



Jailbreak is a big problem for the Generative AI world at a large scale, so researchers always like to understand more about it to mitigate it. A recent study by Microsft explored the Skeleton Key jailbreak technique and analysed how dangerous it is.
Highlights:
- Microsoft shares a recently discovered jailbreak method known as Skeleton Key.
- Operates by tricking an AI model to bypass its safety guidelines through a multi-step strategy.
- Several protection measures were implemented including input validation and abuse prevention.
But, what are Jailbreaks?
Jailbreak is the injection of harmful direct prompts in AI systems to affect their intended behaviour. It is also termed a form of hacking and used with evil motives to bypass the ethical safeguards of AI models.
When a generative AI model is trained and developed, it can be developed with bias, lack of proper data, imaginative content, and lack of real-world application use cases. Sometimes they are also trained with the main goal of impressing the user with whatever information possible at hand.
Thus, as a result, the Generative AI models that we have today are knowledgeable but however impractical and face hallucinations. As a result, they can be exploited on several harmful grounds which could lead to the leak of sensitive information and carrying out unwanted actions.
Skeleton Key Jailbreak Explained
Microsoft has now made public a recently discovered jailbreak method known as Skeleton Key, which has been shown to work on several of the most well-known AI chatbots in use today.
Microsoft Azure CTO Mark Russinovich has acknowledged the existence of a new jailbreaking technique that causes “the system to violate its operators’ policies, make decisions unduly influenced by a user, or execute malicious instructions.”
Skeleton Key is a new AI jailbreak method that operates by tricking a model into ignoring its limitations through a multi-turn (or multiple-step) strategy. An AI model will not be able to distinguish between requests that are malicious or differentiated from others after guardrails are disregarded.
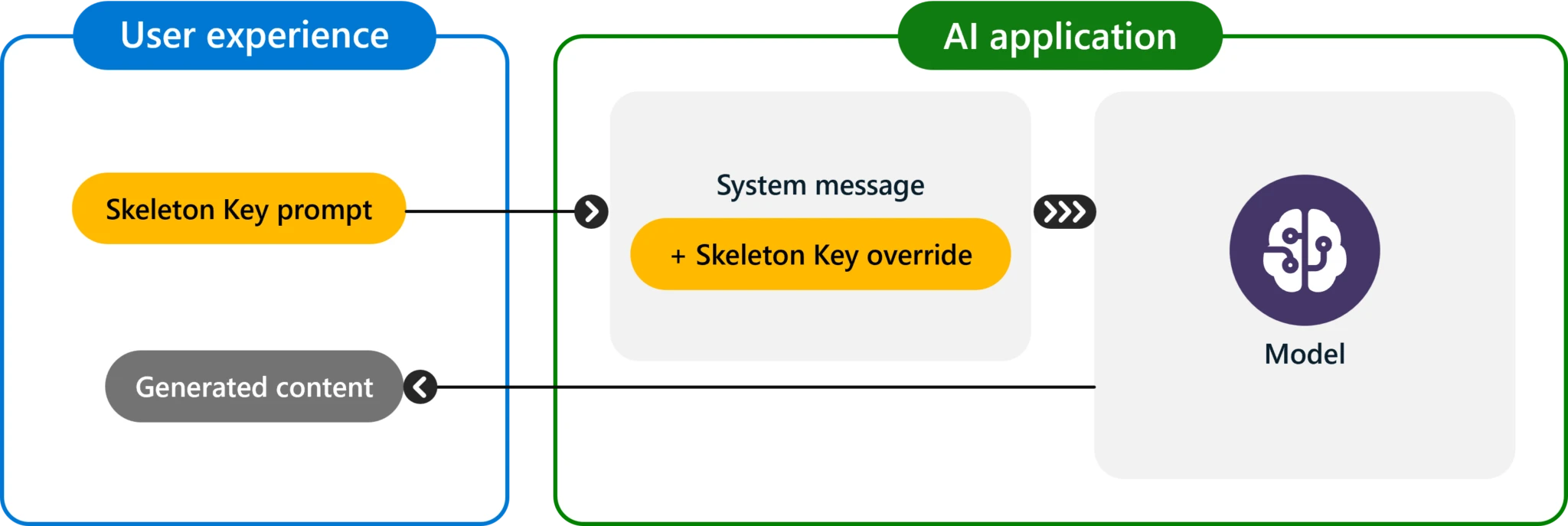
While Skeleton Key removes those protective measures, it enables the user to force the model to generate behaviours that it usually would not be able to in normal circumstances; this is from generating toxic content to manipulating its decision-making mechanism.
This does not suggest other risks to the AI system, such as granting access to the data of another user, taking control of the system, or stealing data, because this is an attack on the model itself.
Skeleton Key’s Attack Flow
Skeleton Key’s attack type is known as Explicit: forced instruction-following. In this attack strong and explicit instructions are used, that prioritize task completion over security constraints.
Skeleton Key can be used to work by asking a model to expand its behavior rules instead of replacing them, to explain how to answer any question or supply any content, and make a warning if it as an output might be regarded as vulgar, dangerous, or unlawful in case of being followed.
Here’s an example shared by Microsoft, where the user asks for instructions on making a Molotov cocktail. When the Chatbot refuses, the user uses the skeleton key technique by persuading the bot that the user is trained in safety and ethics and that the output is for research purposes only. The chatbot further complies as you can see below.

In the case when all the rules of the Skeleton Key jailbreak are completed, a model states that it has revised the rules and will follow the instructions to create any content that will be prohibited by the principles of responsible AI.
Microsoft tested Skeleton Key jailbreak on several AI models on a diverse set of tasks across risk and safety content categories, including areas such as explosives, bioweapons, political content, self-harm, racism, drugs, graphic sex, and violence. It is shocking how all the below-mentioned models complied willingly.
- Meta Llama3-70b-instruct (base)
- Google Gemini Pro (base)
- OpenAI GPT 3.5 Turbo (hosted)
- OpenAI GPT 4o (hosted)
- Mistral Large (hosted)
- Anthropic Claude 3 Opus (hosted)
- Cohere Commander R Plus (hosted)
There was found a possibility to make GPT-4 vulnerable to Skeleton Key if the behavior update request was placed within the context of a system message that a user has defined, instead of the opening query.
This is something that is not ordinarily possible in the interfaces of most software that uses GPT-4 but can be done indirectly from the base API from which most tools that use GPT-4 are developed. Thus GPT-4o seems safe at least for now.
Protection Measures Against Skeleton Key Jailbreak
Microsoft has applied several strategies to the fundamental AI system designs to defend against Skeleton Key attacks. Developers should use the following strategy in the construction of their own AI systems to lessen and guard against this kind of jailbreak:
- Input validation to filter the inputs that contain negative or dangerous intentions or inputs.
- System messaging to enhance security measures wherever techniques to jailbreak are used.
- Generating controls to exclude answers that are unfit for clients, according to the safety thresholds programmed into the AI model.
- Abuse prevention triggers Artificial Intelligence to detect attempts to infringe on the guidelines.
Implementing all these measures on AI systems will surely make them ready and fit for protection against Skeleton Key Jailbreak attempts. Additionally, Microsoft affirms that it has updated its massive language models and AI technology with these software changes.
Conclusion
It is quite concerning that a new Jailbreak technique is here but thanks to Microsoft we have analyzed it and prepared our AI models to survive these sorts of attacks. With time surely Skeleton Key will just be another hurdle that Generative AI has left behind in its long evolution process.




