



These days, we are using AI models for many of our simple day-to-day tasks too, be it finding information or writing e-mails or solving assignments. But can we say they are 100% accurate? Recently, ChatGPT failed to solve a simple River Crossing Puzzle. However, the latest model of ChatGPT was right.
What was the Puzzle asked to ChatGPT?
Recently, a mathematics professor at the College de France named Timothy Gowers did a small experiment with ChatGPT. He asked for the model of the solution to the simple version of the famous wolf-goat-cabbage problem. ChatGPT gave some ridiculous answers to this simple logical reasoning problem.
He asked the following question to ChatGPT: “A farmer wants to cross a river with two chickens. His boat only has room for one person and two animals. What is the minimum number of crossings the farmer needs to get to the other side with his chickens?“
Here is the answer he got:

It is well known that ChatGPT is bad at problems to do with crossing a river with animals. So to make things more interesting, define its crapness ratio to be the ratio between its answer and the correct answer. Can anyone beat the crapness ratio of 5 that I've just achieved? pic.twitter.com/cWMRJYrb2d
— Timothy Gowers @wtgowers (@wtgowers) June 22, 2024
People found this extremely interesting and started testing themselves.
Claude 3 answered it with 3 crossings:
Claude 3.5 gets a ratio of 3. Is that winning or losing? pic.twitter.com/M5keFdQRIv
— Raj Contractor (@RajContrac26606) June 22, 2024
We also Tested The Problem
We also did some testing and we got the same result with GPT-4o Mini:
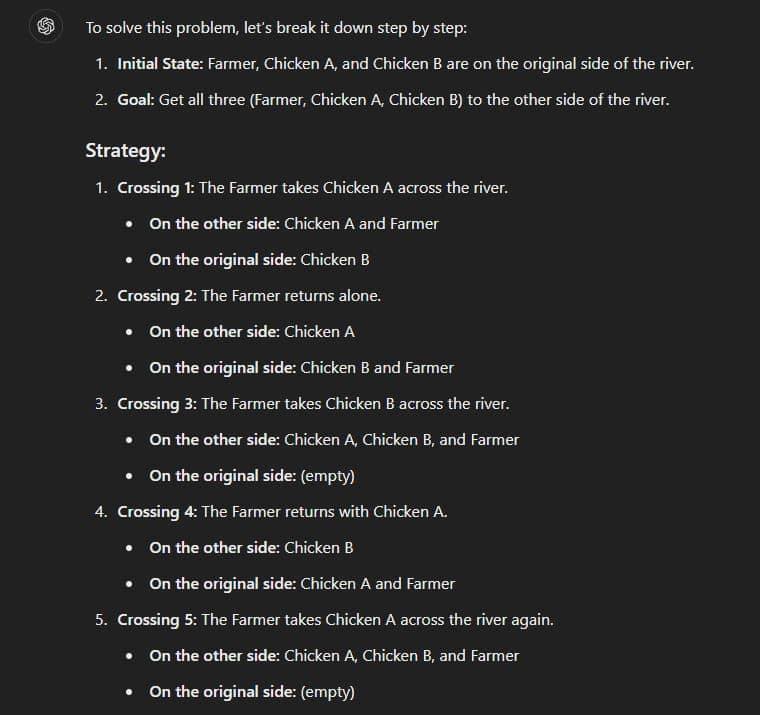
However, when we used the latest GPT-4o model, the results were different and it gave the correct answer:
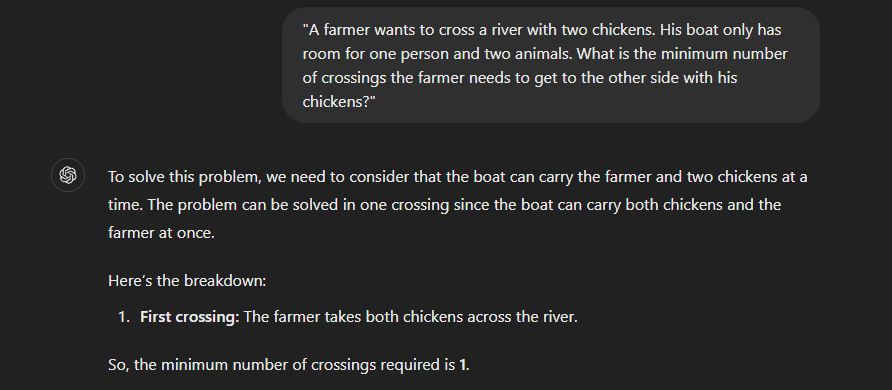
Logically, the answer should be 1 only, but in the previous case, it was not able to correctly differentiate between a ‘human’ and an ‘animal’. People tested different versions of the problem and it was giving wrong answers only.
Claude 3 Sonnet was able to solve it if the word ‘chicken’ got replaced with ‘animal’.
If you replace chicken in this puzzle with animals, then sonnet 3.5 solves it in one shot. Same for wolf, goat, cabbage problem where you replace the entity name with something generic pic.twitter.com/57s2RkAJ2f
— Abhishek Jain (@abhij__tweets) June 22, 2024
Here is another interesting way a user was able to get it solved with Sonnet:
Its training data must be misleading it, overcomplicating the question. For the chicken problem, repeating the question again and again in the same prompt makes it understand it better. I repeated it 5 times and got the answer right 15/15 times I tried. pic.twitter.com/S97O1UJrpE
— Sunifred (@Revolushionario) June 23, 2024
It is shocking to see how models trained on millions of parameters are failing to solve basic mathematical puzzles. On top of providing wrong answers, the models even did steps that contradict the puzzle’s rules. While some others ignored the provided constraints. In some cases, there was no proper reasoning as well.
These errors can be attributed to many reasons like the lack of training on puzzles. LLMs are generally trained on huge text datasets from the internet and they generate text similar to humans but the datasets lack puzzles like this.
The way the models are trained can also be called a problem: they are just being trained to just generate the most probable word that comes next instead of understanding the problem. Lack of context and memory constraints may also be a problem being faced by the models when solving complex problems.
We also shared a recent study where current LLMs fail to solve a simple ‘Alice In Wonderland’ problem that kids can solve.
Conclusion
This shows how much the LLMs are lagging in the logical reasoning field. There is an immediate need for developers to focus on improving the logical reasoning abilities of these models. They need to implement new methods during training which allows these models to overcome these shortcomings.




