


Meta has recently been quite on the roll in the race for Generative AI models. Now they have launched LLM Compiler, a powerful collection of Generative AI models that many believe have the potential to transform the coding experience for developers forever. Today, we will look into the newly launched Meta’s LLM Compiler model and analyze its powerful capabilities.
Highlights:
- The Meta Large Language Model (LLM) Compiler is a set of open-source models with better compiler design and code optimization.
- Trained the model to understand compiler intermediate representations, assembly language, and optimization strategies by using a vast corpus of 546 billion tokens of LLVM-IR and assembly code.
- The results show LLM Compiler does better than current models when it comes to Code Optimization and Software Development tasks.
Meta’s LLM Compiler Models
Meta has released Large Language Model (LLM) Compiler to revolutionize compiler design and code optimization
Today we’re announcing Meta LLM Compiler, a family of models built on Meta Code Llama with additional code optimization and compiler capabilities. These models can emulate the compiler, predict optimal passes for code size, and disassemble code. They can be fine-tuned for new… pic.twitter.com/GFDZDbZ1VF
— AI at Meta (@AIatMeta) June 27, 2024
The LLM Compiler researchers have filled a long-standing, largely unaddressed gap in the field of applying massive language models to compiler and code optimization.
“Training LLMs are resource-intensive, requiring substantial GPU hours and extensive data collection, which can be prohibitive. To address this gap, we introduce Meta Large Language Model Compiler (LLM Compiler), a suite of robust, openly available, pre-trained models specifically designed for code optimization tasks.”
Chris Cummins, one of the core contributors to the project, on Meta AI’s Research Paper.
Compiler optimization is the goal of LLM Compiler models. There are two model sizes available: 7B and 13B parameters. The LLM Compiler models are trained on an additional 546B tokens of data, primarily consisting of assembly code and compiler intermediate representations, after being initialized with Code Llama model weights of comparable size.
Since LLM Compiler models are already trained to mimic the compiler and comprehend the semantics of compiler IRs and assemblies, fine-tuning with little input is possible for certain downstream compiler optimization tasks. The researchers expanded Code Llama’s functionality to include reasoning and compiler optimization.
How can you Access them?
Both LLM Compiler 7B & 13B models have been released under a permissive license for both research and commercial use in the hopes of making it easier for developers and researchers alike to leverage this in their work and carry forward new research in this space.
You can access all the model weights on Hugging Face. So go try them out today!
LLM Compiler’s Potential to Transform Coding and Software Development
The effects of this technology are extensive. Faster compile times, more effective code, and new tools for deciphering and improving complicated systems could all be advantageous to software engineers. New possibilities for investigating AI-driven compiler optimizations are opened up for researchers, which could result in advancements in software development methodologies.
However, the availability of such potent AI models begs concerns about how software development is evolving. Future software engineers and compiler designers may need different talents as AI grows more proficient at handling complicated programming jobs.
The Model Training
It’s very crucial to understand the data training process that went into the build of Meta’s LLM compiler models, in order to understand its capabilities surrounding code optimization and compiling.
Python and other high-level source languages often make up the majority of the data utilized to train coding LLMs.Compiler IRs and assembly code together make up a very small fraction of these collections.
The researchers initialize LLM Compiler models using Code Llama weights to create an LLM with a strong grasp of these languages. They then train the models for 401 billion tokens using a compiler-centric dataset that primarily consists of assembly code and compiler IRs.
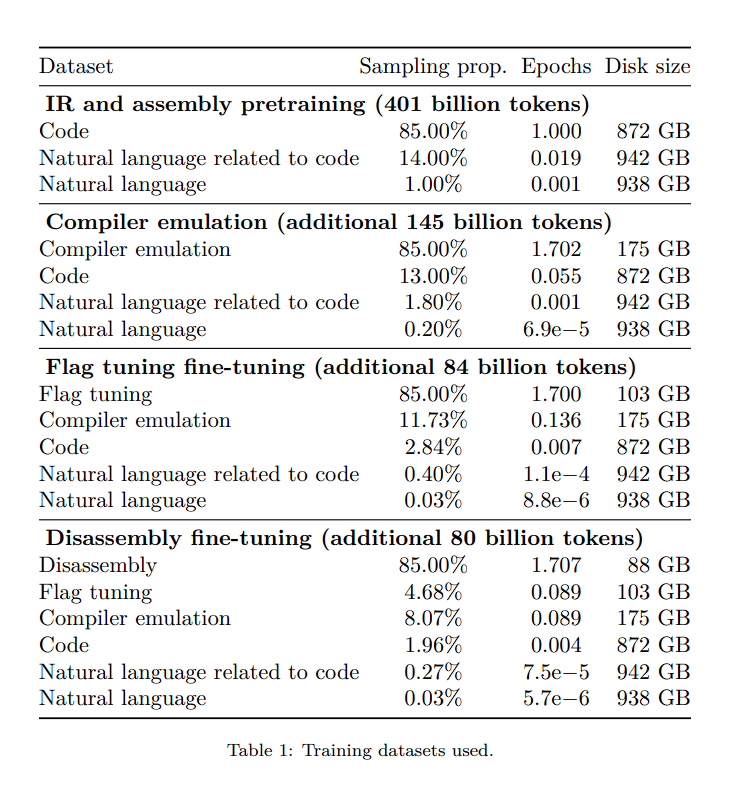
Through two steps of training on 546 billion tokens of compiler-centric data, LLM Compiler models are specialized from Code Llama.
During the initial phase, the models are mostly trained using assembly code and unlabeled compiler input regions. To improve reasoning about code optimization, the researchers augment Code Llama with additional pretraining on a substantial corpus of assembly programs and compiler IRs, followed by instruction fine-tuning on a custom compiler emulation dataset.
The models are instructed to be fine-tuned to forecast the outcome and impact of optimizations in the subsequent stage. The downstream flag tuning and disassembly task datasets contain 164 billion tokens, for a total of 710 billion training tokens, which are used to further refine the LLM Compiler FTD models. Fifteen percent of the data from the earlier tasks is kept in each of the four training phases.
To help maintain the capabilities of the fundamental Code Llama model, a tiny quantity of code and natural language data from earlier stages are employed at every round of training.
Looking into the Working Approach
Considering a segment of LLVM assembly and a series of optimization passes for opt, the LLVM optimizer, LLM Compiler can forecast the code size change and the final output code once these optimizations are applied. It can frequently recreate the optimising compiler’s output exactly since it has “understood” its behaviour to such an extent. Because of these features, it is perfect for jobs involving compiler optimization.

Apart from this basic capability, LLM Compiler has been optimized for two distinct downstream tasks to showcase its proficiency in solving complex compiler optimization issues:
Predicting the best optimization passes for opt to use in order to minimize code size, given a piece of LLVM assembly code.

Generating LLVM IR from a piece of x86_64 or ARM assembly code.

What did the Results show?
LLM Compiler optimizes code size with impressive results. In experiments, the model was able to optimize up to 77% of an autotuning search’s potential, which might lead to much faster compilation times and more efficient code in a variety of applications.
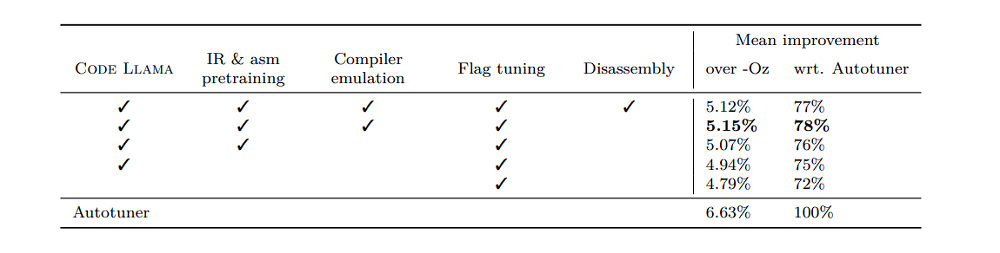
Even more astounding is the model’s disassembling capabilities. In round-trip disassembly, LLM Compiler showed a 45% success rate (with 14% precise matches) while transforming x86_64 and ARM assembly back into LLVM-IR. This skill could come in very handy for maintaining legacy code and doing reverse engineering activities.
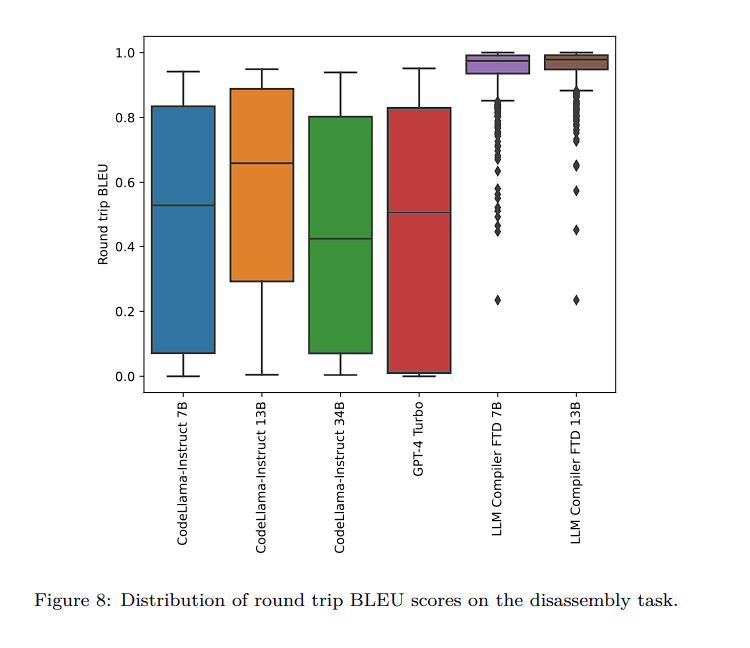
The LLM Compiler models also did well in a variety of software engineering tasks such as generating Python code from natural language prompts, such as “Write a function to find the longest chain which can be formed from the given set of pairs.”. It surpasses Llama 2 models on HumanEval and MBPP evaluation benchmarks.
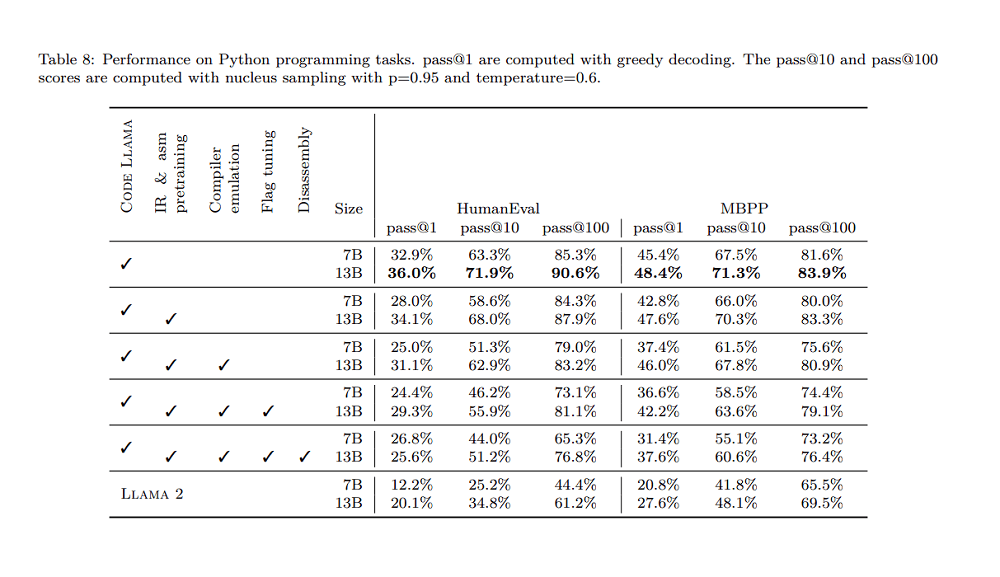
Overall, the results show that LLM compiler models do well in contrast to models like GPT-4 Turbo and Code Llama Instruct. It outshines these models in several tasks such as Flag-tuning, disassembly, and software engineering tasks.
Are there any Limitations?
From the results, it is clear that Meta’s LLM Compiler family of models does well on compiler optimization tasks and understands compiler representations and assembly code better than current models. However, it comes with a few limitations.
The finite sequence length of the inputs (context window) is the primary constraint. Program codes and snippets may be far longer than the 16k token context window that the LLM Compiler provides.
To mitigate this, the researchers divided up the larger translation units into separate functions. However, this reduces the amount of optimization that can be done, and 18% of the divided translation units are still too big for the model to accept as input.
The correctness of model outputs is a second restriction that applies to all LLMs. The LLM Compiler users have been instructed by the researchers to evaluate their models using compiler-specific evaluation benchmarks.
Any recommended compiler optimizations need to be thoroughly checked because compilers are not error-free. The accuracy of a model’s decompiled assembly code should be verified by manual examination, round-trip testing, or unit testing.
Conclusion
Meta’s LLM Compiler models are a significant advancement towards having AI models that can improve code optimization and feed the programs into several Machine Learning algorithms in a more complete manner, without losing much information. It does better than the current models, at least in these specific tasks.




