



Meta’s latest Llama 3 open-source model release has exceeded all expectations, beating top-of-the-line models on industry benchmarks. Developers are also testing Llama 3 and checking it from various perspectives. But how to access Llama 3 to test it for yourself??
For normal users, Meta AI Assistant has integrated Llama 3 into their social media applications: Instagram, WhatsApp, and Facebook. It can also be accessed through the Meta AI web interface if available in your country.
For developers wishing to incorporate Llama 3 for their applications, Llama 3 can be accessed in two ways:
- The model can be run locally by downloading the model weights/ quantized files from official sources like meta webpage, GitHub, Huggingface, or Ollama and running it on your local machine.
- It can also be accessed through APIs on authorized sites like Replicate, Huggingface or Kaggle.
Which models to choose in the Llama 3 family:
There are four variant Llama 3 models, each with their strengths. Llama 3 comes in two parameter sizes: 70 billion and 8 billion, with both base and chat-tuned models.
- meta-llama-3-70b-instruct: 70 billion parameter model fine-tuned on chat completions. If you want to build a chatbot with the best accuracy, this is the one to use.
- meta-llama-3-8b-instruct: 8 billion parameter model fine-tuned on chat completions. Use this if you’re building a chatbot and would prefer it to be faster and cheaper at the expense of accuracy.
- meta-llama-3-70b: 70 billion parameter base model. This is the 70 billion parameter model before the instruction tuning on chat completions.
- meta-llama-3-8b: 8 billion parameter base model. This is the 8 billion parameter model before the instruction tuning on chat completions.
Let’s take a detailed look at the methods to access these models!
1) Locally Run Llama 3
Pretrained model weights can be downloaded to run large models on your local systems. These model weights can be downloaded only by requesting access to Meta AI
a) Official Site
Downloading models through the official site:
Through this webpage, users can access the files by entering their details, and Meta can accept or reject applications.
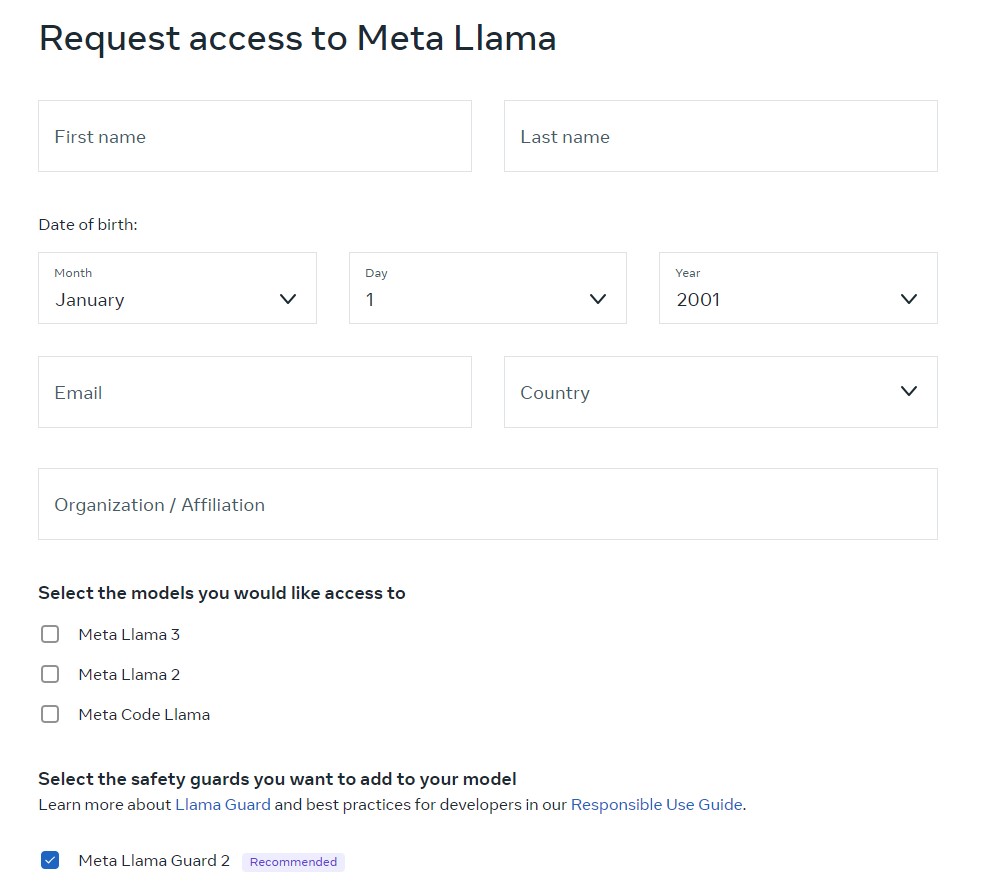
Users have to then agree to the Meta terms and conditions including the acceptable use policy.


b) Hugging Face
The model can also be downloaded from Huggingface Hub:
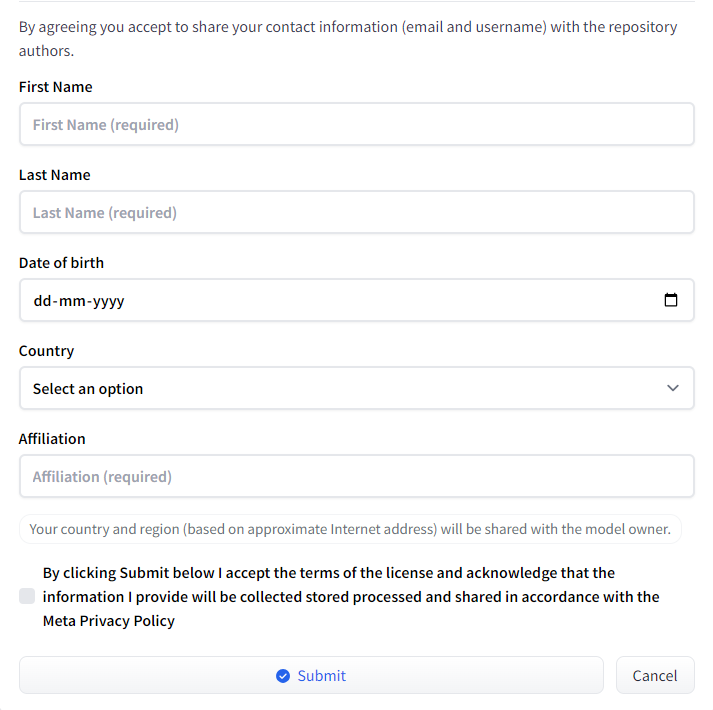
Once your request is approved, you can access the repository and download the weights.

c) Ollama Platform
For Linux/MacOS users, Ollama is the best choice to locally run LLMs. Ollama now llama 3 models as a part of its library.
Here are two commands to run Llama 3 in Ollama’s library platform:
CLI
Open the terminal and run this code:
ollama run llama3API
Example using curl:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"Why is the sky blue?"
}'Instruct is fine-tuned for chat/dialogue use cases.
Example:
ollama run llama3 ollama run llama3:70bPre-trained is the base model.
Example:
ollama run llama3:text ollama run llama3:70b-text2) Running Llama 3 through APIs
Llama-3 is hosted on several websites like Hugging Face Hub, Kaggle, and Replicate.
a) Hugging Face
The huggingface repository contains two versions of Meta-Llama-3-70B-Instruct, for use with transformers and with the original llama3 codebase.
mport transformers
import torch
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])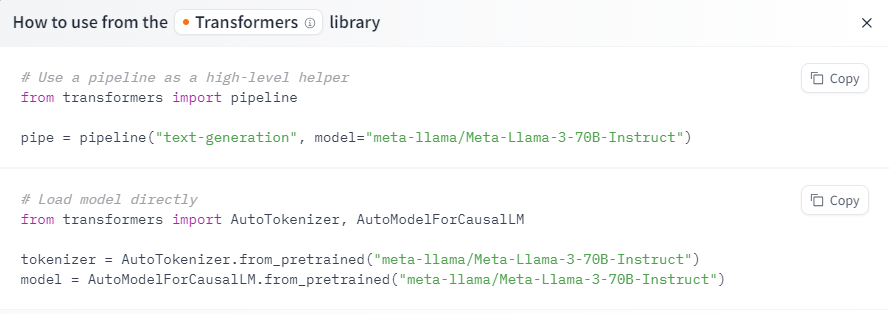
b) Kaggle
The Llama-3 model can be accessed through Kaggle by verifying the access provided on the official meta page.
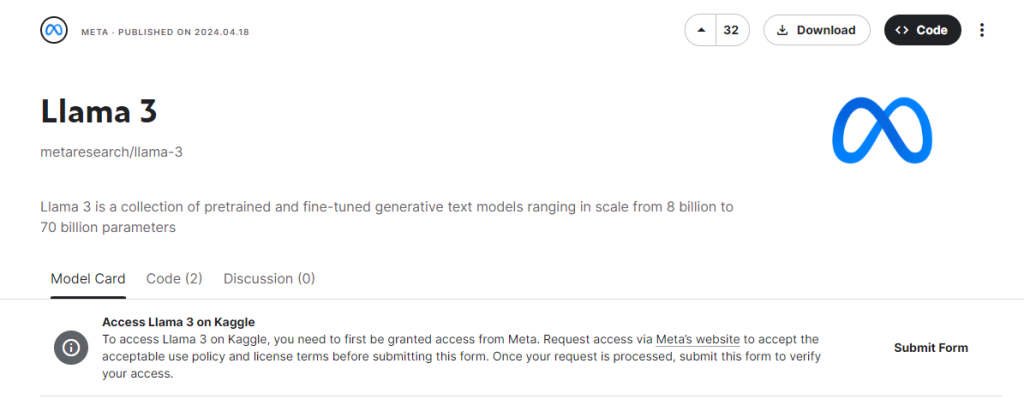
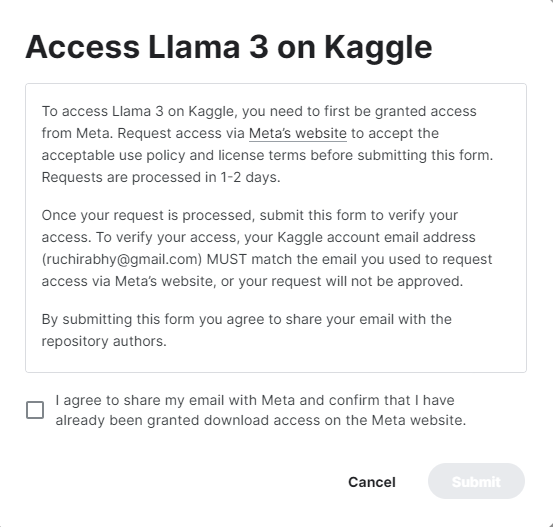
Once access is granted, users can load the model into either Kaggle or any other notebook using
“model = "/kaggle/input/llama-3/transformers/8b-chat-hf/1"
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
c) Replicate
Developers can access the model through the replicate API using their replicate API token in Python, JavaScript, or cURL libraries.
For python,
Install Replicate’s Python client library:
pip install replicateSet the REPLICATE_API_TOKEN environment variable:
export REPLICATE_API_TOKEN=r8_I11**********************************Import the client:
import replicate
# The meta/meta-llama-3-70b-instruct model can stream output as it's running.
for event in replicate.stream(
"meta/meta-llama-3-70b-instruct",
input={
"prompt": "Can you write a poem about open source machine learning?"
},
):
print(str(event), end="")For JavaScript:
Install Replicate’s Node.js client library:
npm install replicateSet the REPLICATE_API_TOKEN environment variable:
export REPLICATE_API_TOKEN=r8_I11**********************************This is your Default API token. Keep it to yourself.
Import and set up the client:
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});For cURL,
Set the REPLICATE_API_TOKEN environment variable:
export REPLICATE_API_TOKEN=r8_I11**********************************Run meta/meta-llama-3-70b-instruct using Replicate’s API.
$ curl -s -X POST \
-H "Authorization: Bearer $REPLICATE_API_TOKEN" \
-H "Content-Type: application/json" \
-d $'{
"input": {
"prompt": "Can you write a poem about open source machine learning?"
}
}' \
https://api.replicate.com/v1/models/meta/meta-llama-3-70b-instruct/predictions
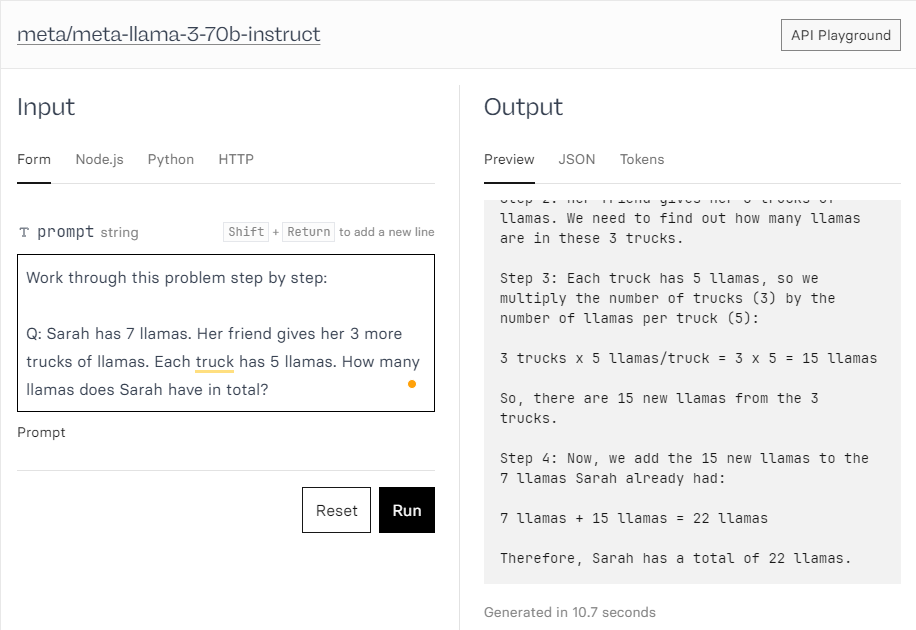
The model can be tested for different prompts in the AI playground as well:
d) Other cloud platforms
Llama-3 is hosted on several other cloud platforms like Vertex AI, Azure AI, and Cloudflare Workers AI.
Meta Llama 3 is available on Vertex AI Model Garden. Like its predecessors, Llama 3 is freely licensed for research as well as many commercial applications. Llama 3 is available in two sizes, 8B and 70B, as both a pre-trained and instruction fine-tuned model.
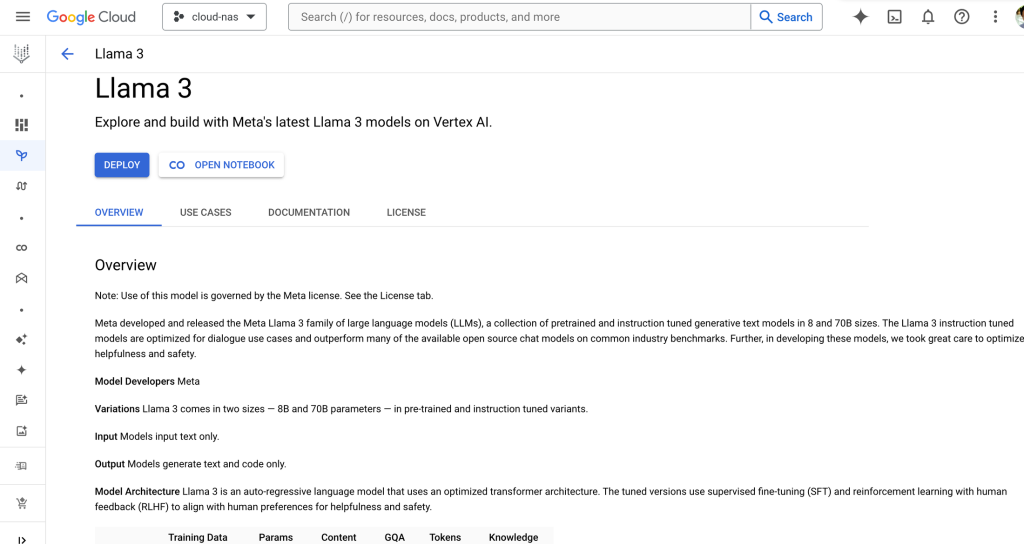
To start building, click on “open notebook”
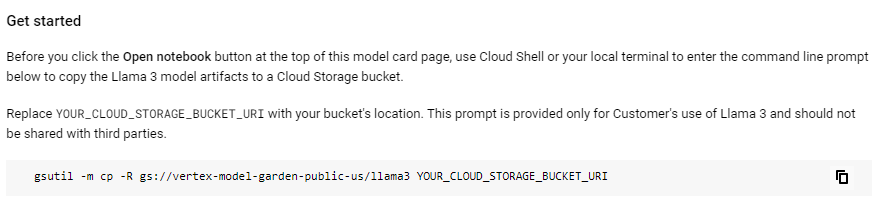
Here’s the code mentioned above.
“gsutil -m cp -R gs://vertex-model-garden-public-us/llama3 YOUR_CLOUD_STORAGE_BUCKET_URL”The model is available in the catalogue of Azure AI as well and is supported by integration platforms like Langchain.
Conclusion
There are a large number of platforms hosting Llama-3 and developers can select the one best suited to their application. For low-cost local applications, free API calls might be the best approach, and for large quantities of data, cloud-based applications might be more suited. There is an option for everyone, so happy coding!




