



AI is smart and some people think it will be smarter than humans one day with the coming of AGI. But sometimes it can even struggle to solve a basic problem that even elementary-level children can. Let’s discuss this new study that finds current AI models baffled!
Highlights:
- Research shows that current powerful LLMs fail to solve a simple ‘Alice In Wonderland’ problem that kids can solve.
- The models not only provided incorrect responses, they also blatantly tried to justify their incorrect reasonings.
- GPT-4o performed better than other models like Claude 3, Mistral Medium and many more.
Latest AI Models Can’t Solve ‘Alice in Wonderland’ Problem
Researchers from the Jülich Supercomputing Centre, the AI lab LAION, and other organizations have discovered significant errors in the reasoning behind modern AI models using a simple text task.
This new study showed that current powerful LLMs fails when drawing simple logical conclusions when they gave incorrect responses for a simple elementary-level puzzle. This is quite an important experiment that throws light on the vulnerability aspect of LLMs.
GPT-3.5/4/4o, Claude 3 Opus, Google Gemini, and open-weight ones like Llama 2/3 (Meta), Mistral, and Mixtral (Mistral AI), including very recent Dbrx by Mosaic and Command R+ by Cohere were the LLMs used for this experiment.
The researchers asked these LLMs a very simple question. “Alice has N brothers and she also has M sisters. How many sisters does Alice’s brother have?”.
The problem features a fictional female person (as hinted by the “she” pronoun) called Alice, providing clear statements about her number of brothers and sisters, and asking a clear question to determine the number of sisters a brother of Alice has.
Alice plus her sisters, or M + 1, is the correct answer to the problem. The siblings’ order in the text and the values of N and M were changed by the researchers.
However, when the researchers ran the question to all these LLMs, they witnessed quite a breakdown showing an inability to answer this question. They were not able to answer in one go, even when different types of prompts were given.
Not only this, but the models even provided reasonings to additionally explain the provided final answer, mimicking a reasoning-like tone. The breakdown appears dramatic because the models continue to produce more nonsense, frequently in longer and occasionally more entertaining forms.
Analyzing The LLMs’ Breakdown
Initially, the researchers thought that the ‘Alice in Wonderland’ problem would pose no problem for the current state-of-the-art LLMs.
However, all of the LLMs faced huge difficulty when answering this question. This can be mainly attributed to the fact that the models mainly relied on attempting to execute various basic arithmetical operations on the numbers mentioned in the problem to arrive at a final answer.
This meant that the likelihood of getting a correct answer depended on how likely it was to perform a few random, easy calculations, such as additions or multiplications using numbers from the problem text, which could also unintentionally produce a correct answer even though the process didn’t follow proper logic.
One big question here is why would LLMs follow up with this approach of using numerical logic. One simple answer is that they have been programmed that way. The way an LLM operates mainly depends on its architecture and knowledge base, and we have seen before how mere numbers in a prompt can change the way it operates.
A few days ago we saw a similar experiment where these models showed pre-existent biases towards a few numbers when they were asked to choose from a few.
What did the Results show?
When the researchers analyzed the model’s responses they found that Claude 3 Opus and GPT-4 are notable outliers, as they can occasionally produce accurate answers supported by sound logic, as seen by the organized, step-by-step explanations and solutions such models provide.
Claude 3 Opus and GPT-4, however, continue to repeatedly fail to fix this straightforward issue during trials.
The success rate with Claude 3 Opus and GPT-4 varied greatly depending on the exact wording of the prompt. With extremely few right answers, a harsher version of the problem (AIW+) nearly took even the finest models, Mistral Medium, GPT-4, and Claude 3 Opus, to the verge of complete mental collapse.
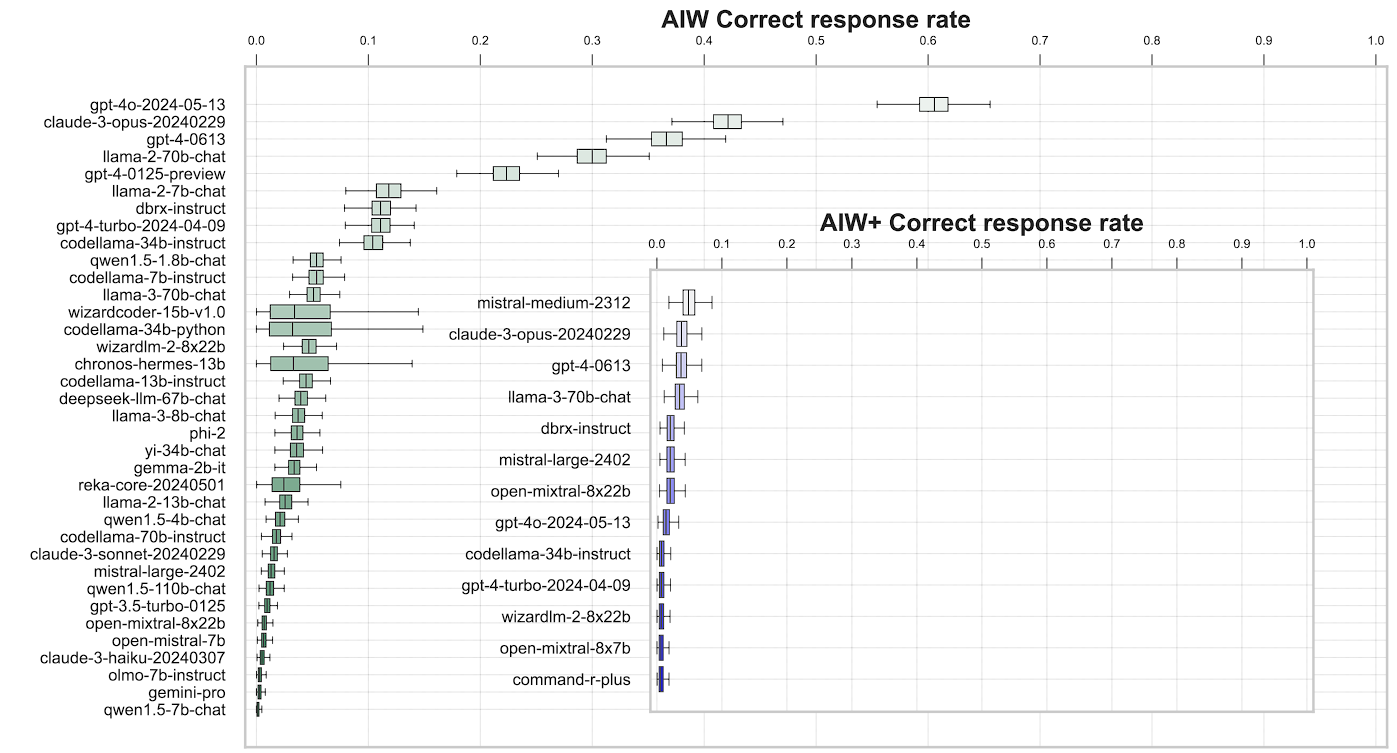
All things considered, the language models’ average percentage of right answers was significantly lower than 50%. GPT-40 was the only test that outperformed chance, with 0.6 right answers. It was quite surprising to see Google Gemini, Open Mixtral, and Claude 3 Haiku so down the list.
Conclusion
We can say the outcomes are unsatisfactory: the majority of models either failed to complete the task or only partially succeeded. Various prompt techniques did not alter the fundamental outcome. So, another experiment showed us that LLMs still have many issues as they hallucinate even for a simple riddle that elementary school kids can solve.




