


Have you ever wondered how Uber, the ride-hailing giant, manages to handle millions of logs every second without breaking a sweat? Well, buckle up, because Today we’re diving deep into the nitty-gritty of Uber’s logging infrastructure overhaul, which saw them switch to the open-source, high-performance OLAP database, ClickHouse.
If you are wondering what’s “OLAP” or you’ve never heard of the ClickHouse database, worry not! I will dive into what the term “OLAP” means, what the ClickHouse database is, and how Uber uses this open-source technology today as a critical component of their logging infrastructure.
But, wait a minute. Before we dive deep into why Uber is using the ClickHouse database, we first need to understand why Uber even considered using such a technology in the first place. What problems were they facing before switching to the ClickHouse database?
The Logging Conundrum
As Uber scaled over the years, their logging requirements skyrocketed. They were collecting logs from thousands of microservices, amounting to hundreds of terabytes every day. These logs are not just a record of events; they’re the backbone of real-time debugging, troubleshooting, and analytics. But with great scale comes great challenges.
Uber initially used ElasticSearch (ES) for their logging needs, but they ran into several roadblocks:
- Developer Productivity: ElasticSearch requires a consistent schema per index, which is a nightmare when your logs have wildly varying structures. Any change in the log schema led to type conflicts, causing indexing issues and data loss.
- Performance: High ingestion latency and poor query performance were major pain points. Large indices took over two minutes to index, and complex queries could render the cluster unresponsive.
- Scalability: As Uber’s logging volume grew, the operational challenges of running multiple ES clusters became apparent. High costs, JVM heap lockups, and general reliability issues made it clear that ElasticSearch wasn’t going to cut it in the long run.
Enter ClickHouse!
So, why did Uber choose ClickHouse? This open-source, distributed, high-performance columnar DBMS checked all the right boxes for their logging needs. Let’s break down the reasons:
High Throughput Ingestion
ClickHouse’s architecture allows for high throughput ingestion with asynchronous segment merging, meaning no locks during concurrent writes. This was a massive upgrade from ES, providing 3-4x the write throughput and scaling linearly with cluster size.
Blazing Fast Queries
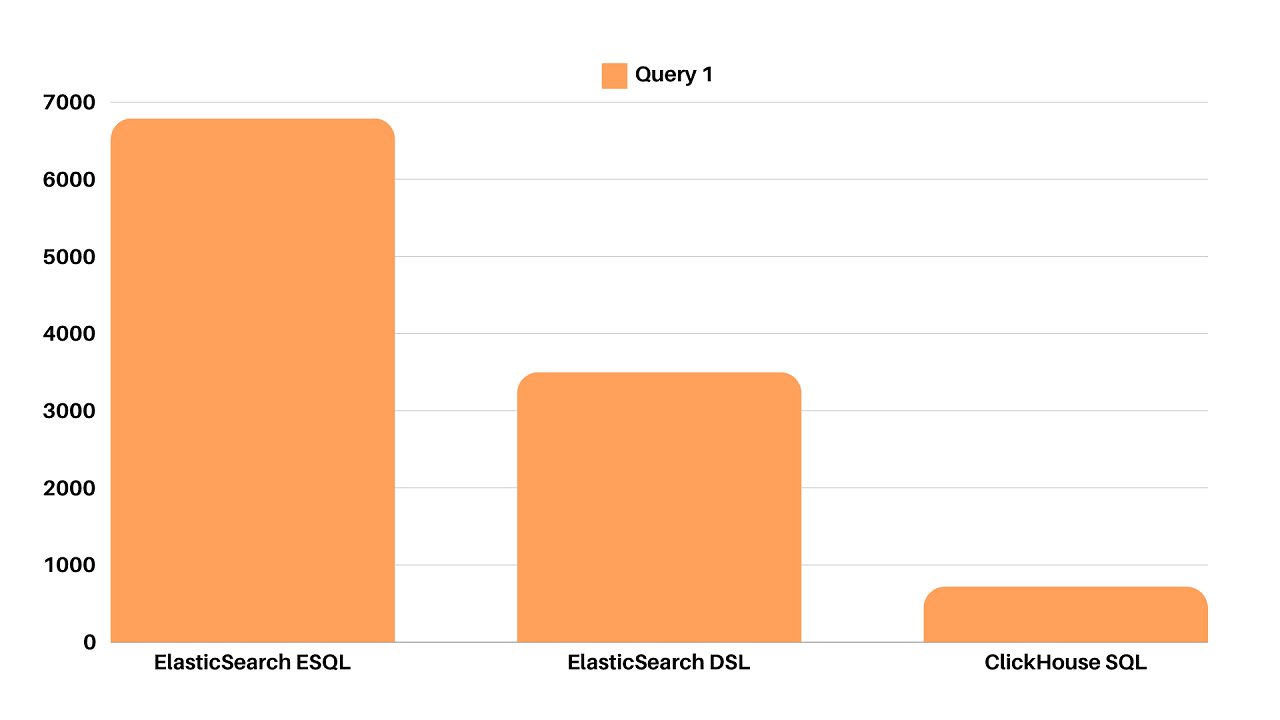
Query performance in ClickHouse blew ES out of the water. Thanks to vectorized execution and parallelized processing, ClickHouse offered ~5x the query speed of ES. This meant that even under heavy loads, ClickHouse maintained stability and responsiveness.
Efficient Storage
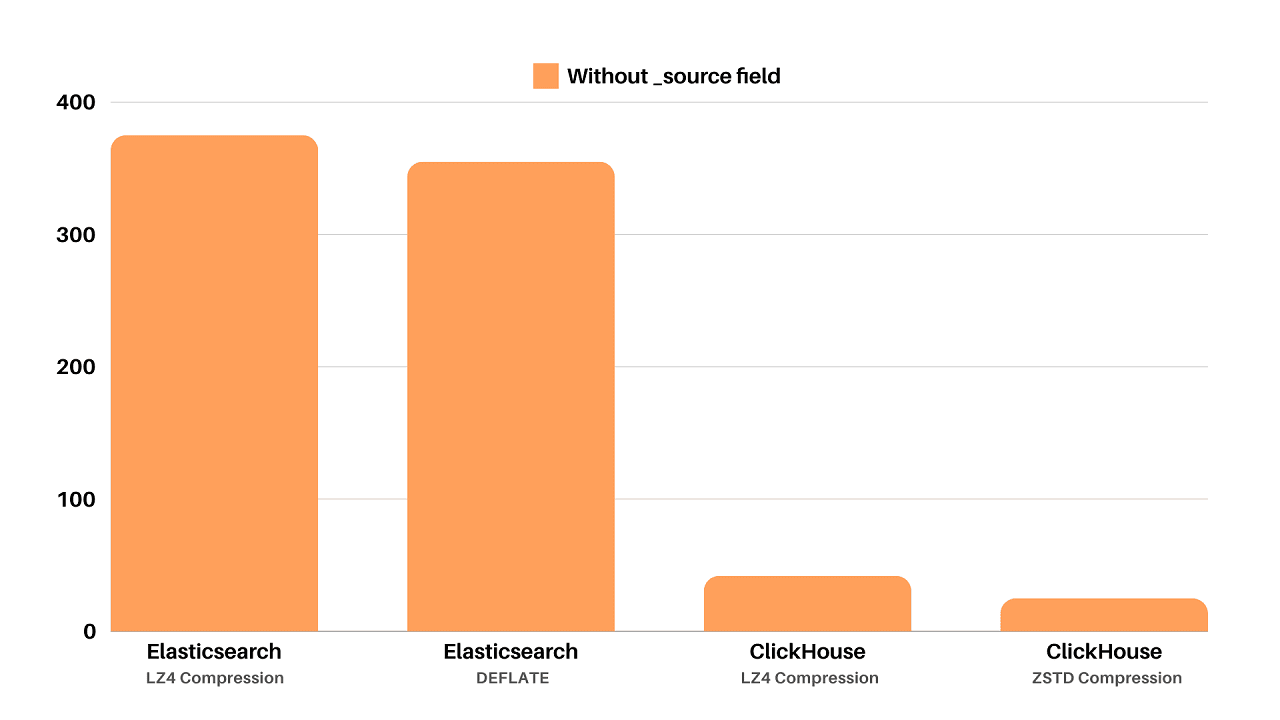
With configurable column-level compression algorithms like LZ4 and ZSTD, ClickHouse allowed Uber to store more data efficiently. This not only sped up disk I/O but also ensured that massive datasets fit comfortably in the filesystem cache.
OLAP vs OLTP: Understanding the Differences
Before we dive deeper into the technical details of Uber’s implementation, it’s essential to understand the difference between OLAP (Online Analytical Processing) and OLTP (Online Transaction Processing). These two types of databases serve different purposes and are optimized for different types of operations.
OLTP (Online Transaction Processing)
OLTP systems like PostgreSQL are optimized for transaction-heavy operations. They are designed to handle a large number of short online transaction requests. These systems are typically used for CRUD (Create, Read, Update, Delete) operations in applications. Here’s an example:
- Scenario: Uber needs to process a new ride request, update the rider’s status, and record the transaction in the database.
- Query: “INSERT INTO rides (rider_id, status, timestamp) VALUES (X, ‘active’, NOW()).”
- Operation: This involves writing a new record and updating the rider’s status quickly. PostgreSQL handles such transactions efficiently, ensuring ACID (Atomicity, Consistency, Isolation, Durability) properties.
-- PostgreSQL Table Structure CREATE TABLE rides ( ride_id SERIAL PRIMARY KEY, rider_id INT NOT NULL, status VARCHAR(20) NOT NULL, timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); -- Example Insert Operation INSERT INTO rides (rider_id, status, timestamp) VALUES (1, 'active', NOW());
OLAP (Online Analytical Processing)
OLAP systems like ClickHouse are designed for high-speed analysis of large datasets. They are optimized for read-heavy operations and complex queries that involve aggregations, joins, and scans of large amounts of data. Here’s an example to illustrate:
- Scenario: Uber wants to analyze ride data to determine the top 5 most frequently accessed API endpoints over the past month.
- Query: “For time range X and services Y, give me the top 5 most frequently accessed endpoints matching filter Z.”
- Operation: This requires scanning large datasets, aggregating data, and returning results. ClickHouse excels at this by using vectorized execution and parallelized processing.
-- ClickHouse Table Structure CREATE TABLE logs ( timestamp DateTime, service String, endpoint String, log_message String ) ENGINE = MergeTree() ORDER BY (service, endpoint, timestamp); -- Example Query SELECT endpoint, COUNT(*) AS hits FROM logs WHERE timestamp >= '2023-06-01' AND timestamp <= '2023-06-30' AND service = 'ride-service' GROUP BY endpoint ORDER BY hits DESC LIMIT 5;
Sample Data in ClickHouse:
| timestamp | service | endpoint | log_message |
| 2023-06-01 00:00:01 | ride-service | /api/v1/ride | Ride requested |
| 2023-06-01 00:00:02 | ride-service | /api/v1/ride | Ride accepted |
| 2023-06-01 00:00:03 | ride-service | /api/v1/payment | Payment processed |
| 2023-06-01 00:00:04 | ride-service | /api/v1/ride | Ride completed |
| 2023-06-01 00:00:05 | support-service | /api/v1/support | Support ticket created |
Result of the Query:
| endpoint | hits |
| /api/v1/ride | 1500 |
| /api/v1/login | 1200 |
| /api/v1/payment | 1100 |
| /api/v1/search | 950 |
| /api/v1/support | 800 |
Building the ClickHouse-Based Logging Architecture
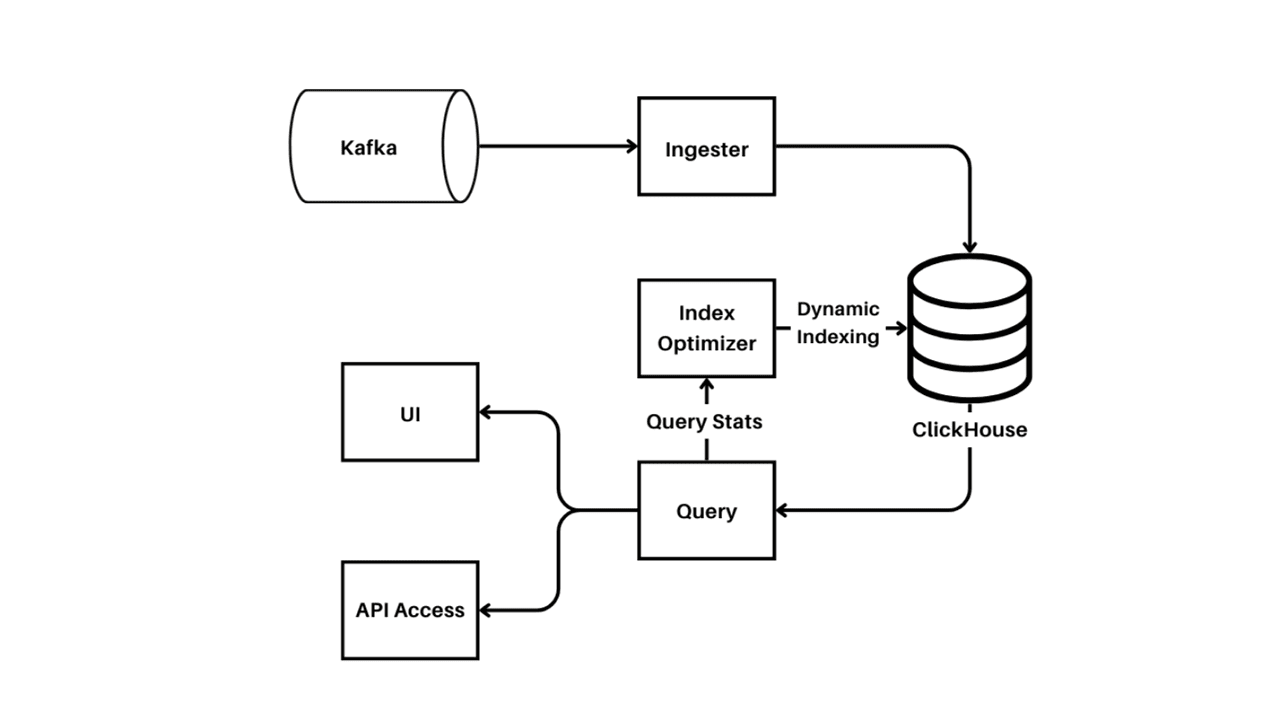
Uber’s transition to a ClickHouse-based logging architecture marked a significant improvement in their ability to handle and analyze massive volumes of log data efficiently. Here’s a detailed look at the components and mechanisms that make this architecture work seamlessly.
Ingestion Pipeline
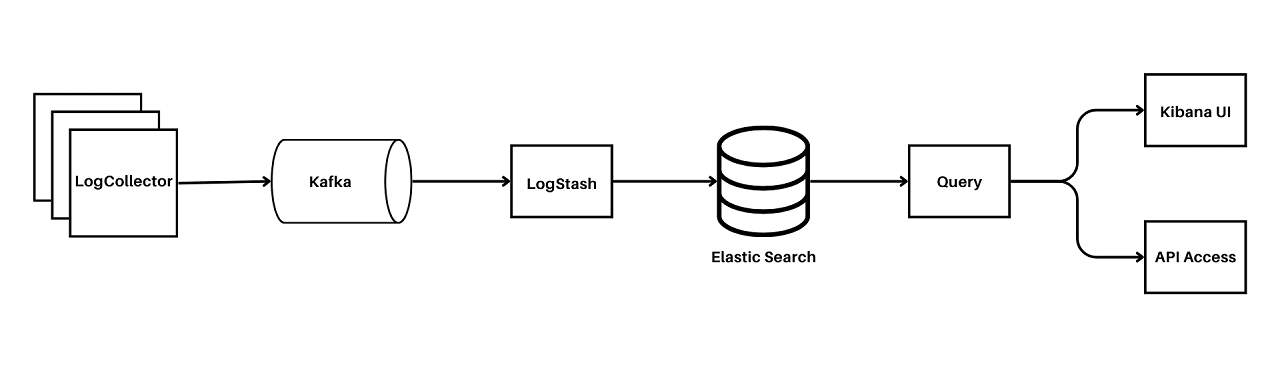
At the core of Uber’s new logging system is the ingestion pipeline. This pipeline is responsible for consuming log events generated by various services and transporting them to ClickHouse for storage and analysis. Here’s how it works:
- Log Collection with Kafka: Uber uses Kafka, a high-throughput, low-latency platform for handling real-time data feeds, to collect logs from thousands of microservices. Kafka acts as a buffer that ensures a smooth and reliable flow of log data.
- JSON Flattening: Once the log events are collected in Kafka, they often arrive in JSON format. JSON logs are versatile but can be complex and nested. The ingestion pipeline flattens these JSON logs into structured fields, making them easier to process and query later.
- Batch Buffering: The flattened logs are then buffered into large batches. This batching process is crucial as it improves the efficiency of the ingestion process. By handling logs in bulk rather than individually, Uber minimizes the overhead associated with multiple small transactions.
- Routing to ClickHouse Tables: The buffered log batches are routed to the appropriate ClickHouse tables. This step eliminates the need for schema sanitization, as the logs are already structured and ready for ingestion.
This ingestion pipeline ensures that Uber can handle the high volume and velocity of log data generated by its services, making the process efficient and scalable.
Dynamic Indexing
One of the standout features of ClickHouse is its approach to indexing. Unlike traditional databases that require predefined indexes, ClickHouse uses dynamic indexing, which provides several benefits:
- Indexing Strategy: By default, ClickHouse does not index any fields. This ensures high ingestion throughput because the overhead of maintaining indexes is eliminated during the write process.
- Adaptive Indexing: ClickHouse dynamically indexes fields based on query patterns. Since only about 5% of log fields are accessed frequently, ClickHouse focuses on indexing these fields, leading to significantly faster query times without the cost of blind indexing.
- Efficiency Gains: This adaptive strategy means that resources are not wasted on indexing rarely accessed fields, resulting in efficient use of storage and processing power.
Dynamic indexing adapts to the evolving needs of Uber’s engineers, optimizing performance and ensuring that the most relevant data is indexed for fast retrieval.
Materialized Columns and Data Skipping Indices
To further optimize query performance, ClickHouse offers advanced features like materialized columns and data-skipping indices:
- Materialized Columns: These columns are derived from base columns and can be created or dropped at runtime. This flexibility allows Uber to optimize queries on the fly. When a materialized column is created, it is automatically populated with values for new incoming rows and historical data is backfilled asynchronously.
- Performance Boost: Materialized columns can be queried much faster than base columns, often achieving over 10x the scanning speed.
- Example: If a common query involves a specific endpoint, a materialized column can store pre-computed values, drastically reducing query time.
- Data Skipping Indices: These indices are designed to skip over irrelevant data during query execution, significantly speeding up queries.
- Types of Indices: ClickHouse supports various indices such as token-based and n-gram-based bloom filters, and MinMax indices.
- Example: A token-based bloom filter index can quickly match UUIDs, reducing the data scanned and improving query performance by up to 15x compared to when no index is used.
These features enable Uber to handle complex queries efficiently, making the logging system highly responsive and capable of providing quick insights.
Clustering and Scalability
Scalability is a cornerstone of Uber’s logging infrastructure, and ClickHouse’s built-in clustering mechanisms play a vital role in achieving this:
- Uniform Shard Distribution: ClickHouse distributes data evenly across shards, ensuring a balanced load and efficient use of resources.
- Rack-Aware Shard Topology: This topology considers the physical layout of the data centre, reducing cross-rack data transfer and improving performance.
- Multi-Master Replication: ClickHouse supports multi-master replication, where writes are evenly distributed across nodes. This design eliminates single points of failure (SPOF) and ensures high availability and reliability.
- Load Balancing: The uniform distribution of writes and reads across the cluster ensures that no single node becomes a bottleneck, maintaining system performance under high loads.
These clustering features ensure that Uber’s logging system can scale seamlessly to handle growing volumes of data without compromising on performance or reliability.
Query Handling
ClickHouse excels in handling distributed queries efficiently, which is crucial for Uber’s large-scale logging needs:
- Distributed Query Execution: When a query is issued, ClickHouse fans out sub-queries to all relevant shards in the cluster. Each shard processes its part of the query in parallel, and the results are aggregated to produce the final output.
- Resource Management: ClickHouse provides fine-grained control over resource allocation, allowing Uber to prioritize critical queries and ensure that system resources are used optimally.
- Fault Tolerance: ClickHouse can skip over shards with errors or time out slow shards early, ensuring that queries are complete as quickly as possible even in the presence of issues.
This approach to query handling ensures that Uber’s engineers can retrieve the data they need quickly, even for complex analytical queries, without impacting the overall system performance.
Conclusion
Switching to ClickHouse was a game-changer for Uber’s logging infrastructure. It solved the performance, scalability, and cost challenges that plagued their ElasticSearch setup. For anyone dealing with large-scale logging, ClickHouse offers a robust, efficient, and scalable solution.
So next time you’re cruising in an Uber, remember that under the hood, ClickHouse is working tirelessly to ensure that the ride (and the logs) are smooth as butter!
And there you have it, folks! Uber’s secret to handling millions of logs per second. If you’re as excited about scalable architectures as I am, give ClickHouse a spin in your next project. Happy logging!




