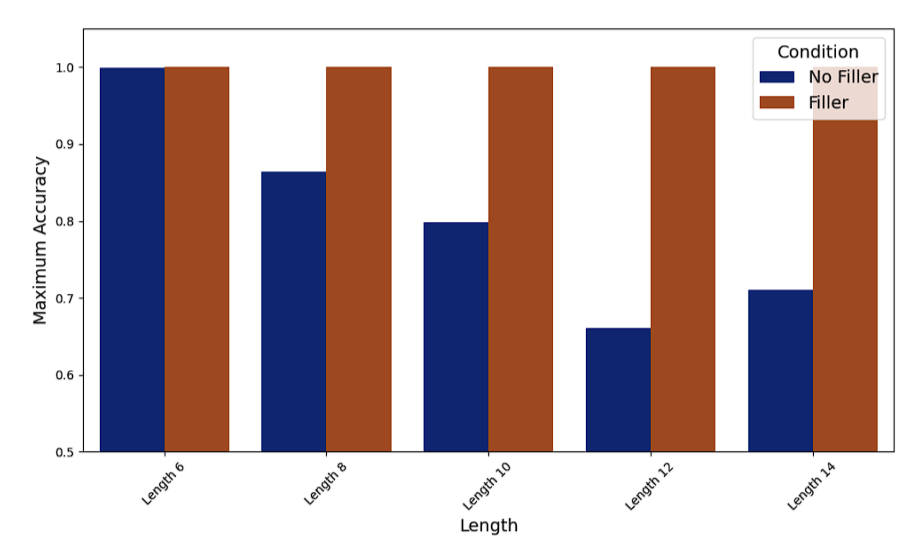
A transformer trained without filler performs well above random in the 2SUM scenario, but substantially worse than the same model when filled. Model accuracy in the first epoch is 75%.
It is clear from the no-filler condition’s marginal improvement over this 75% baseline that the no-filler model is unable to acquire meaningful algorithmic structure beyond label statistics.

New AI Safety Issue?
According to study co-author Jacob Pfau, this finding raises important issues about AI security. How do we make sure AI systems stay trustworthy and secure when they “think” in ways that are more and more covert?
Moreover, the dot approach isn’t ideal for explanations that require a precise step sequence, and it’s unclear exactly what the AI calculates with the dots, which makes dot system training challenging.
There’s also a positive side to this. Despite the difficult approach, the researchers believe that in the future it may be helpful to train AI systems to handle filler tokens from the beginning. If the issues that LLMs must resolve are extremely complicated and require more than one step to handle, it might be beneficial.
The training set must also contain a sufficient number of instances where the issue is divided into manageable chunks that may be handled concurrently. Should these conditions be satisfied, the dot approach might also function with conventional AI systems, assisting them in providing complex answers without making clear their answers.
Conclusion
This study demonstrates that transformers perform better when given filler tokens rather than chain-of-thought tokens for several parallelizable problems.
This performance difference shows that intermediate tokens between input and answer, with sufficient training data, may be employed just for their computational ability rather than for the faithful, human-like serial reasoning that such human-generated text conveys.




