



AI Models can do anything but will they be able to do the same forever? A new study re-emphasized our attention on the concept of “model collapse” which will be a big challenge for how AI models will be trained.
Highlights:
- Researchers tried training AI models recursively on the text generated by itself.
- They found out that AI models may start returning gibberish after 9-10 iterations.
- This proves that using synthetic data for training LLMs may not be a good idea.
AI has a ‘Model Collapse’ problem
Researchers from the University of Cambridge and Oxford have recently published a study that shows how AI models collapse when trained on data generated by other AI systems. By collapse, we mean the output generated will be of low quality and sometimes incorrect.
This study is significant because many big tech companies like Microsoft, OpenAI and Cohere are planning to train their LLMs on a lot of different data from the internet. We also know a lot of current information on websites is already getting written with AI. So, if the new AI model is getting trained on the same data generated by its predecessor, it will be a problem.
The degradation in the quality of outputs generated by AI when it is trained on AI-generated data is called Model Collapse.
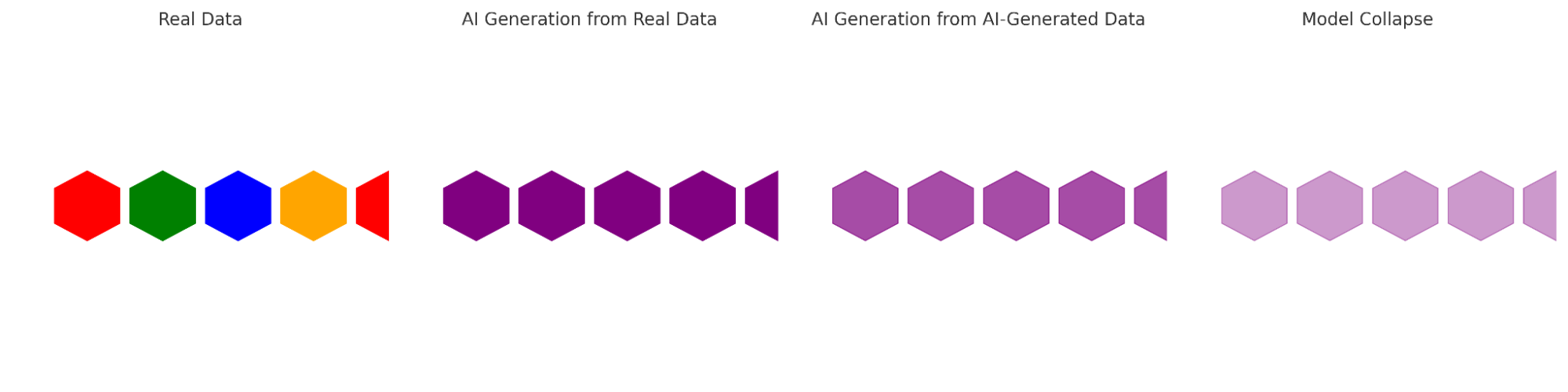
If you look at the above image, you can see how colourful the real data is – the colours indicate the diversity of the dataset. When AI generates data from the original data itself, the diversity is reduced. Slowly the color fades and at the end, the model collapses completely.
To understand this in more simple terms, think of this as the telephone game (Chinese Whispers) we used to play in our childhood. A huge group of children seated in a circle, keep on passing the message by whispering the words in each other’s ears. By the end of the game, all the words get lost and the last child replies with something gibberish that has no relation to the original message.
This is exactly what is happening with the AI models right now. The models lose their ability to accurately understand and process information after a while if they are being trained on synthetic data that lacks diversity.
One Example on How It Happens
The researchers conducted several experiments and published their findings in the paper. In one of the experiments, they gave the model a large prompt about the history of building churches. They trained the model repeatedly on the output generated by itself. After several iterations, this is what the output was:
“architecture. In addition to being home to some of the world’s largest populations of black @-@ tailed jackrabbits, white @-@ tailed jackrabbits, blue @-@ tailed jackrabbits, red @-@ tailed jackrabbits, yellow @-.”
This happens because AI slowly forgets bits and pieces of information from its initial prompt. After several generations, it is left with almost little data which forces it to return gibberish.
How to overcome this problem?
The first solution proposed is Watermarks. These are digital signatures embedded in the data which helps people to detect AI-generated data and remove it from training datasets. This method has been approved by all the major companies but it is still a challenge as some companies may not comply.
Other solutions include sticking to using the human-generated data even though it may be expensive because they will always give better results than other methods.
That’s why these tech giants are making deals with news websites and social media platforms so that they can receive human-written content regularly to train their models. That’s why they have to pay them heavily because otherwise, most news websites are blocking AI crawlers.
Conclusion
Acquiring high-quality human-written data is becoming more challenging and expensive for companies. But they can’t this ‘model collapse’ problem. So, now they need to start looking for more solutions to this problem.




